
[XAI] LIME(Local Interpretable Model-agnostic Explanation) 알고리즘
blackbox 모델을 지역적으로 근사함으로써 설명 가능성을 제공하는 LIME 알고리즘에 대해 살펴봅니다.

1. LIME은 model agnostic한 XAI 알고리즘으로, 모델의 종류와 무관하게 적용 가능
2. tabular 데이터 뿐만 아니라 이미지, 자연어 등 다양한 데이터 타입을 받아들임
3. 모델의 지역적인 결정경계에 선형 모델과 같은 glassbox 알고리즘을 학습시킴. 이 모델을 대리 모델(surrogate model)이라고 하는데, 이 대리 모델의 계수를 사용해 설명 가능성 제공
Contents
EBM알고리즘을 설명하는 포스트에서도 잠시 다뤘듯이, 모델의 설명가능성은 머신러닝 모델을 현업에 적용하는 데 매우 중요한 요소입니다. 단순히 모델의 판단을 이해하는 데 그치지 않고, 모델을 디버깅하거나 모델의 취약점을 분석하는 작업, 모델의 편향된 판단을 바로잡는 등 우리가 마주할 수 있는 많은 문제의 실마리를 설명가능성이 쥐고 있습니다.
오늘은 XAI 알고리즘에서 가장 각광받는 접근법 중 하나인 LIME(Local Interpretable Model-agnostic Explanation)에 대해 알아보겠습니다.
대리 분석(surrogate analysis)이란?
XAI에서 대리 분석이란, 설명하고자 하는 원래 모델이 지나치게 복잡해서 해석하기 어려울 때, 해석 가능한 대리 모델(surrogate model)을 사용하여 기존의 모델을 해석하는 기법을 말합니다. 가령 SVM 분류기와 같이 성능은 좋지만 해석이 어려운 모델이 있을 때 Logistic regression 모델처럼 설명 가능성은 높지만 성능은 낮은 모델을 대리 모델로 사용해 해당 모델의 계수를 기반으로 모델의 판단 메커니즘을 어림짐작하는 것입니다. 물론 이 과정에서 성능의 손실도 발생하며, 엄밀한 의미에서 SVM의 학습 메커니즘과 Logistic regression의 그것이 다르기 때문에 발생하는 차이가 있겠으나 모델 학습에 중요한 변수는 어떤 모델을 쓰나 중요하게 쓰일 것이라는 직관은 받아들이기는 힘들지 않을 것 같습니다.
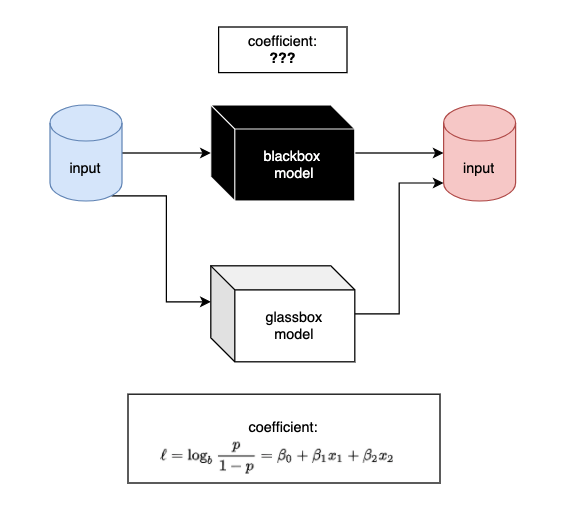
대리 분석 방법은 모델 어그노스틱(model-agnostic)하다는 점에서 매우 유용합니다. 머신러닝 분야에서 agnostic하다는 말은 “~에 상관없이”라고 이해하면 좋을 듯 합니다. 모델 어그노스틱은 그러므로 “모델에 상관없이 적용가능한” 특성을 말합니다.
앞서 예시를 들어 보여드린 방법은 전체 학습 데이터를 모두 사용해 대상 모델을 대신 설명하는 전역적인(global) 대리분석 방법입니다. 그렇다면, 단일 샘플에 대해서만 해석을 제공하는 대리 분석 방법도 있을까요? 그게 바로 LIME입니다.
LIME 알고리즘이란?
