
[NLP] 주식 뉴스 요약 메일링 프로그램
다양한 NLP 태스크를 간단하게 구현할 수 있는 Pororo를 사용해, 관심 뉴스 종목의 요약문을 메일로 받는 프로그램을 colab 환경에서 구현합니다

Contents
요즘 주식 시장에 대한 관심이 뜨겁습니다. 언론은 각 기업에 대한 좋고 나쁜 이슈들을 뉴스로 알리고, 이를 확인한 개인과 기업에 의해 시장이 출렁이기도 합니다. 그런데, 시시각각 변화하는 주식시장의 이슈들을 항상 관심을 가지고 살펴보기는 쉽지 않은데요. 업무에 집중하다 보면 어떤 이슈가 있는지도 모른채로 지나가서, 수익의 기회 혹은 손실을 줄일 기회를 놓치기 부지기수입니다. 그렇다고 항상 뉴스만 쳐다보고 있을 수는 없는 노릇이고 말이죠.
이를 해결하기 위해, 뉴스를 요약한 정보를 테이블 형태로 전달하는 파이썬 프로그램을 만들어 보았습니다. 이 프로그램은 네이버 금융의 뉴스를 주기적으로 크롤링하여 Pororo라는 멋진 라이브러리가 제공하는 KoBART summary 기능을 사용해, 뉴스 기사를 한눈에 파악하기 쉬운 짧은 문장으로 축약하여 사용자의 메일로 보내줍니다.
요약된 샘플 문장은 다음과 같습니다.
산업통상자원부는 글로벌 차량용반도체 수급 불안정 관련 대책을 모색하고,
미래차·반도체 시장 선점과 국내 공급망 안정화 중장기 협력방안을 논의하기 위해
'미래차-반도체 연대·협력 협의체' 발족식을 열고 단기적으로 수입을 위한 신속 통관과 국내 생산업체의 빠른 성능평가를 지원하며 중장기적으론 차량용 반도체와 부품 등의 자립화를 추진할 계획이라고 밝혔다.

소스코드는 제 깃헙 페이지에서 찾아보실 수 있습니다. 원하시는 경로에 clone하여 사용해 주세요.
이 블로그 포스트 동안, 프로그램의 구성 요소에 대한 간략한 설명을 드리려 합니다.
Pororo 라이브러리 소개
Pororo는 카카오 브레인에서 공개한 파이썬 라이브러리로, 다양한 NLP 태스크에 대한 손쉬운 구현을 제공합니다. 심지어 한국어를 비롯한 다국어의 태스크를 동시에 지원합니다! Pororo의 공식문서를 살펴보면, 얼추 보기에도 굉장히 많은 자연어처리 태스크를 지원하는데요. 저는 미처 알지도 못했던 다양한 태스크를 단 몇줄의 코드로 구현할 수 있다는 점이 매우 흥미로웠습니다.
특히, 제가 가장 인상 깊게 본 것은 zero-shot topic classification 예제였습니다.
zsl = Pororo(task="zero-topic")
zsl('''장제원, 김종인 당무감사 추진에 “참 잔인들 하다”···정강정책 개정안은 “졸작”''', ["스포츠", "사회", "정치", "경제", "생활/문화", "IT/과학"])
{'스포츠': 2.18, '사회': 56.1, '정치': 88.24, '경제': 16.17, '생활/문화': 66.13, 'IT/과학': 11.2}
단 두 줄의 코드로 뉴스 헤드라인의 토픽을 분류해 냈습니다.
이 외에도 많은 기능과 예제를 지원하니, NLP를 사용해 소프트웨어를 만드시려는 분들은 참고하시면 좋을 것 같습니다.
네이버 금융 뉴스 크롤러
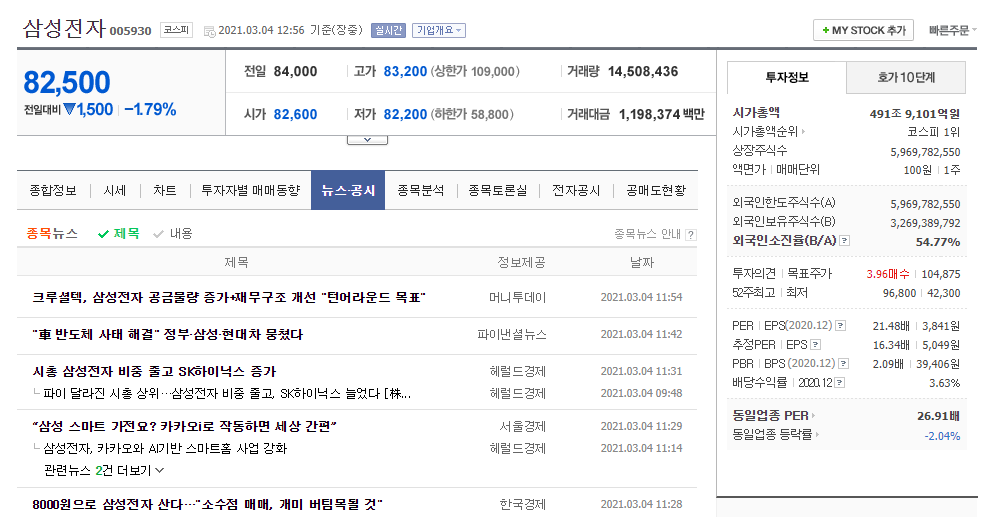
네이버 금융의 뉴스에서 기사를 크롤링하는 코드는 다음과 같습니다.
