
[XAI] EBM(Explainable Boosting Machine) 알고리즘 소개
모델 성능과 설명 가능성, 두가지 토끼를 한번에 잡은 glass box 모델인 EBM을 알아봅니다.
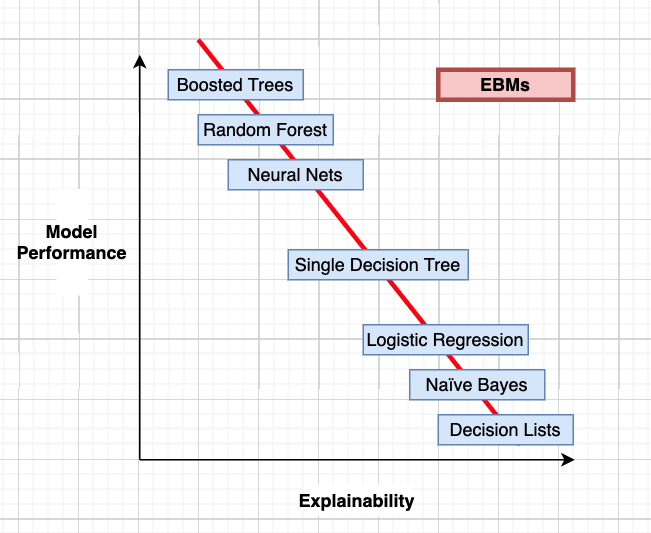
1. EBM은 모델 성능과 설명 가능성 사이에 존재하는 trade-off를 극복하는 트리 기반 glass model
2. 설명 가능성과 동시에 부스팅 알고리즘 수준의 성능을 보임
3. 각 feature별로 개별 트리를 학습, 매우 작은 learning rate으로 5,000-10,000회의 iteration에 걸쳐 모델 구성
Contents
바야흐로 디지털 시대, 머신러닝 알고리즘이 실제 업계에 적용되는 사례가 심심찮게 들려오고 있습니다. 그 때마다 현업은 이 모델이 불안하고, 머신러닝 엔지니어는 답답합니다.
현업: 이 모델 이거 왜 잘되는 거예요?
엔지니어: 아, 이게 요즘 캐글에서 잘나가는 XGBoost라는 모델인데요. 작은 의사결정 나무를 어쩌고 저쩌고..
현업: 그럼 왜 이런 값이 나오는 건지 알 수 있는거네요?
엔지니어: 그렇지는 않아요. 수많은 작은 트리가 굉장히 복잡한 규칙을 각각 학습하는 형태라 그 속을 까보기는 어렵습니다.
현업: 모델이 어떻게 판단하는지 모르는데, 어떻게 믿어요?
엔지니어: 설명이 잘 되는 모델을 쓰려면 굉장히 단순한 모델을 써야해요. 그러면 이 정도 성능은 꿈도 못 꿉니다.
현업: 방법을 찾아봐요. 심플하면서도 세련되게, 저렴하면서도 고급스럽게, 설명 잘 되면서도 성능 좋게!
엔지니어: ㅎㅎ..
Performance와 Explainability 사이의 trade-off
위의 대화처럼, 최근 사용되는 머신러닝 알고리즘은 설명이 잘 되지 않는다는 이유로 현업의 무수한 챌린지를 받습니다. 모델의 성능만이 제 1 목적인 경우가 아니라면, 잘 굴러가는 비즈니스 로직에 녹아들어가기 위해서는 모델이 왜 이런 판단이 내렸는지에 대한 투명한 설명이 필요합니다.
안타깝게도 모델의 성능과 설명 가능성 사이에는 역의 상관관계가 있습니다. 극단적인 예로는 부스팅, 뉴럴넷의 경우 이들이 어떤 판단을 내렸는지 인간이 이해할 수 있는 형태로 제공하지 않습니다. 그럴 때마다 변수 중요도나 shap, LIME과 같은 간접적인 방법을 통해 모델의 판단 로직을 유추해 볼 수 있을 뿐이죠.
