
[NLP] KoBERT Multilabel VOC 분류 모델 개발기
pretrained KoBERT 모델을 사용해 multi-label VOC(Voice of Customers) 분류기를 만들며 얻은 교훈을 공유합니다.
1. Pretrained Model을 사용함으로써 매우 적은 데이터로도 준수한 분류 성능을 얻을 수 있음
2. 수작업으로 라벨링을 할 때, 모델에게 혼동을 주지 않도록 정확한 기준을 세우는 것이 필요
Contents
들어가며
배경
큰 기업에서는 매일 수 천건, 통화로 생성되는 STT 결과 데이터를 포함하면 수 만건에 달하는 VoC(Voice of Customers)가 발생합니다. 이 때 고객의 불만 사항을 실시간으로 분류/관리하여 트렌드를 추적해주는 시스템이 있다면, 운영 부서에서 미처 예상치 못한 서비스 장애를 진단하여 조기에 대응할 수도 있고, 나아가 고객 불만을 보상하는 프로모션을 제공한다면 고객 이탈을 방지함과 동시에 세일즈 KPI에 직접적인 효과를 얻을 수 있겠죠. 이러한 맥락에서 고안된 VOC 자동 분류 모델입니다. 개발 시기는 2020년 하반기입니다.
소스 코드는 저의 깃헙 레포지터리에서 확인해 보실 수 있습니다.(데이터와 웨이트 파일은 제공되지 않습니다. 양해 부탁드립니다)
데이터
이 모델에 사용된 데이터는 모 항공사의 VOC 데이터이고, 약 2,000건의 raw 데이터를 가지고 있습니다. 전체 레이블의 수는 70여개이며, 모델링에 사용된 수는 17개 입니다. 극히 소수의 데이터에서 실제 현업에 적용 가능한 수준의 성능을 검증하는 것이 해당 모델의 구현 목적이었습니다. 라벨 데이터는 현업 전문가에 의해 태깅되었고, 상담사와 고객의 대화를 보고 관련되었다고 판단되는 태그를 달아 주었습니다.
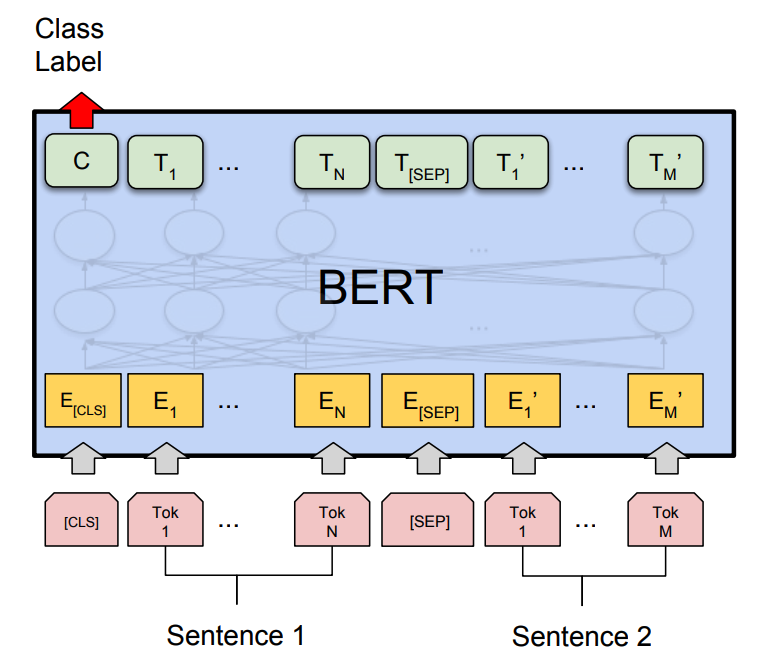
SKT KoBERT
BERT가 세상에 공개된 이후 벌써 2년이 넘는 시간이 흘렀습니다. 막대한 양의 코퍼스로 수 억개를 가볍게 넘는 파라미터를 가진 거대한 모델을 학습하여 pretrain하면, 이 pretrained model을 적용해 다양한 downstream task에서 손쉽게 높은 성능을 얻어낼 수 있다는 아이디어는 이제 새로운 것이 아닙니다. 한국어를 사용한 다양한 태스크에서 이러한 모델을 적용하고자 한다면, 기존에는 구글에서 공개한 multilingual model을 사용해야 했는데, 이 모델은 BERT가 영어 task에서 보여주는 성능에 비해 다소 아쉬운 결과를 보여주었습니다. 그러다 SKT에서 매우 발빠르게 한국어 코퍼스로 학습한 BERT 모델을 공개했는데요, 바로 KoBERT입니다.
