
[RecSys] 쿠팡 추천 시스템 2년간의 변천사 (상품추천에서 실시간 개인화로)
쿠팡 추천 시스템 2년간의 변천사
쿠팡 오상민님의 Deview 발표 자료를 들으며 정리한 노트입니다.

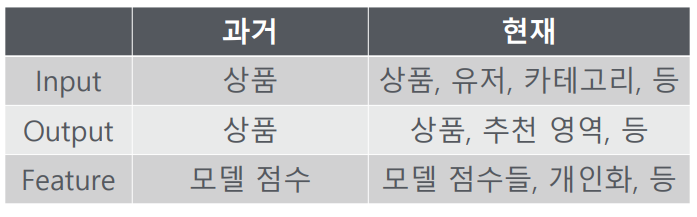
1. 쿠팡 추천시스템은 모델 중심의 플랫폼에서 서비스와 모델을 분리하는 플랫폼으로 변화함
2. 추천에서는, 단순히 복잡한 추천 모델을 사용해 높은 오프라인 메트릭을 얻는 것이 중요한 것이 아님
3. 그 보다는 시스템의 스케일과 안정성, 해석 가능성 등을 고려하여 단순한 모델으로 피처 엔지니어링에 투자하는 것이 추천 태스크에 유리할 수 있음
본 포스트는 쿠팡 오상민 님의 발표 영상을 토대로 작성한 노트입니다. 영상은 여기에서 보실 수 있습니다.
Contents
들어가며
3년 전 Naver Deview 2019에서 공개된 쿠팡 추천시스템 관련 발표를 정리해 보았습니다. 비즈니스/서비스와 시스템에 종속성이 큰 추천 시스템 분야 특성상 특정 기업이 내부적으로 어떤 구조의 추천시스템을 운용하고 있는지 알기 어려운데, 쿠팡같이 많은 사용자가 사용하는 거대한 플랫폼에서 어떤 방식으로 추천을 제공하는지 자세하게 알려주는 귀중한 자료입니다.
추천시스템을 공부하다보면, 자연어처리나 비전에서와 같이 새로운 알고리즘, 새로운 방법론, 복잡한 패턴을 잡아내는 근사하고 거대한 알고리즘에 매혹되기 쉽고, 저 역시 그러한 현학적인 재미에 취해 알고리즘에 많은 시간을 투자해 왔습니다.
그런데 이 발표는 전혀 다른 것을 말해주고 있었습니다. (선배가 항상 강조하던 말처럼) 추천시스템은 크고 복잡한 모델이 중요한 것이 아니라 고객이 인지적으로 유익함을 느끼는 상품/컨텐츠를 제공할 수 있도록 유용한 피처를 뽑아내는 일, 그리고 그 것을 주어진 현재 시스템의 제약 하에서 효율적으로 설계하는 일이 중요하다는 내용을 실제 사례로 뚜렷하게 말해주고 있기 때문입니다.
앞으로 알고리즘뿐만이 아닌 그를 감싸고 있는 다양한 비즈니스 로직과 효율성에 대한 고민, 더 나은 피처를 만들어내는 방법에 더 많은 시간을 쏟아야겠다는 개인적인 교훈을 안겨준 발표였습니다.
아래는 발표를 들으며 이해한 핵심적인 내용을 개조식으로 정리한 자료입니다. Deview 2019에 공개된 발표 자료를 읽거나 발표 영상을 시청하시는 분들께 도움이 되기를 바랍니다.
쿠팡 추천 플랫폼의 변화
1. 쿠팡 추천 팀이 하는 일
- 상품 추천: 아이템을 입력으로 받아 아이템을 출력, item과 item 사이의 relation을 찾아주는 작업
- 가령 같이 본 상품(대체재), 같이 산 상품(보완재)를 추천해 주는 것임
- 하고싶던 것
- 나를 위한 개인화 추천
- 오늘의 쇼핑 제안
- 요즘 인기있는 상품들
- 나를 위한 할인 상품들 등을 추천하고 싶었음.
- 카테고리를 보고 있으면 그 카테고리에서 내가 자주 산 상품, 그 카테고리에서 요즘 인기있는 상품 등, 특정 상품을 컨텍스트로 하지 않고 유저를 컨텍스트로 한다거나 카테고리, 시간을 컨텍스트로 하는 추천을 하고 싶었음.
- 요컨대 item 뿐만아니라 category, time, user와 item의 relations를 찾고 싶었음.
- 여러 관계를 만든 뒤에는 다양한 context를 결합하여 반영하거나, 다양한 context간에 weight를 줌으로써 서비스도 다양화하고 싶었음.
- 또한 자유로운 필터를 걸고 싶었음.
- 나아가 아이템 뿐만 아니라 reco(추천영역) 자체도 추천해주고, 고객이 좋아하는 UI(빨간 theme을 좋아하면 빨간화면..) 역시 추천해주고 싶었음.