모델의 중요 변수와 같은 전역적인 관점에서의 설명이 필요할 때도 있지만, 지역적인 설명은 비즈니스 상황에서 더욱 중요한 경우가 많습니다. 가령, 채무 불이행(default) 여부를 예측하는 모델의 결과에 따라 대출을 승인할지 말지 판단하는 은행의 상황을 생각해봅시다. 모델에게서 채무 불이행할 가능성이 높다는 판단을 받아 대출을 거절당한다면, 고객의 입장에서는 매우 불합리하게 느껴질수도 있고, 공평성에 의문을 제기할수도 있을 것입니다. 이 때 “당신의 연체율이 10%고, 연 소득이 1,000만원 미만인 점이 중요하게 작용했습니다.” 하는 식으로 설명을 제공한다면 아마도 고객은 부당함을 주장하기 어렵겠지요.
다른 사례로, 1년 내 뇌졸중의 발병 여부를 예측하는 문제를 생각해 봅시다. 만일 “당신은 모델의 판정에서 양성이 나왔어요. 1년 내 뇌졸중이 발병할 가능성이 크다는 거죠. 그런데, BMI 지수를 24로 떨어뜨리니 모델이 음성으로 판정했습니다. 살을 좀 빼시면 건강을 더 오래 유지하실 수 있겠습니다.” 하는 설명을 제공해 준다면, 단순히 모델의 결과를 보여주는 것 이상으로 더욱 실용적인 해결책을 얻을 수 있을 것 같습니다.
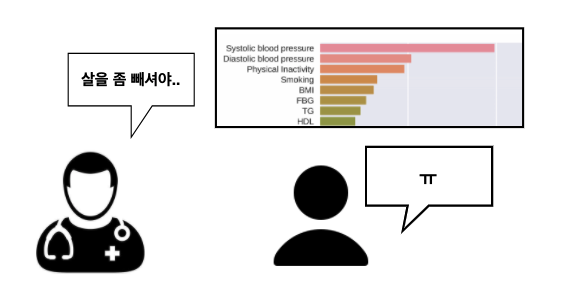
이러한 지역적인 설명에 대한 갈증을 해소해 주는 것이 바로 LIME입니다. LIME이 무엇을 의미하는지, 풀네임인 “Local Interpretable Model-agnostic Explanation”을 하나 하나 짚어보겠습니다.
- Interpretable Explanation은 각 예측을 내림에 있어 어떤 피처가 사용되었는지에 대한 설명을 제공한다는 의미 입니다.
- Model-agnostic은, 앞서 설명했듯 어떤 블랙박스 모델을 사용하든지 간에 무관하게 사용할 수 있음을 나타냅니다. LIME을 적용한다는 것은 어느 블랙박스 모델에든 매우 해석 가능성이 좋은 선형회귀 모델을 적용한다는 것 이라고 저자는 설명합니다.
- Local은 observation specific하다는 것을 의미합니다. 위의 대출 사례와 뇌졸중 사례처럼 한 개인, 혹은 한 샘플에 내려진 판단이 어떻게 내려진 것인지를 분석합니다. Lime은 전체적인 모델의 예측에 대해 분석하지 않습니다. 반대로, 매우 작은 부분, 즉 샘플 하나 혹은 특징이 비슷한 같은 클래스의 샘플 그룹만을 분석합니다. 샘플 하나만을 볼 경우, 해당 상황은 매우 local해지므로 linear regression을 적용할 수 있게 될 것입니다. 그렇게 되면 그 로컬한 수준에서 매우 정확할 것이라는 것이, LIME 알고리즘의 접근입니다.
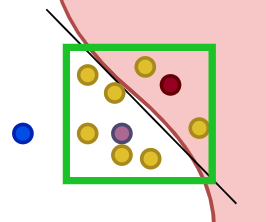
다음과 같은 매우 독특한 형태의 결정경계가 있다고 해봅시다.
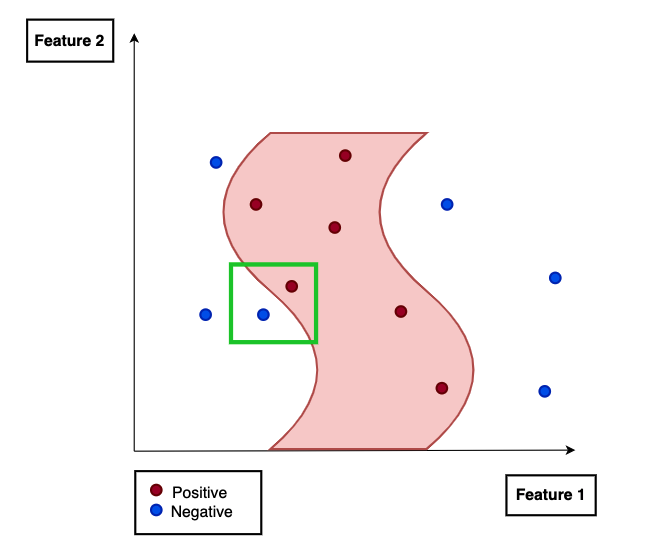
여기서 우리는 왼쪽 하단의 녹색 박스 안을 “local하게” 집중해서 보겠습니다.