KoBERT는 한국어 위키 데이터 5백만 문장, 5,400만 단어를 사용해 학습했고, 8002개의 vocab size를 갖습니다. 공식 레포지터리에서는 pretrained된 웨이트를 PyTorch, ONNX, MXNET을 사용해 직접 모델을 구축하는 데 사용할 수 있도록 예제를 제공하고 있습니다. 여기서 공개된 KoBERT binary classifier 예제를 변형해 multi-label 문제를 해결하는 데 사용하였습니다.
모델링
Multi-label vs Multi-class
멀티 레이블(multi-label)과 멀티 클래스(multi-class) 문제는 자주 혼용됩니다. 직관적으로 말하자면 멀티 레이블은 다수의 답이 가능한 경우를 말하고, 멀티 클래스는 여러 선택지 중 가장 가능성이 높은 선택지를 답으로 정하는 경우를 말합니다.

위와 같이 강아지 사진이 있을 때, “강아지, 고양이, 토끼, 거북이”라는 네 가지 클래스 중 어떤 것에 더 가까운지,
| 클래스 이름 | 강아지 | 고양이 | 토끼 | 거북이 |
|---|---|---|---|---|
| score | 0.95 | 0.02 | 0.03 | 0.00 |
이 표와 같이 확률값의 형태로 softmax의 출력값을 뱉어내는 상황을 멀티클래스의 예시라고 할 수 있습니다.

이와는 달리 “강아지, 고양이, 토끼, 거북이” 모두가 답으로 가능해 아래처럼 복수의 클래스에 대해 다 1에 가까운 값을 뱉을 수 있는 경우를 멀티 레이블이라고 합니다.
| 클래스 이름 | 강아지 | 고양이 | 토끼 | 거북이 |
|---|---|---|---|---|
| score | 0.95 | 0.87 | 0.92 | 0.01 |
주어진 문제에서는, 특정 VOC가 주어졌을 때 관련된 태그를 모두 생성해 주는 모델이 필요했고, 따라서 멀티 레이블로 모델링을 진행하였습니다.
model performance
해당 모델은 Multi-Label classification 모델로, 전체 2,000여 건의 샘플 데이터를 train 85%, test 15%로 분할하여 테스트했습니다.
| methods | NDCG@17 | Micro f1 score | Macro f1 score |
|---|---|---|---|
| KoBERT | 0.841 | 0.615 | 0.534 |
임베딩 시각화
프로젝트의 초기에는 multi-class task로 접근하여 모델링을 진행했습니다. 그런데, 500여개의 데이터 셋으로 나왔던 1차 성능에 비해 샘플이 더 추가된 데이터 셋으로 만든 2차 모델의 성능이 더 떨어지는 현상이 발생했고 (8개 클래스 77% -> 73%), 원인 파악을 위해 오분류 샘플을 조사했습니다.
| 카테고리 명 | |
|---|---|
| 예측 정확도 70% 이상 | 무상 변경/취소, 유상 변경/취소, 기내 서비스 등 |
| 예측 정확도 40% 이하 | 예약 기타, 변경/취소 |
위와 같이, 기타 클래스의 특징을 모호하게 포함하고 있는 클래스의 성능이 매우 낮은 것을 확인할 수 있었습니다. 사람이 직접 의미적으로 판단해도 모호한 경우가 많았습니다. 이 클래스에 포함된 샘플들은 모델의 최적화 과정에서 모호한 시그널을 제공함으로써 파라미터 최적화에 악영향을 미칠 것이라고 직관적으로 생각했고, 이와 같은 내용이 버트 분류 모델의 예측에 사용되는 마지막 CLS 토큰의 representation을 low dimension에 mapping 했을 때 확인 가능할 것이라고 가정했습니다.
아래는 실제 CLS 토큰의 임베딩에 T-SNE를 적용한 결과입니다. 모호한 라벨을 가진 샘플들에 의해 임베딩 스페이스가 다소 entangled된 형태를 보이는 것을 알 수 있습니다.