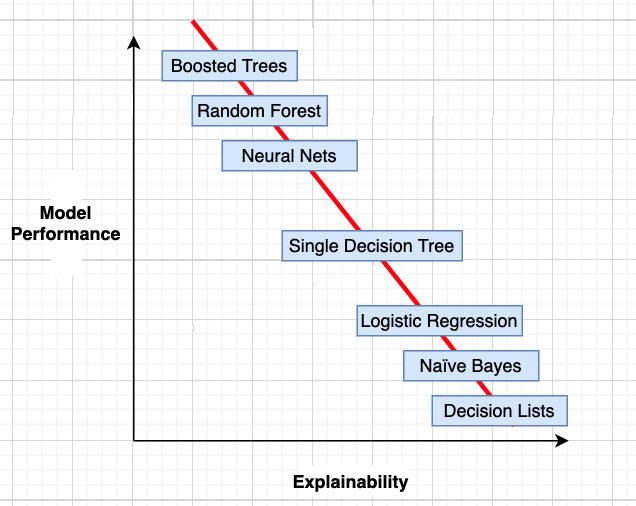
그런데 여기서, Microsoft가 대단한 것을 가지고 옵니다. 바로 EBM입니다.
EBM이란
EBM(Explainable Boosting Machine)은 Microsoft가 공개한 InterpretML 프레임워크와 함께 공개된 설명 가능한 알고리즘입니다. Microsoft가 shap, LIME의 창시자를 영입하는 것과 더불어 InterpretML 프로젝트를 진행하는 등의 행보를 보면 XAI에 특히 큰 관심을 기울이는 것 같습니다.
EBM은 glassbox model로, 직접적인 해석이 불가능한 blackbox model과는 반대되는 개념입니다. 많은 분들이 애용하는 Random Forest, Boosting model 등 SOTA 알고리즘과 비슷한(때로는 월등한) 성능을 보이면서도 매우 높은 설명 가능성을 가진다고 저자들은 InterpretML 논문에서 소개하고 있습니다. 실제 샘플 데이터를 사용해본 결과, 기존에 사용하던 LGBM, XGB와 같은 알고리즘과 큰 차이가 없거나 오히려 더 좋은 성능을 보이는 것을 확인할 수 있었습니다.
모델의 수식은 다음과 같습니다. EBM은 Generalized Additive Model(GAM)의 한 형태로 볼 수 있습니다.
\[g(E[y]) = \beta_0 + \sum f_j(x_j)\]여기서 $g$는 회귀 혹은 분류 문제 등의 상황에 GAM을 알맞게 변형해 주는 link function으로 볼 수 있습니다. 기본적으로 전통적인 GAM (Hastie and Tibshirani, 1987) 알고리즘의 방식을 따르지만, 몇 가지 개선점을 반영하였습니다.
먼저, EBM은 각각의 피처 함수 $f_j$ 를 bagging, gradient boosting을 활용해 학습합니다. 두번째로, EBM은 쌍별 상호작용 (pairwise interaction)을 자동적으로 감지하고 포함하는데, 포함된 형태는 아래와 같은 수식으로 나타낼 수 있겠습니다. 이러한 기능을 통해 정확도를 향상시킴과 동시에 설명가능성을 보장할 수 있습니다.
\[g(E[y]) = \beta_0 + \sum f_j(x_j) + \sum f_{i_j}(x_i,x_j)\]EBM의 학습 방식
먼저, 여느 부스팅 모델과 같이 작은 하나의 트리부터 시작합니다. 그런데 다른 점은, 하나의 피처에 대해서만 트리를 적합한다는 점입니다.
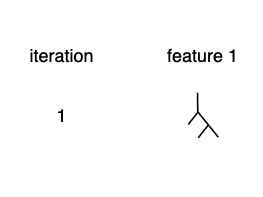
아주 작은 learning rate(학습률)로 학습함으로써, 한 피처에 과적합 되는 것을 방지합니다. 이제 두번째 트리로 residual을 전달합니다. 이 방식은 역시 부스팅 모델의 방식과 동일합니다.
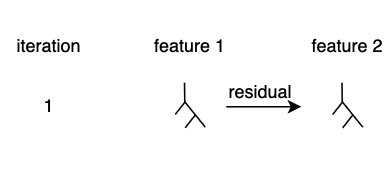
이러한 방식으로 모든 피처에 대해 에러를 전달하고, 한 번의 이터레이션이 끝납니다.