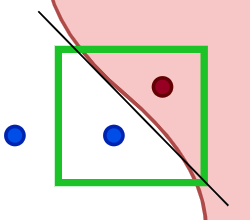
이 결정경계 가운데에 지역적인 선형회귀 모델(검정색 선)을 적합해서, 이 회귀식의 계수를 사용해 모델의 판단 메커니즘을 분석하는 것이 바로 LIME의 아이디어라고 할 수 있겠습니다. 우리의 예시는 분류 문제이므로 엄밀히는 직선의 모델을 적합하는 것은 아니지만 로지스틱 회귀 모형을 통해 선형의 결정경계를 갖게 됩니다.
LIME의 작동 원리
LIME 알고리즘의 학습 순서는 다음과 같습니다.
1) permute data: 각 observation에 대해, 피처 값을 permute하여 새로운 fake dataset을 만듭니다.
2) calculate distance between permutation and original observation: 위에서 생성한 fake data와 original data의 distance(즉, similarity score)를 계산하여, 원래 데이터와 새로 만든 데이터가 얼마나 다른가를 측 정합니다. (이를 나중에 weight로 사용)
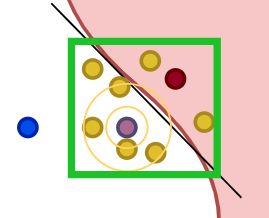
3) make prediction on new data using complex model: 블랙박스 모델을 사용해 생성한 데이터의 라벨을 예측합니다.
4) pick m features best describing the complex model outcome from the permuted data: 블랙박스 모델의 결과로 나온 클래스의 likelihood를 maximize하는, 최소한의 피처 m개를 찾아 냅니다. 이 과정은 매우 중요한데, 수백 개의 피처를 사용해 예측을 수행할 경우에도 몇 개의 중요한 피처만을 남겨낼 수 있기 때문입니다. 이 몇 개의 피처들은 예측을 도출해내기 위해 필요한 정보가 가장 많은(informative) 피처라고 생각할 수 있습니다.
5) Fit a simple model to the permuted data with m features and similarity scores as weights: m개의 피처들을 뽑아서, 생성한 데이터에 설명 가능한 linear model과 같은 알고리즘으로 학습하고, 가중치와 기울기를 구합니다. 2)에서 구한 유사도를 weight로 사용하여 모델을 fitting합니다.
6) Feature weights from the simple model make explanation for the complex models local behavior: 여기서 구한 모델의 기울기(coef)는 local scale에서 해당 observation에 대한 설명이 됩니다.
(여기서 1,2,4,5는 사용자가 customize해서 optimal한 explanation을 얻을 수 있는 부분입니다. 얼마나 permute할지, 어떤 유사도 측도를 쓸지, m의 수를 몇개로 할 지 등.)
손실함수
\[\xi(x) = \underset{g \in G}{\operatorname{\arg min}} L(f, g, \pi_x ) + \Omega(g)\]- 여기서 $G$는 설명가능한 glassbox 모델의 집합을 의미합니다.
- 따라서 $g$는 하나의 glassbox 모델로 생각할 수 있습니다.
- $f$는 우리가 해석하고자 하는 복잡한 모델을 의미합니다.
- $\pi_x$는 우리가 생성해낸 임의의 샘플 $x’$가 원래 분석 대상인 샘플 $x$와 얼마나 먼지를 계산한 유사도 측도입니다.
- $\Omega(g)$는 적합된 회귀계수를 단순하게 유지하고자 적용하는 정규화 텀입니다. 최대한 회귀계수가 0이 되도록 유도하는 압력을 가합니다. 20차원의 피처 공간에서 20개의 회귀계수를 갖는다면 단순한 선형회귀 모형이라 할지라도 사람이 직관적으로 해석하기 어려워질테니까요. LASSO 회귀의 정규화 방식을 떠올리면 쉽게 이해할 수 있습니다.