- 현재 쿠팡의 추천
- 유저기반 개인화 추천
- 개인화 할인 상품(필터와 부스팅을 활용)
- 시간 기반 인기상품(요즘 인기있는 카테고리)
- 상품 특성 필터링(쿠팡 PB)
- 카트에 담긴 상품을 고려하여 추천 -> 유저들이 더 빠르게 좋은 결정을 내리도록 도와줌
- UI: 여러 탬플릿을 갖추어 유저의 선호에 따라 제공
-
변화 요약
2. 과거, 추천 모델 중심의 플랫폼
- 과거의 추천 모델: 추천 모델 중심의 플랫폼
- 추천 모델이 만들어지면 그 자체가 서비스로 나갔음
- 따라서 item-item 관계가 매우 중요함
- 그렇기 때문에 model -> service가 매우 강하게 연결됨
- 이로 인해 매우 많은 문제가 발생됨
- 이 때의 모델은 매우 복잡하게 됨. 상품정보, 로그, 유저 정보를 사용해 복잡한 중간 단계 테이블이 나옴. 이를 거쳐 최종적인 결과가 나옴.
- 최종 결과에는 A 상품에 대해서 B는 몇점이야 하는 식으로 나옴. 카메라에 대해 케이스는 몇점이야.. 하는 식
-
과거 서버 환경
- 서버 쪽 아키텍처는 매우 단순함. 모델 파이프라인의 결과테이블이 추천시스템의 전체를 결정했기 때문에, 서버는 특정 product id에 대해서 다른 product id를 score 순서대로 뱉어주는 key-value storage(NoSQL)를 lookup해 주는 것으로 충분했음.
- 유저나 카테고리, 멀티 프로덕트 등의 복합적인 컨텍스트를 고려하지 않기 때문에 key는 상품 id가 되고, 상품의 수가 증가하더라도 선형적으로 증가하기 때문에 무리없이 캐시를 이용해 낮은 레이턴시를 유지할 수 있었음.
- 때때로 유저가 이미 구매한 상품을 필터링하기 위해 외부 서비스(external)를 이용하기도 하지만, 사실상 서버 API에서 추천 랭킹을 위해 할 수 있는 일은 굉장히 제한되었음.
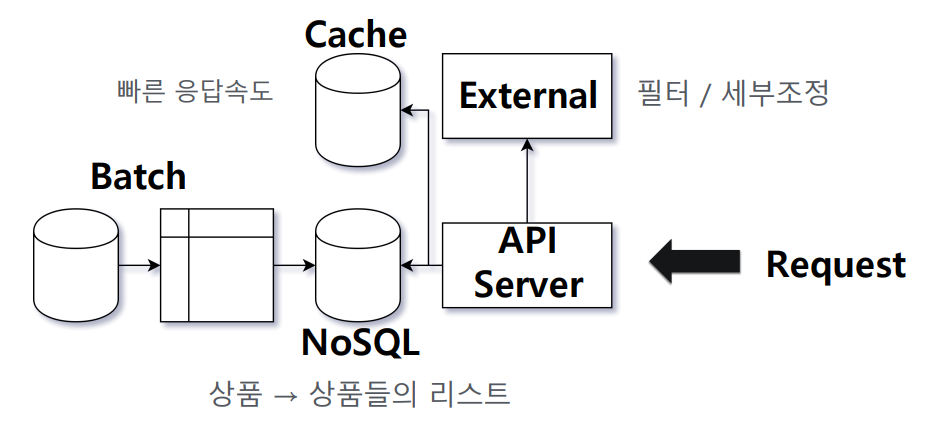
2.1.2 아키텍처 - 서버 -
모델 중심 아키텍처의 단점/한계
- 모델의 결과가 추천 모델에서 나온 그대로일 때, 다양한 문제가 발생함 1) 모델 변경에 따라 길어지는 파이프라인(필터, 부스트..) -> 문제(변경 사항이 생기거나, 데이터에 문제가 생기거나, 배치가 잘못 돌거나..)가 생길 때 처음부터 다시 돌려야했음. 2) 추가 요청을 처리하기 어렵다 3) 완성 전까지 결과를 알 수 없다 4) 개발에 시간이 오래 걸린다
- 상품 정보, 유저 정보는 데이터 생성 후에만 접근 가능했기때문에 API 서버에서 서빙시에 다른 상품정보, 유저정보를 사용하는 것은 거의 불가능에 가까움
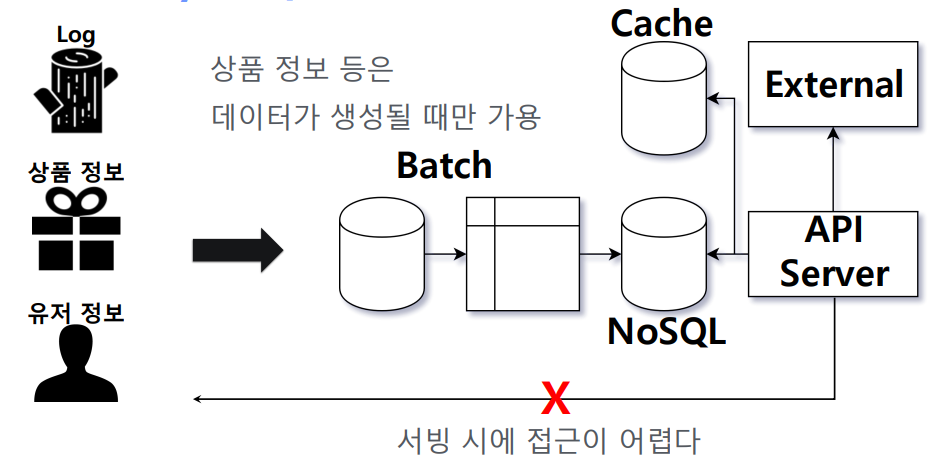
2.2 한계 -
서비스를 개선하기 위해서는, 추천/데이터 파이프라인 자체를 건드려야했음. 새로운 시도 할때마다 새롭게 만들어야 했음. -> 기존의 모델은 재활용 불가, 버려져야함.