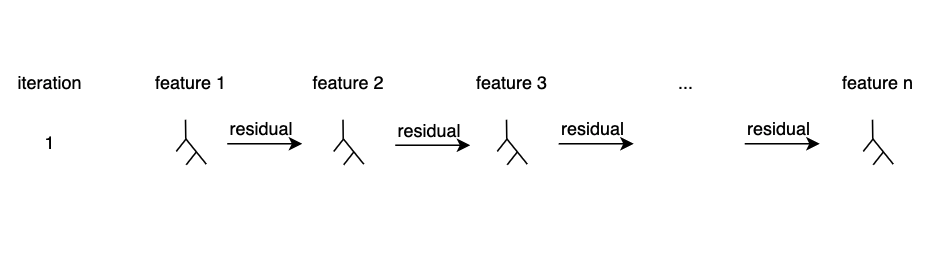
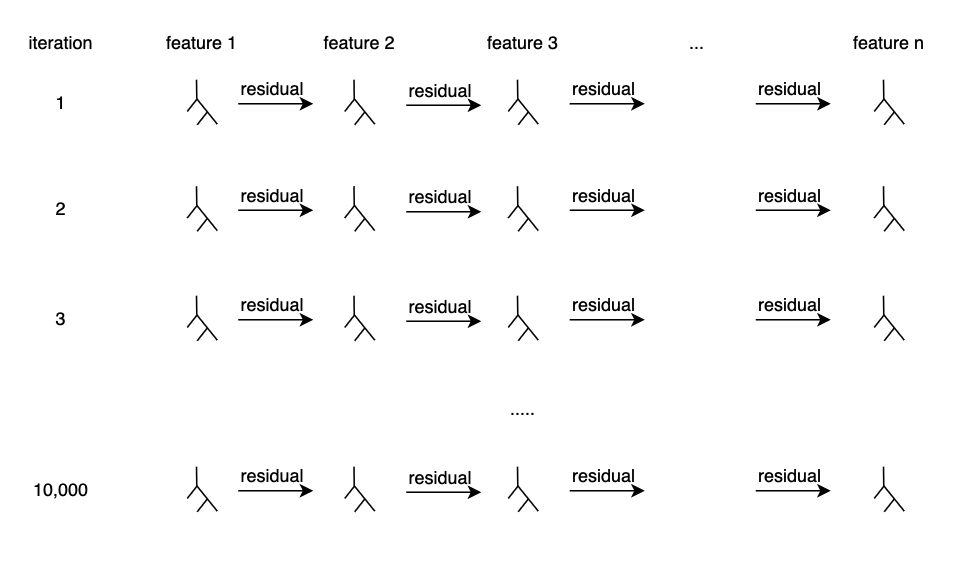
다시 반복, 작은 learning rate를 사용하기 때문에 여러번 돌려 봅니다. 보통은 5,000~10,000번 정도 반복합니다.
이제 학습이 완료되었습니다. 마지막으로 각 피처별로 생성된 트리를 모두 결합하여 하나의 플롯으로 만듭니다. 이렇게 플롯을 만든 이후에는 기존의 트리가 필요없어지므로 제거합니다. 이제 예측은 각 피처마다 생성된 플롯을 사용합니다.
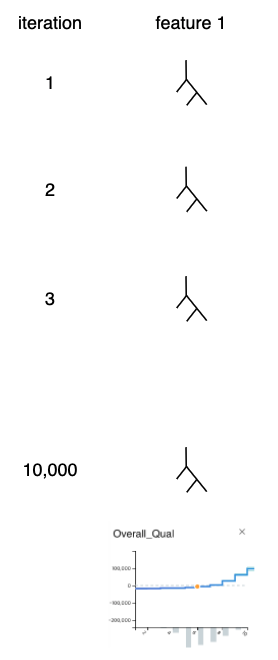
아래에 추가한 작은 플롯의 출처는 gamut이라는 대시보드 프로젝트입니다. 들어가 보시면 유명한 집값 예측 데이터셋을 비롯해 다양한 데이터로 pygam, EBM을 활용해 변수 기여도를 시각화한 예쁜 대시보드를 확인할 수 있습니다.