from bs4 import BeautifulSoup
import requests
import pandas as pd
import re
import os
class news_crawler:
def __init__(self):
self.company_code_table = pd.read_csv('company_list.txt', dtype=str, sep='\t')
def crawler(self, company_code, num_article):
done_page_num=0
# page = 1
num_per_page=20 # naver serves 20 articles per page
num_page,remainder=divmod(num_article,20)
num_page+=1
article_result=[]
for page in range(done_page_num+1, done_page_num+num_page+1):
try:
url = 'https://finance.naver.com/item/news_news.nhn?code=' + str(company_code) + '&page=' + str(page)
source_code = requests.get(url).text
html = BeautifulSoup(source_code, "lxml")
# 뉴스 링크
links = html.select('.title')
link_result =[]
if page == num_page:
links=links[:remainder]
for link in links:
add = 'https://finance.naver.com' + link.find('a')['href']
link_result.append(add)
print(f"{len(link_result)}개의 뉴스 크롤링..")
except Exception:
pass
for article_url in link_result:
try:
article_source_code = requests.get(article_url).text
article_html = BeautifulSoup(article_source_code, "lxml")
article_time = article_html.select('.tah')[0].get_text()
# 뉴스 내용
article_contents = article_html.select('.scr01')
article_contents=article_contents[0].get_text()
article_contents = re.sub('\n','',article_contents)
article_contents = re.sub('\t','',article_contents)
# cut extra text after Copyright mark
if "ⓒ" in article_contents:
article_contents=article_contents[:article_contents.index("ⓒ")]
# cut too long text to prevent CUDA OOM issue
if len(article_contents)>=1500:
article_contents=article_contents[:1500]
article_result.append([article_contents,article_time])
time.sleep(random.uniform(0.1,0.7))
except Exception:
pass
# print("다운 받고 있습니다------")
return article_result
def convert_company_to_code(self,company):
# 종목코드 추출
company_name = self.company_code_table['회사명']
keys = [i for i in company_name] #데이터프레임에서 리스트로 바꾸기
company_code = self.company_code_table['종목코드']
values = [j for j in company_code]
dict_result = dict(zip(keys, values)) # 딕셔너리 형태로 회사이름과 종목코드 묶기
pattern = '[a-zA-Z가-힣]+'
if bool(re.match(pattern, company)) == True:
company_code = dict_result.get(str(company))
return company_code
else:
company_code = str(company)
return company_code
def crawl_news(self, company, max_num=5):
print(f"{company} 종목 뉴스를 가져옵니다.")
company_code=self.convert_company_to_code(company)
if company_code:
result=self.crawler(company_code, max_num)
for i in range(len(result)):
result[i].append(company)
return result
else:
print(f"{company} 종목이 존재하지 않습니다.")
return []
먼저, crawler 메서드는 기업 코드와 가져올 기사의 수를 입력으로 받아 뉴스를 가져옵니다. 가져오는 주소를 살펴보면, 여기와 같은 화면을 볼 수 있습니다. 여기서 각각 url 내부의 기사 내용을 긁어옵니다.
convert_company_to_code 메서드는 기업 명을 입력으로 받아 종목 코드를 출력해주는 메서드입니다. 이 종목 코드를 사용해 원하는 기업의 뉴스 기사가 모여있는 링크로 이동할 수 있습니다.
crawl_news 메서드는 크롤링을 순차적으로 수행합니다.
Gmail 연동하기
이제 메일링을 위해 Gmail을 연동해봅니다. 파이썬을 사용해 메일에 로그인하고, 원하는 내용을 보내주는 기능을 구현해 봅니다. 이를 위해서는 이메일 클라이언트에 앱이 접근할 수 있도록 처리해 주어야하는데, 이 과정을 살펴보겠습니다.
1) 앱 비밀번호 발급받기
먼저, 구글계정의 앱 패스워드를 지정해야 합니다. 이에 대한 안내는 여기에서 찾아보실 수 있습니다.
1) 구글 계정으로 이동해 주세요.
2) 왼쪽의 보안으로 들어갑니다.