-
목표
1) 추천 모델과 서비스를 분리시킬것
2) 상품 정보/유저 정보를 서빙 타임시에 접근 가능할 것
3) 필터, 부스팅 등의 변경이 쉽고 빠를 것
3. 현재, 서비스와 모델을 분리하는 플랫폼
- 현재, 서비스와 모델을 분리하는 플랫폼
- 검색과 추천: 검색은 자연어를 던져 키워드 매칭 결과에 따라 관련도를 기준으로 결과를 쏴주는 식이며, 추천은 상품/유저를 쿼리로 던져 모델 결과를 스코어 기준으로 쏴줌.
- 쿼리를 던져 후보를 뽑은 뒤 결과를 제공하는 점에서 추천과 검색의 메커니즘은 동일
- 추천에서도 검색엔진을 사용하면, candidate retrieval이나 reranking, filter, boosting 등의 검색 엔진의 기능을 사용함으로써 좀 더 쉽고 편한 대응이 가능.
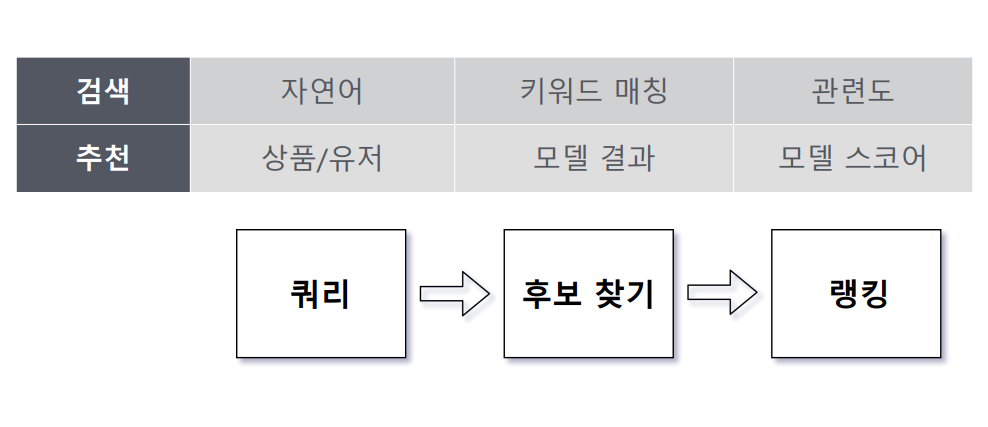
3.1 검색과 추천
- 추천 시스템 - 추천 모델 파트
- 우선 추천 모델로 상품간의 연관성을 생성하고, 이를 모아서 인덱싱을 수행
- 검색엔진으로 추천 플랫폼을 이관하면서, 추천팀과 검색팀은 상품에 대한 정보를 한 데 모으기 시작
- 스파크, 하이브, 텐서플로로 상품에 대한 여러가지 정보를 모음. 이렇게 생성한 피처 정보를 hbase에 모음. 이는 상품간의 연관성 정보가 될수도 있고, 상품 하나의 정보가 될수도 있음.
- 검색팀과 추천팀은 각각의 컬럼 패밀리를 두고 프로토콜 버퍼로 각자 관리하는 데이터를 저장하고 있음.
- 프로토콜 버퍼는 프로덕트라는 메시지를 정의해서 관리함. 프로덕트에는 그 자체가 갖는 이미지, 카테고리, 리뷰수, 가격, 평점 등이 기록되고, 별도로 추천팀이 관리하는, 이 상품이 다른 상품에 대해 몇점으로 나갈 수 있는지에 대한 정보도 별도로 반복 필드로 관리