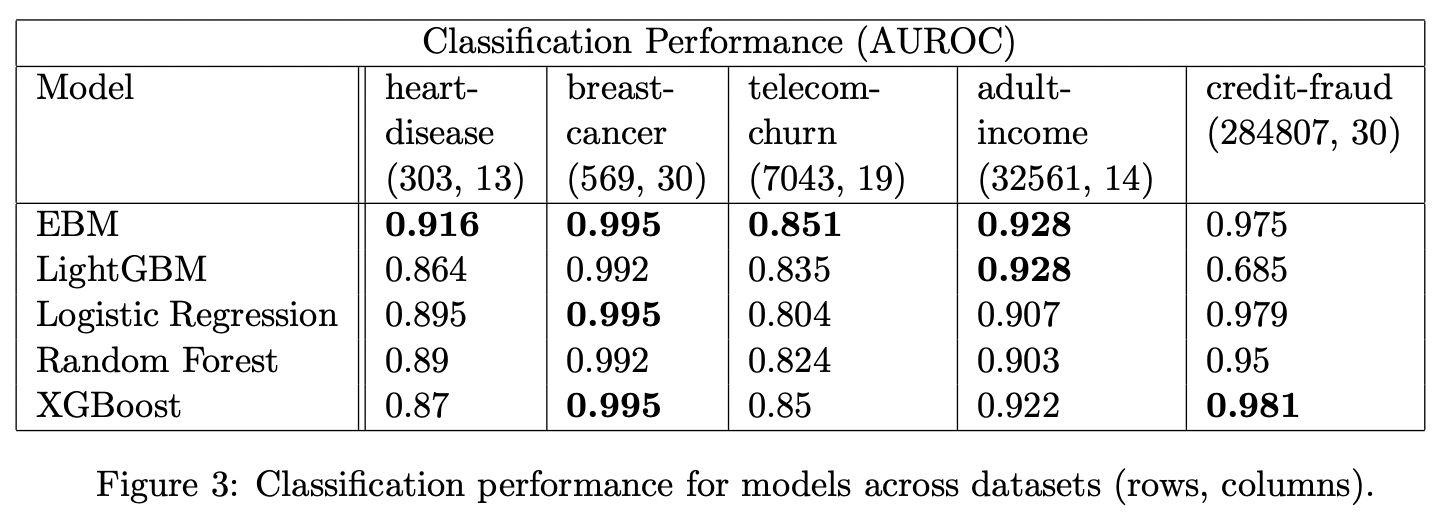
모델의 성능도 빼놓을 수 없겠죠. 논문에서 저자들은 다음과 같이, 기존의 부스팅 모델과 유사하거나 월등한 성능을 보인다고 주장하고 있습니다.
EBM 구현 예제
코드로 한번 구현해 살펴보겠습니다. 이 예제의 출처는 여기입니다.
먼저 보스턴 데이터셋을 로드하고, 8:2로 데이터를 split합니다. 특별할 것 없는 루틴입니다.
import pandas as pd
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
boston = load_boston()
feature_names = list(boston.feature_names)
df = pd.DataFrame(boston.data, columns=feature_names)
df["target"] = boston.target
# df = df.sample(frac=0.1, random_state=1)
train_cols = df.columns[0:-1]
label = df.columns[-1]
X = df[train_cols]
y = df[label]
seed = 1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=seed)
먼저 모델 적합 전, X와 y 변수 간의 marginal plot을 보여줍니다. 피어슨 상관계수도 확인할 수 있습니다.