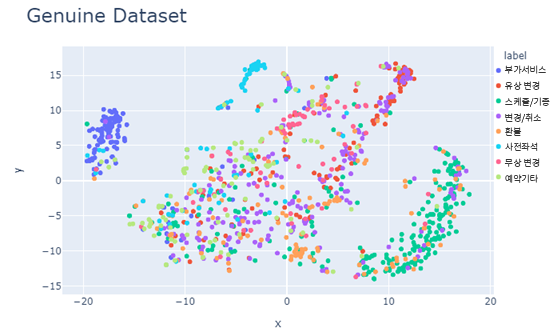
그렇다면 이 라벨들을 제거해 준다면, 버트 representation 이후의 레이어가 결정 경계를 손쉽게 그을 수 있도록 임베딩이 학습되지 않을까요? 그러한 질문에 답한 것이 다음과 같은 이미지였습니다.
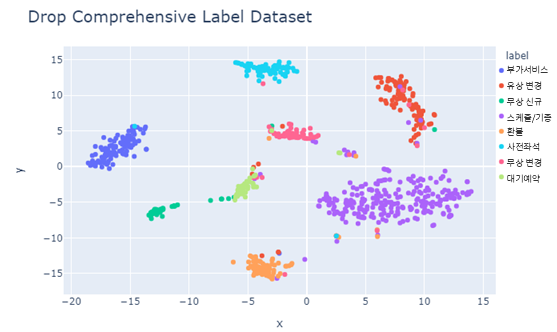
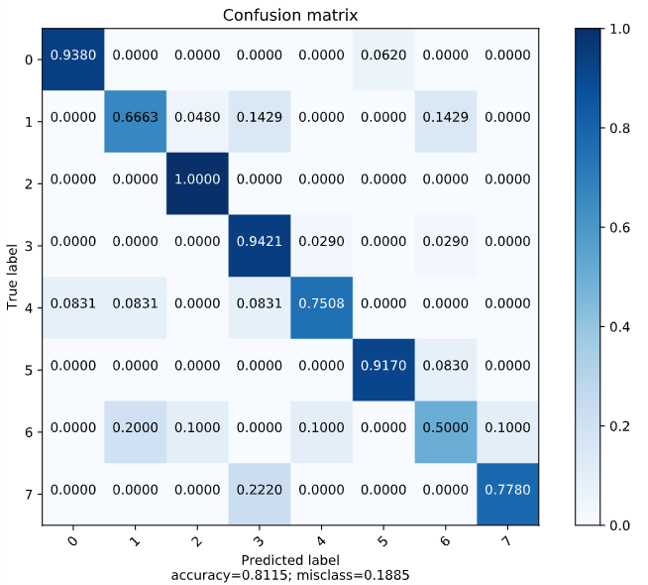
예쁘게 잘 정리 됐네요. 이와 같은 결과가 말해주듯이, 데이터셋을 수작업으로 레이블링할 때 모델이 혼동하지 않는 기준을 세우는 것이 중요하다는 결론을 내릴 수 있었습니다. 아래는 수정 후 모델의 confusion matrix입니다. 85:15로 stratified sampling을 해 주었습니다.
XAI using pytorch Captum
Captum은 PyTorch 모델의 interpretability를 위한 라이브러리입니다. 이 중 자연어 분류 모델의 판단에 긍정적, 부정적으로 영향을 미친 토큰을 시각화해주는 예제가 있어 본 문제에 적용해 보았습니다. 아래는 시각화 결과입니다.

“기내 서비스” 라는 레이블을 예측하는 데 positive한 영향을 준 토큰은 녹색으로, negative한 영향을 준 (즉 라벨 예측에 혼동을 준) 토큰은 붉은 색으로 시각화해 줍니다. 우리의 경우에서는 토큰 시각화가 직관에 다소 부합하지 않는 결과를 보이기도 했으나, 이는 소수 샘플로 인한 특정 토큰의 영향에 의한 것일수도, 한글 토큰의 인코딩의 문제일 수도 있습니다.
Streamlit Demo
streamlit은 웹/앱 개발에 익숙치 않은 데이터 사이언티스트들이 손쉽게 웹앱 데모를 구현할 수 있도록 도와주는 high-level data app 라이브러리입니다. 입출력을 현업에게 빠르게 보여주기 위해 다음과 같은 데모를 만들었습니다. 불과 몇 분의 투자로 모델의 I/O를 보여줄 수 있는 매우 간편한 기능을 제공합니다.

마치며
이번 포스트에서는 현업에서 겪어본 VOC 분류 모델을 개발하는 과정에서 겪은 이야기를 공유했습니다. 같은 문제를 접하는 누군가에게 도움이 되었기를 바랍니다.
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요.
내용에 대한 지적, 혹은 질문을 환영합니다.
Leave a comment