- 인덱싱할때는 검색팀과 추천팀이 관리하는 정보가 별도의 다른 컬럼 패밀리에 들어있기 때문에 프로토콜 버퍼의 merge_from API로 관리할 수 있음
- 이러한 통합된 정보 시스템으로 인덱싱할 때 사용할 수 있는 정보가 폭넓어짐
- 기존에는 연관성 피처 중 추천 모델의 결과만을 사용했는데, 이제는 이미지 유사도, 카테고리 연관성도 사용할 수 있고 나아가 상품 자체의 피처인 카테고리, 상품평, 가격 등을 사용할 수 있음
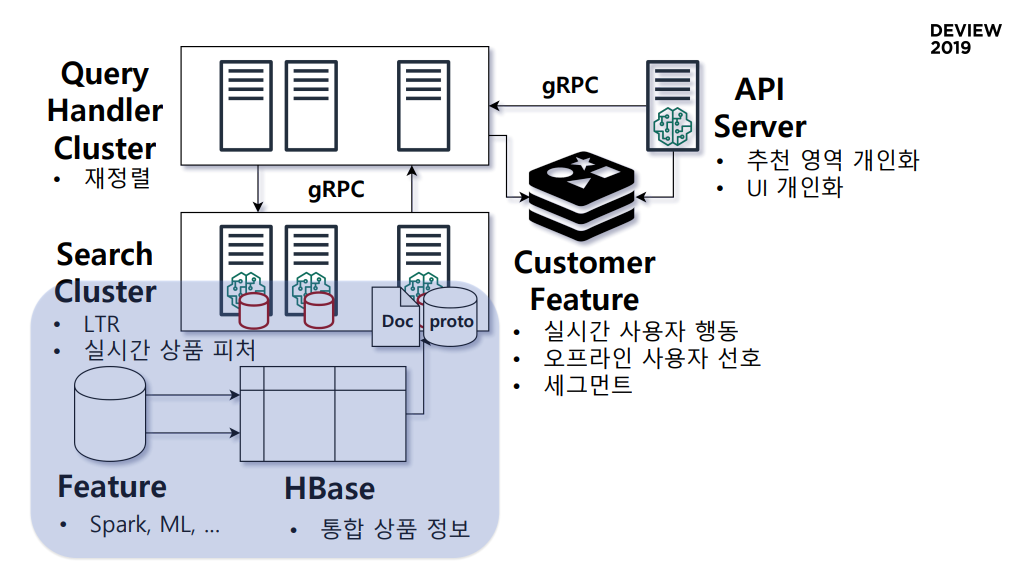
쿠팡 추천/검색 플랫폼 형상 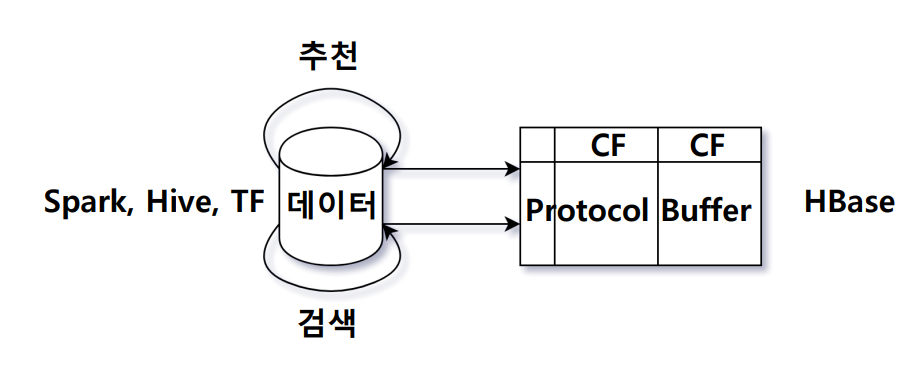
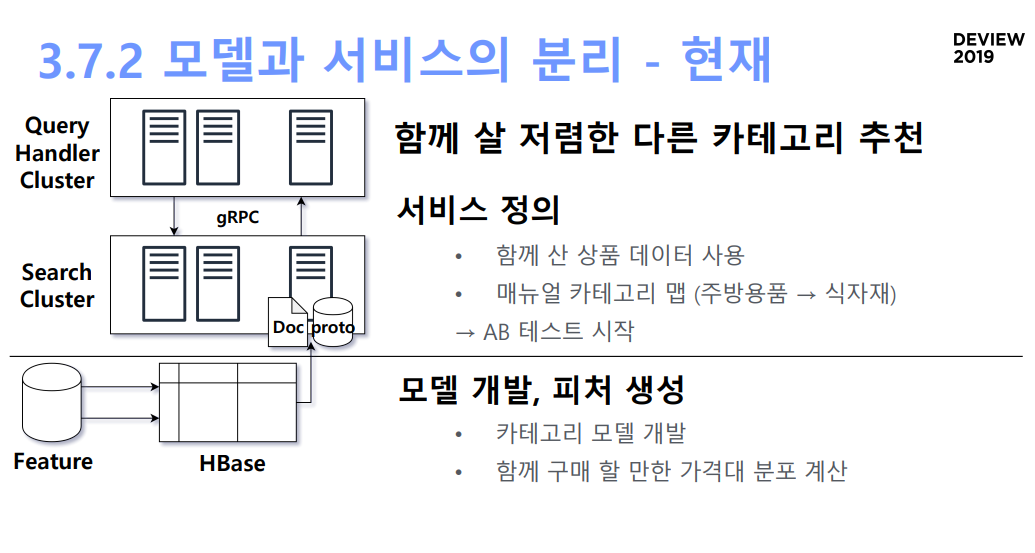
3.2 중앙화된 상품 정보
- 인덱싱
- 이런 정보들을 hbase에 넣어서 꺼내서 씀
- doc: 어떤 상품에 검색되어야하나?를 payload로 reverse indexing
- 필터나 부스팅은? 카테고리, 성인상품 여부, 배송이 로켓인지 여부 등을 사용
- proto라는 영역은 인덱싱에는 사용하지 않으나 상품에대한 정보를 서빙타임에 써야할 때가 있는데, 그 때 key-value 구조로 프로덕트 메시지, 프로덕트 버퍼 그대로 인메모리에 올릴수 있는 작은 스토리지
- 이렇게 만든 doc과 proto를 search cluster에 올리게 됨. 이 search cluster는 현재 context(유저, 시간, 카테고리..)와 관련된 상품을 찾고, 적당한 조건으로 필터링한 뒤, 점수에 따라 정렬하게 됨.
- 여기서 필요한 context는 Query Handler Cluster가 context를 정의해서 search cluster에 전달을 해줌. 이 QHC는 search cluster의 랩퍼, 혹은 검색 서버의 API라고도 볼 수 있음.