from interpret import show
from interpret.data import Marginal
marginal = Marginal().explain_data(X_train, y_train, name = 'Train Data')
show(marginal)
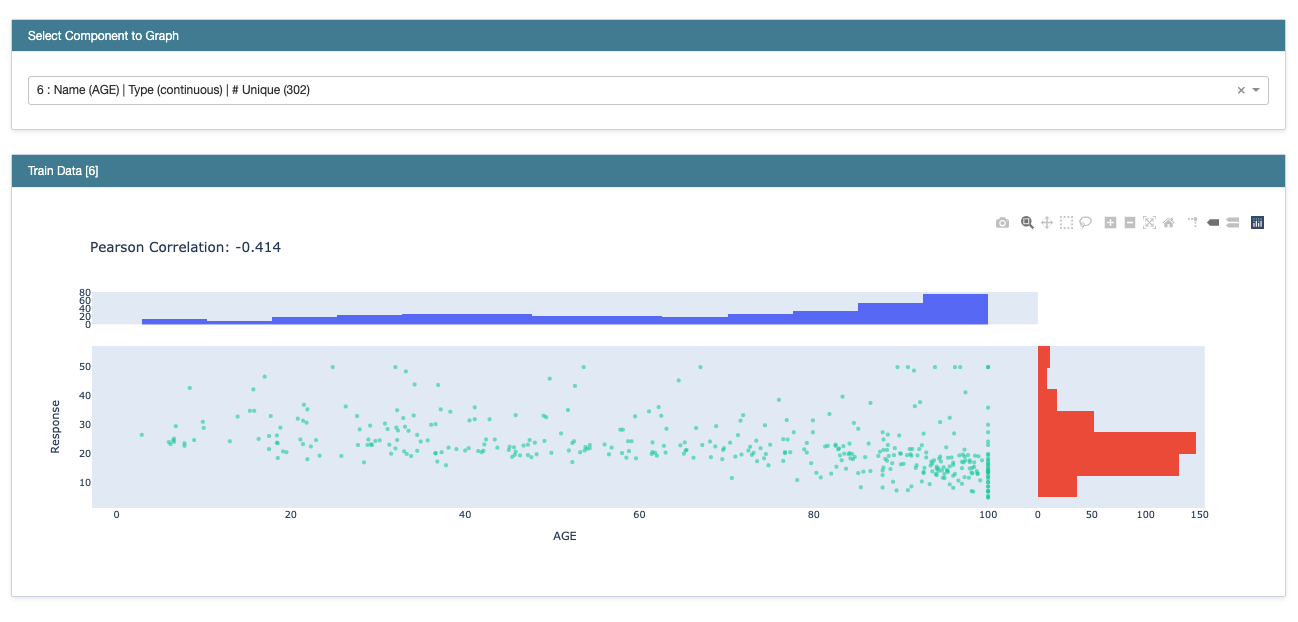
그 다음은 global explanation입니다. 이후에 나올 local explanation은 각각의 개별 인스턴스(데이터 샘플)를 상대로 각 피처의 contribution을 보여줌으로써 explanation을 제공하지만, 여기서는 모델이 전체 인스턴스를 학습함으로써 획득한 전반적인 관점에서의 설명가능성을 제공합니다. 그에 앞서, ebm 인스턴스를 생성하고 학습 데이터에 적합시킵니다.
ebm = ExplainableBoostingClassifier(random_state=seed)
ebm.fit(X_train, y_train)
# Global Explanations: What the model learned overall
ebm_global = ebm.explain_global(name='EBM')
show(ebm_global)
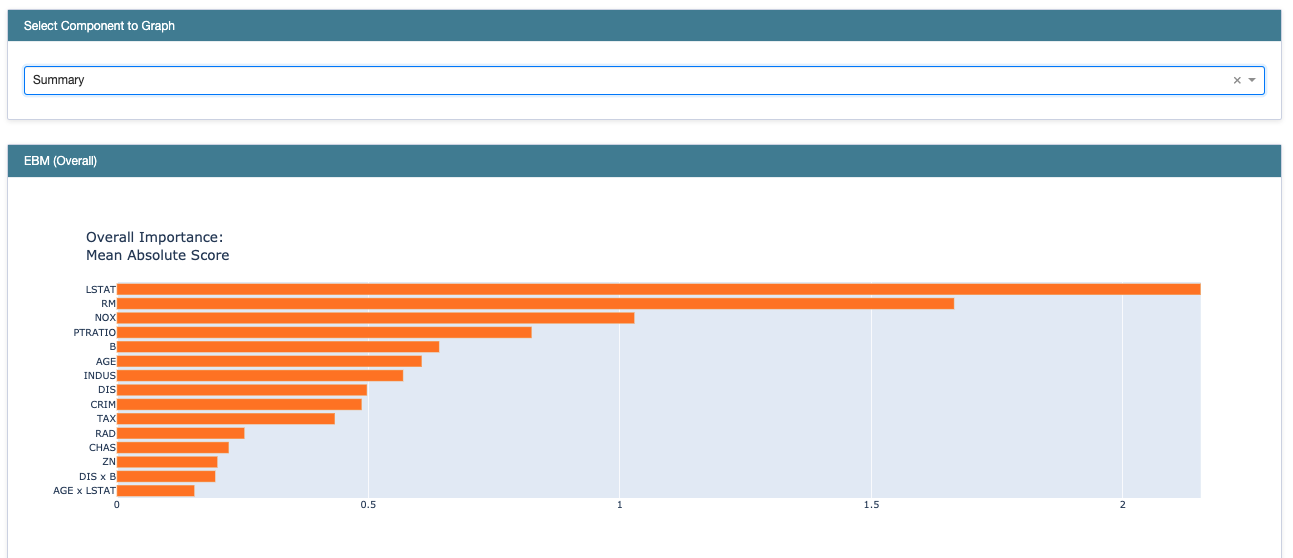
코드를 실행하면 바로 보이는 것은 전체 feature importance입니다. 여기서는 LSTAT이 가장 중요한 변수라고 말해주고 있습니다.