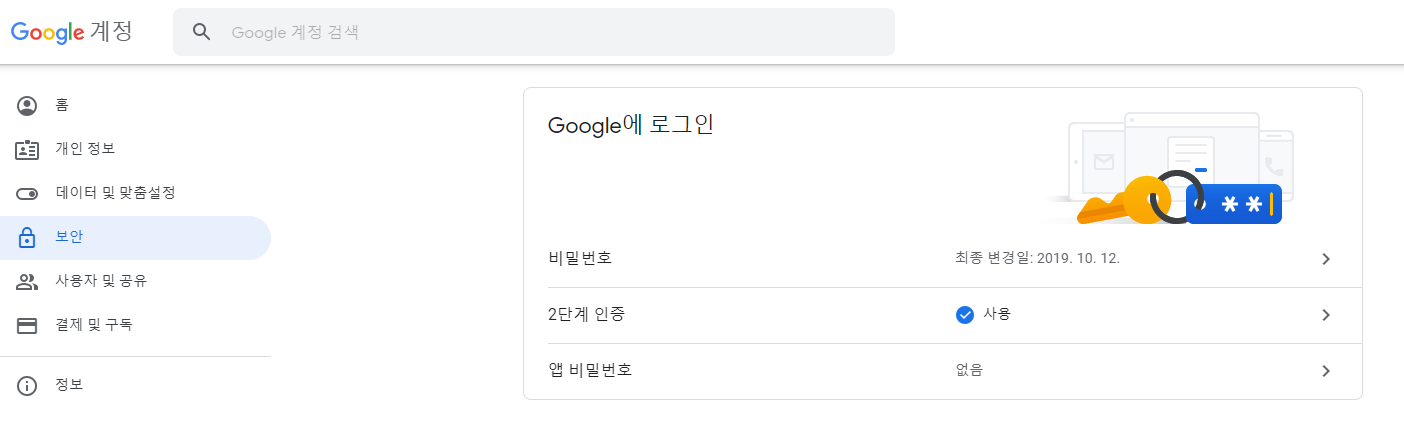
3) 2단계 인증을 활성화 해주세요. 이미 되어있는 분들은 건너 뛰셔도 됩니다.
4) Google에 로그인의 앱 비밀번호를 설정해 줍니다. 기기명은 마음대로 지어주세요.
5) 생성된 16자리 앱 비밀번호를 복사해 놓습니다.
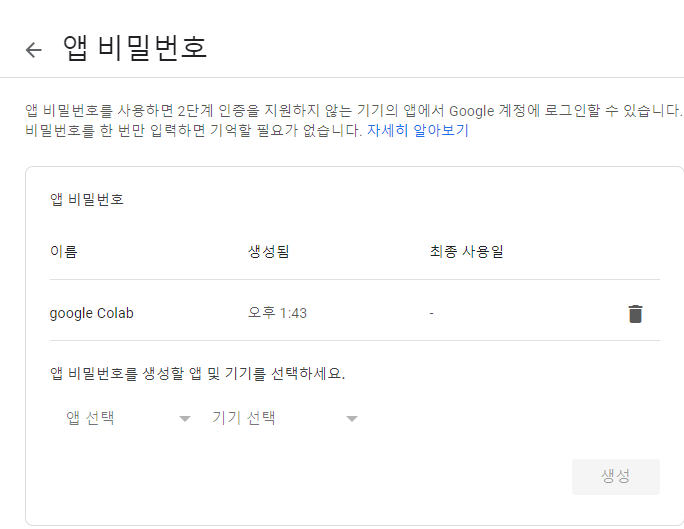
2) 이메일 전송 모듈
from smtplib import SMTP
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
def send_mail(subject,from_email, password ,to_email, basic_text, body):
message = MIMEMultipart()
message['Subject'] = subject
message['From'] = from_email
message['To'] = to_email
message.attach(MIMEText(basic_text, "plain"))
message.attach(MIMEText(body, "html"))
msg_body = message.as_string()
server = SMTP('smtp.gmail.com', 587)
server.starttls()
server.login(message['From'], password)
server.sendmail(message['From'], message['To'], msg_body)
server.quit()
메일을 보내는 모듈입니다. 판다스 데이터 프레임 형태의 데이터를 html로 바꾸어준 뒤, 추가적인 텍스트와 함께 보내는 기능을 수행합니다.
요약문 생성, 발송하기
def get_news():
crawl_result=[]
for company in company_list:
crawl_result+=crawler.crawl_news(company,5)
news_summary=process_summary(crawl_result)
news_table=pd.DataFrame(news_summary)
news_table.columns=["company","summary","date"]
table_to_send=build_table(news_table,"blue_light")
send_email.send_mail(subject=subject,
from_email=from_email_id,
password=from_email_pw,
to_email=to_email,
basic_text=basic_text,
body=table_to_send)
기업 리스트를 지정해 줍니다. 함께 첨부된 company_list.txt에 있는 이름과 동일하게 입력하도록 주의해주세요. 크롤링한 정보를 요약한 뒤, 제목과 발신 계정(아까 앱 비밀번호를 발급받은 아이디), 그리고 발급받은 16자리 비밀번호를 만들고 내용과 함께 보내줍니다.
이제 주기적으로 반복되도록 하면, 일하는 와중에도 틈틈이 종목 기사를 요약해 날라주는 귀여운 뉴스 배달부가 만들어졌습니다.
마치며
이렇게 종목 뉴스를 크롤링하여, Pororo로 요약하고, 이메일로 보내주는 프로그램에 대해 살펴보았습니다. 추가적인 기능에 대한 조언을 댓글 혹은 메일로 남겨주시면 감사하겠습니다!
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요. 내용에 대한 지적, 혹은 질문을 환영합니다.
Leave a comment