- Query Handler Cluster
- 서비스 정의: 냄비와 함께 살 할인 식품
- filter: 식품 카테고리
- boost: discount_rate
- 추가정렬: 고기, 생선, 야채를 번갈아가며 보여주기
- 빠른 서비스 개발
1) 피처 조합과 가중치에 따라 새로운 서비스
2) 필터로 새로운 추천 서비스를 만들 수 있음 (ex, 요즘 인기있는 ㅇㅇㅇ, 특가 상품)
3) 검색결과를 필요에 따라(비즈니스 중요도에 따라) 새롭게 정렬할 수 있다 (ex, Round robin)
- 모델과 서비스의 분리
- 모델 개발: 모델 개발에서는 좋은 피처를 만들기 위해 노력
- 서비스 정의: 있는 피처를 어떻게 쓸지 고민
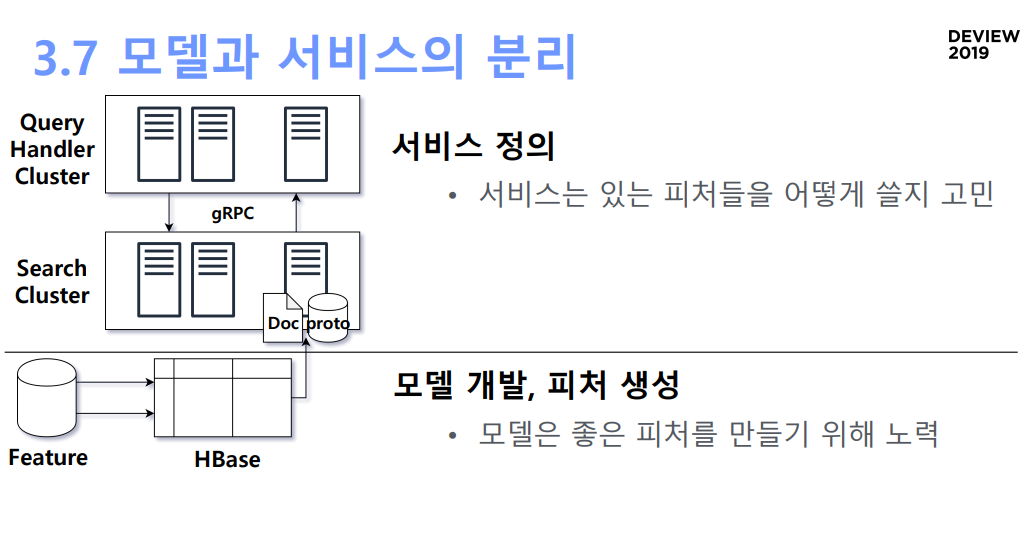
모델과 서비스의 분리 [기존]
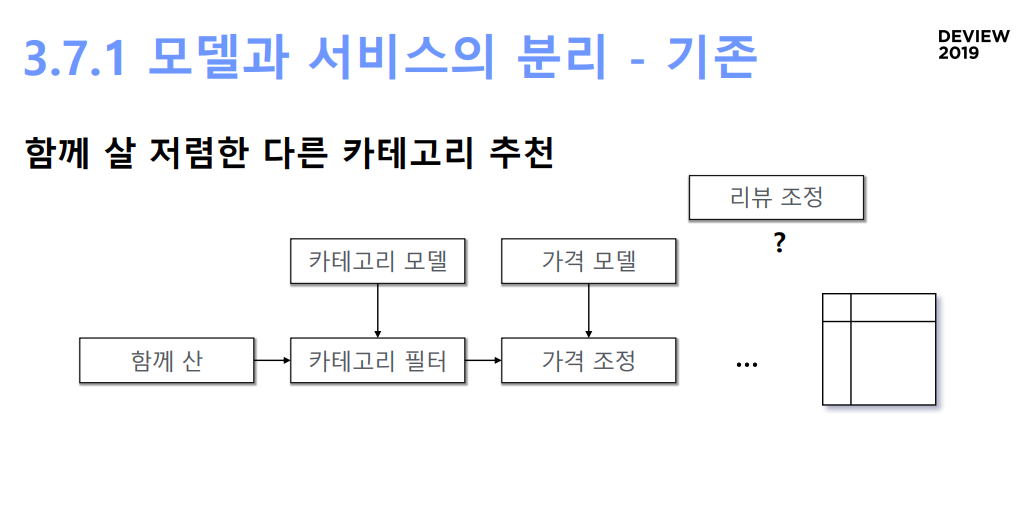
- 함께 살 저렴한 다른 카테고리 추천: 함께 산 아이템 추려내기 -> 카테고리 필터 -> 가격 조정 -> 최종 테이블
- 이 경우 카테고리 모델, 가격 모델 등 새로운 추천 모델이 생기면 새로운 데이터파이프라인을 붙여야함.