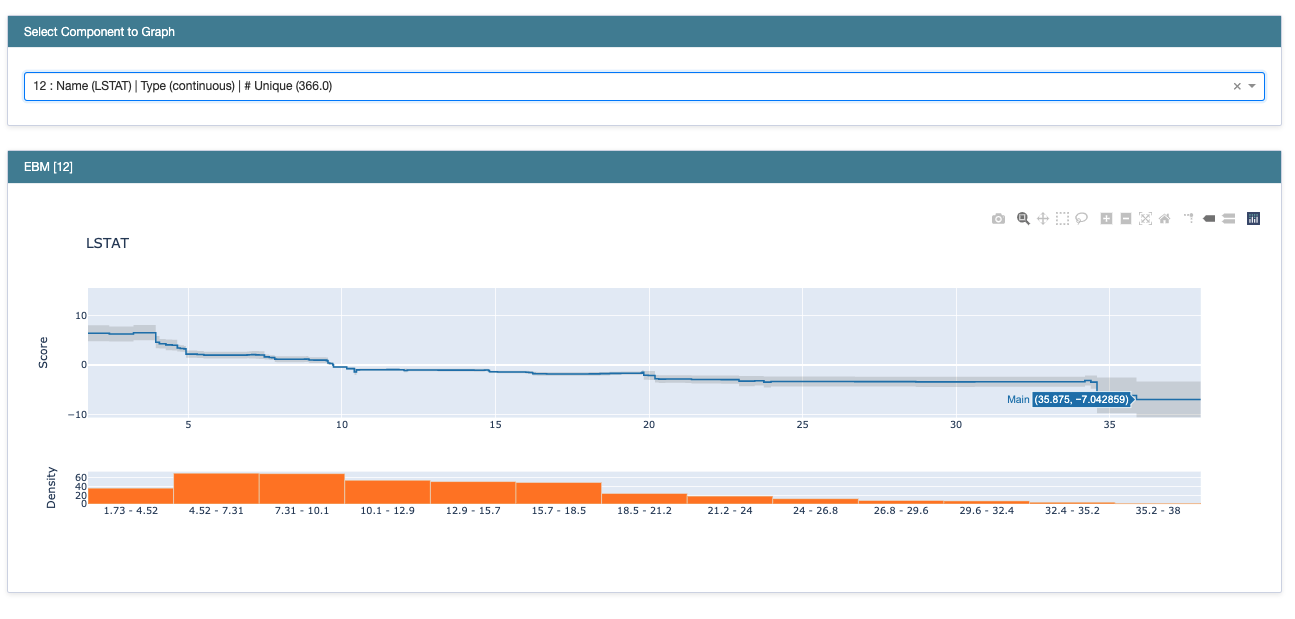
위에 있는 드롭다운을 클릭해보면, 변수마다 전체 샘플에 대해 갖는 score의 plot을 볼 수 있습니다. LSTAT 변수는 값이 증가함에 따라 score가 감소하는 경향을 보이는군요. 또, 아래에 있는 히스토그램은 해당 구간에 존재하는 데이터 샘플의 수를 나타냅니다. 오른쪽 끝에 upper bound와 lower bound가 매우 크다는 것은 해당 구간의 score의 분산이 큰 것을 의미합니다. 구체적인 로직은 이해하지 못했지만, 매우 작은 샘플의 수로 인해 confidence interval이 큰 것을 나타내는 듯 합니다.