- 요컨대 $L(f, g, \pi_x )$ 파트는 지역적인 scope에서의 좋은 linear regression 모델을 적합하고자 작용하는 텀이고, $\Omega(g)$ 파트는 모델이 너무 복잡해져 해석이 어려워지는 것을 방지하고자 하는 정규화텀입니다.
이와 같은 손실함수로 대리 함수를 적합하고, 그 결과를 사용해 모델이 개별 샘플에 대해 왜 그러한 판단을 내렸는지를 유추해볼 수 있습니다.
지역적으로 선형적이라는 가정을 적용하기 때문에 매우 직관적으로 사용할 수 있는 알고리즘입니다. 이러한 접근의 한계를 비선형성을 도입함으로써 해결하고자 한 LEMNA라는 알고리즘도 존재합니다.
예제 코드
여기서 코드를 한번 들여다 보지 않고 넘어가면 서운하겠죠. 뇌졸중 데이터셋으로 예제를 만들고 싶었지만, 꿩 대신 닭으로 sklearn 패키지에서 쉽게 가져다 쓸 수 있는 유방암 예측 문제를 풀어보겠습니다.
%pylab inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train,X_test,y_train,y_test = train_test_split(cancer.data,cancer.target)
model = RandomForestClassifier()
model.fit(X_train,y_train)
score = model.score(X_test,y_test)
print(score)
0.9440559440559441
간단한 모델로 높은 성능을 기록했습니다. 이제 한 샘플의 관점에서 모델을 해석해 봅시다. lime 패키지는 단순히 pip install lime 명령어로 설치가 가능합니다.
from lime import lime_tabular
explainer = lime_tabular.LimeTabularExplainer(X_train, mode="classification", feature_names= cancer.feature_names)
idx = random.randint(1, len(X_test))
print("Prediction : ", model.predict(X_test[idx].reshape(1,-1)))
print("Actual : ", y_test[idx])
explanation = explainer.explain_instance(X_test[idx], model.predict_proba, num_features=len(cancer.feature_names), labels=(0,) ,num_samples=5000)
여기서 model.predict가 아닌 model.predict_proba로 넣어주어야 합니다.
(NotImplementedError: LIME does not currently support classifier models without probability scores 에러 발생)
explanation.show_in_notebook()
결과를 살펴보겠습니다.
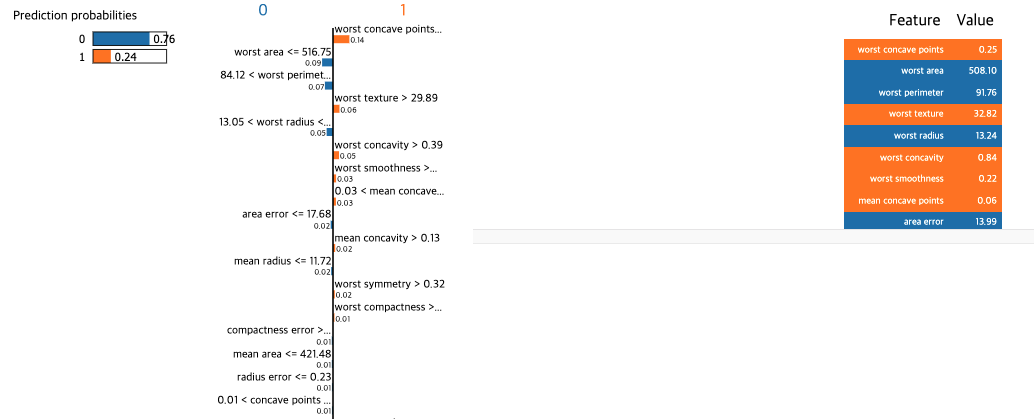
모델의 예측 결과는 0.76이 음성, 0.24가 양성이며 모델은 종합적으로 음성이라고 판단을 내렸습니다. 실제 값 역시 음성입니다. 그림에서 주황색으로 표시된 부분은 양성으로 판단 내리기에 기여한 특성, 그리고 그 기여도를 의미하며, 그 반대는 음성에 기여한 특성과 그 정도를 의미합니다. 모든 기여도의 총합을 통틀어 최종 출력값을 만드는 구조입니다.
마치며
이번 포스트에서는 LIME에 대해 알아보았습니다. XAI 알고리즘의 큰 획을 그은 LIME에 견줄 수 있는 SHAP 알고리즘을 다음 시간에 다뤄보려 합니다.
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요.
내용에 대한 지적, 혹은 질문을 환영합니다.
참고: 유튜브 영상, 논문, XAI, 인공지능을 해부하다
Leave a comment