- 새로운 모델 출시에 한달이 걸림
[현재]
- 서비스 정의: 함께산 상품 데이터 사용, 매뉴얼 카테고리 맵 (주방용품 -> 식자재) -> AB테스트 시작 (하루만에 가능)
- 모델 개발, 피처 생성: 카테고리 모델 개발, 함께 구매할만한 적절한 가격 분포계산
- 모델 개발이 완료되면 생성된 피처를 사용해 바로 AB 테스트 시작 가능, 이 테스트 결과를 토대로 새로운 피처 개발
- 서비스가 망하더라도, 서비스 정의 측면에서는 쿼리 튜닝으로 새로운 서비스를 만들 수 있을 것이며 모델 단에서는 만들어진 피처를 그대로 가져갈 수 있을 것
- 변화
- 추천 영역의 수 7배
- 추천 노출, 클릭, 구매 매우 크게 증가
- 변화 요약 1) 빠른 서비스 개발 2) 비즈니스 상황에 대한 빠른 대처 3) 피처의 다양한 방면으로의 활용
더 나은 추천을 위해
4. Learning to Rank
- 쿼리 튜닝: 피처가 갈수록 늘어갈텐데, 이를 매번 수작업으로 쿼리 튜닝하는 작업은 비효율적임 -> F(모델점수, 카테고리점수, 가격, 상품평, 할인, 피드백…)
- Learning to Rank를 도입하는 작업이 필요 -> 즉, 쿼리튜닝을 모델에게 맡기자 (여기서 모델은 피처 생성 모델과는 다름)
- 상품 피처 + 상품 연관성 피처를 합하여 모델에 투입, 그 결과로 score가 나오게 될 것.
- 이렇게 만든 모델은 search cluster의 각 shad에 로드되고, search cluster에서는 자신이 찾은 후보자들의 정의된 피처를 사용해 reranking
- 고객 레이블은 고객의 반응이므로, 같은 피처를 사용하더라도 다른 결과를 낼 수도 있음. consistent하지 않은 결과가 가능. 결과가 이상하게 나올 수도 있음.
- 따라서 리뷰나 CTR 등으로 세밀하고 휴리스틱한 조정이 필요
- Learning to Rank 모델 학습
- 어떤 피처로 추천을 제공했고, 그 추천의 결과가 어땠는지를 쌓아놓아야 함 (실시간 로깅)
- 즉흥적으로 새로운 피처를 만들어서 추천을 제공한 경우 이 피처는 로그로 추적이 안될 것임. 이 경우 쌓인대로의 로그를 쿼리를 재현한뒤 crawling center로 backfill해줌
- 레이블로는 유저 반응을 사용하는데, 이커머스에서 고객 반응은 하루만에 일어나지 않음(음악의 경우 바로 일어나지만). 따라서 이에 대한 기록을 잘 남겨놓아야함
- 피처 엔지니어링이 매우 중요해짐. 모델이 잘 이해할 수 있는 피처를 만들어 주어야 함
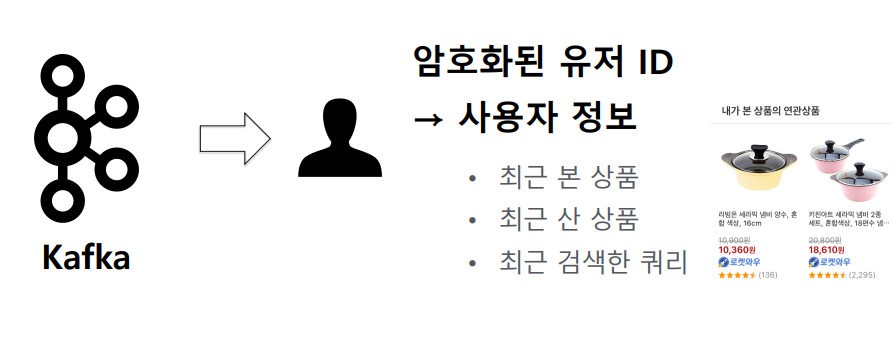
실시간 유저 정보
- 실시간 사용자 피처
- 쿠팡 카프카에 유저의 로그가 남는데, 실시간 로그를 컨슘해 암호화된 유저 키로 어떤 액션을 했는지를 남김
- 최근 본 상품, 최근 산 상품, 최근 쿼리..
- 이 정보를 기반으로 연관 추천을 제공
- 이러한 실시간 정보 뿐만아니라, 과거 기록을 기반으로 인덱싱을 해둠.
- 유저 자체의 피처 뿐만아니라 유저와 상품의 연관성 피처를 만들고 싶음. 이 때 모든 유저와 모든 아이템에 대해 연관성 피처를 만드는 것은 매우 비용이 큼.
- 따라서 유저를 세그로 나누어 각 세그별 아이템에 대한 연관성 피처를 만들어줌.
- 여기서 피처들은 마케팅에서 자주 사용하는 RFM 스코어(분위수로 표시한), 접속 기기, 부모 여부, 애완동물 여부, 차량 여부, 성별(패션 빈도 등 사용) 등을 사용함.
- 이렇게 만든 피처를 기반으로 세그를 나누고, 상품별 퍼포먼스 스코어를 뽑음. 원피스 상품의 경우에는 20대 남성 세그에는 성능이 안좋을 것임
- 신선식품의 경우 아이폰 유저에겐 퍼포먼스가 안좋음(!!)