마지막으로 local explanation을 살펴 보겠습니다. 5개의 테스트 샘플만을 모델에 넣어 모델의 예측 결과에 대한 설명을 살펴봅니다.
# Local Explanations: How an individual prediction was made
ebm_local = ebm.explain_local(X_test[:5], y_test[:5], name='EBM')
show(ebm_local)
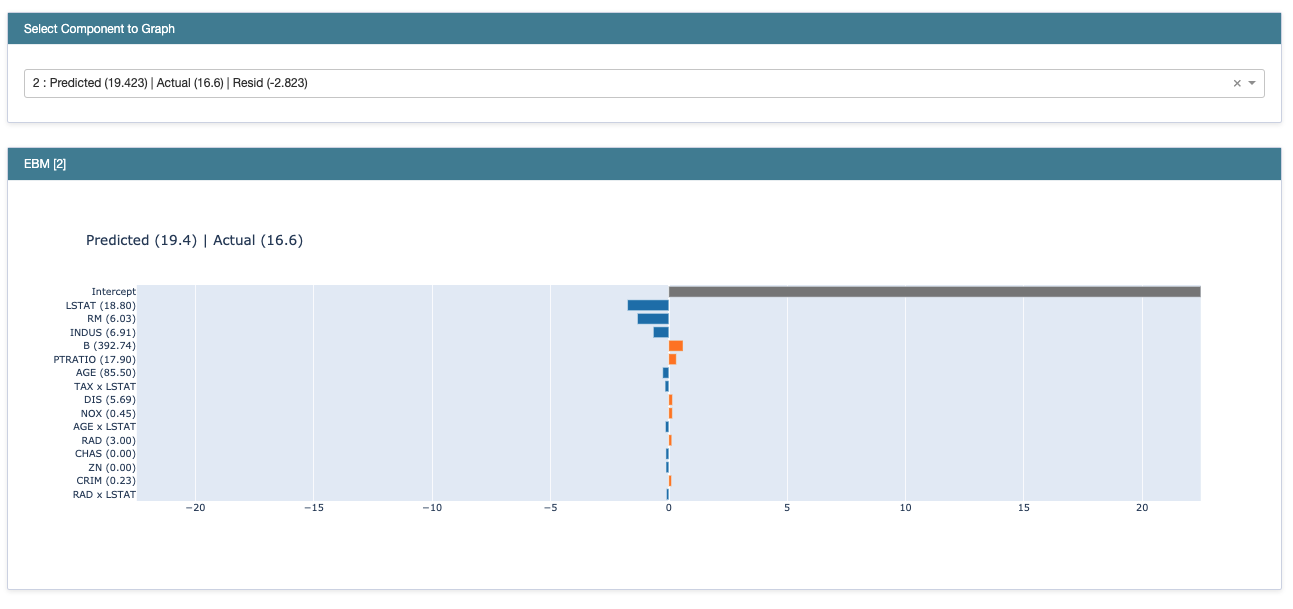
이 플롯은 각각의 피처가 모델의 예측 결과에 미친 영향을 나타냅니다. 파란 막대는 음의 기여도를, 주황 막대는 양의 기여도를 보입니다. 이 모든 기여도가 더해져 최종 예측 값이 계산됩니다. EBM이 additive한 알고리즘을 사용하는 것을 떠올려보면 좋을 것 같습니다. 여기서 intercept가 높게 나오는데요. Boosting 모델에서 residual을 전파해 나가며 모델을 학습할 때 baseline 예측 값으로 사용하는 intercept를 떠올리면 납득이 갑니다.
마치며
지금까지 EBM에 대해 살펴보고, 그 구현까지 따라 해 보았습니다. 이 모델이 비즈니스 로직에 녹아들어 갔을 때 만들어낼 파급효과를 상상해보면, 단순히 신박한 새로운 알고리즘에 그치지 않을 것 같네요. 긴 글 읽어 주셔서 감사합니다.
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요.
내용에 대한 지적, 혹은 질문을 환영합니다.
참고: https://jwprogramming.tistory.com/17
https://towardsdatascience.com/the-explainable-boosting-machine-f24152509ebb
Leave a comment