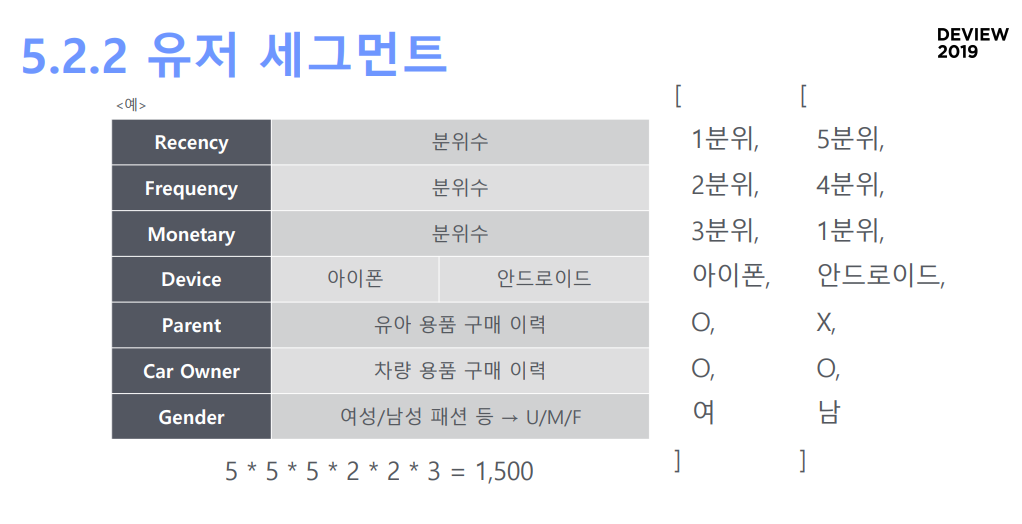
유저 세그먼트 정보
- 실시간 상품 피처
- 상품에 대한 대부분의 피처가 hbase에 있지만, 이들은 오프라인으로 계산되고, search cluster indexing 역시 실시간이 아님.
- 따라서 상품의 실시간 퍼포먼스를 알기는 어려움(최근 1시간 퍼포먼스..)
- 카프카를 컨슘해서 어떤 추천 영역에 얼마나 나왔고, 얼마나 좋은 반응을 얻었는지를 계산하고 있음.
- 상품 피처처럼 redis를 사용하기는 어려움. 특정 리퀘스트가 있을 때 상품에 대한 피처는 암호화된 유저 아이디를 기반으로 한번만 조회하면 됨.
- 반면 후보 상품에 대한 실시간 추천은 후보가 되는 수백개의 상품에 대해 모두 필요함. 그래서 redis를 바로 사용할 수는 없고, 각 shad 위에 조그만 in memory storage를 올려서 near real time으로 운영.
- 즉 search cluster에서 자기가 가지고 있는 후보 상품을 찾으면 그거에 대해서 실시간으로 어떤 반응을 보이는지도 가져오고, proto와 search document을 이용해 정보고 가져오고, learning to rank 모델을 사용해서 reranking한 뒤 query handler cluster에 올려줌.
- 실시간 개인화
- 이제 사용할 수 있는 피처는 상품 피처에 고객을 고려한 피처까지 더해짐.
- 상품연관성피처(소스 상품에 따라 달라짐)로는 모델이 계산한 연관성 점수, 가격 차이, 같은 카테고리인지 여부, 이미지 유사도
- 상품 피처: 상품평 개수, 별점, 트렌딩 모델 점수, 실시간 피드백..
- 사용자 연관성 피처(추천 후보 상품과 유저와의 연관성): 세그먼트별 피드백, 선호 카테고리 여부, 선호 가격대..
- 이러한 피처를 learning to rank이 학습함으로써 사용자 정보, 상품 정보, 실시간 정보를 모두 사용함으로써 실시간성, 개인화성을 확보
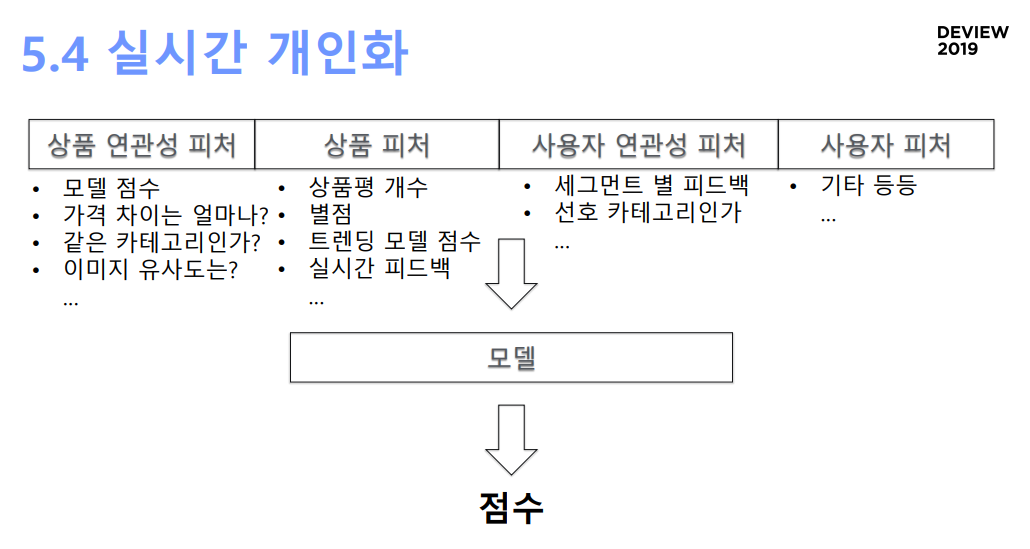
실시간 개인화를 위한 피처 개요
- 추천 영역 개인화
- 각 유저가 어떤 추천 영역을 위주로 보고, 어떤 추천 영역을 보지 않는지 피드백을 사용하면, 추천 영역 자체를 랭킹할 수 있음.
- 사용자 피처와 피드에 대한 피드백을 종합하여 피처벡터로 만들고, 이를 learning to rank 모델에 학습시키면 그 점수로 어떤 추천 영역을 노출할지 말지를 결정할 수 있음
- Feature Selection
- 모든 피처를 사용하는 것이 성능은 더 좋을 수 있음
- 그러나 적게 유지하려고 노력함.
- 이는 새로운 피처를 추가했을 때 모델의 판단이 어떻게 달라지는지 이해하기 어렵기때문
- 또, 모두 사용하면 문제가 생겼을 때 어떤 피처를 우선적으로 개선해야하는가, 모델을 어떻게 디버깅하고 개선해야하는가를 파악하기 어려움.
- 변수 중요도나 shap을 사용하여, 중요 피처 혹은 피처간의 상관관계를 파악함.
- 또, 분포를 확인함으로써, 고르게 분포한 피처가 더 바람직하다고 판단함(0에만 몰려있으면 배제)
5. 요약 & 팁
- Tip & Summary
- 먼저 “Feature” 단계에서 spark, ML(tensorflow..) 추천모델을 사용해 상품 연관성 등 피처 생성, 상품 자체의 피드백 생성
- 이 피처를 Hbase에 넣어서, 검색팀과 함께 종합 상품 정보를 관리, key-value로 가져다 쓸 수 있게 스토리지 준비
- Search cluster에는 Learning to Rank 모델을 메모리에 올려놓고, 실시간 상품피처를 각 shad에 맞게 쪼개서 로드
- Query Handler Cluster에서는 서비스를 정의, Search cluster에 어떤 쿼리를 던질지, 무슨 상품을, 어떤 필드를 사용해서 찾을지를 정의해 Search Cluster에 보냄.
- 이 때, customer feature를 사용해서 개인화된 서비스를 정의하기도 함.
- API 서버에서도 추천 영역 개인화를 위해 customer feature 사용
- Raw feature(# reviews, rating) vs Processed Feature(rating score)
- Learning ro Rank 모델을 학습함에 있어 raw data를 쓰느냐, 스코어를 만들어 쓰느냐에 대한 질문이 있음
- raw feature를 쓰면 각 피처가 어떻게 모델에 영향을 미치는지는 잘 알 수 있지만, correlation이 높은 피처가 많이 남아있을 수 있음
- LTR(Learning to Rank) 모델의 초기에는 raw feature를 사용하되 시간이 흐름에 따라 높은 correlation을 갖는 피처를 정리하는 작업이 필요하다고 생각
- 복잡한 LTR 모델 (RNN/CNN) vs 단순한 LTR 모델 (DT, MLP..)
- 단순한 모델을 채택함. 피처 선택에 신경을 써서 피처 수를 낮게 유지하기도 하고, 각 픽셀의 RGB가 각각 피처가 되는 이미지와는 달리 상품추천에서는 피처의 값이 적은 편임.
- 같은 피처 값을 갖더라도 유저 반응은 다를 수 있음. 즉 레이블에 일관성이 없다는 이야기임.
- 그래서 복잡한 모델로 좋은 metric을 뽑아내는 접근은 추천 영역에서는 맞지 않다고 봄.
- 피처 엔지니어링 vs 파라미터 튜닝
- 피처 엔지니어링이 더욱 중요. 더 도움이 되는 피처를 만들어 나가는 것이 유효하다고 봄
- 파라미터 튜닝은 리즈닝이 잘 안됨. (내 의견: 오프라인 메트릭을 최적화해도 그게 바로 맞춰지지는 않을테니까)
- 추천으로 인해 생길 수 있는 편향을 보정하고, 유저의 true preference를 찾을 수 있는 피처를 찾기 위해 노력
6. Q & A
- 콜드 스타트
- 클릭 순간부터 정보가 쌓이므로 바로 추천 제공
- 초기에는 유저의 선호가 급격히 달라짐
- 선물 추천을 비즈니스 적으로 고민중?
- 그렇다. 그러나 한 가족이 한 아이디를 쓰는 경우도 있어서 어려움
- 사용자의 가치관을 기반으로?
- 가성비, 브랜드, 배송 방식은 사용중
- 시스템 평가 지표
- 사이클이 매우 빠르기 때문에 오프라인 메트릭은 사용하지 않고 그냥 바로 AB를 돌림
- LTR 모델은 어떤거?
- Decision Tree
- 피처의 형태?
- 특정 상품에대한 특정 플롯 값 하나면 됨. 카테고리도 피처로 만들 수 있음. 선호하면 1, 아니면 0 이런 식으로
- 로그가 엄청날텐데 DBMS는 어떤 것?
- 사용자 액션 로그는 분산 HDFS에 저장(카프카) 이 데이터를 모두 컨슘해서 하이브에 저장, 하이브에 있는 것을 스파크로 꺼내 씀. 스파크도 되고, HiveQL로 꺼내 쓰기도 하고. 쓰는 사람 마음
- AB테스트시에 신뢰도있는 실험결과를 위해 신뢰도 지표를 따로 보나? 결과로 클릭률, 매출을 본다고 했는데 실험 결과 클릭은 올랐는데 매출이 떨어지면 어떻게 하는지. 이 이후에 추가 분석을 한다면 어떻게 하는지?
- 컨피덴셜한 질문. 유저에게 얼마나 노출됐는지 계산할 수 있고, A B 그룹간에 얼마나 유의미하게 차이를 보이는지를 p value를 계산할 수 있음. 이를 기준으로 significance 계산
- tradeoff가 있기는 하지만, 지표가 다 좋아져야 적용함.
- 서치클러스터의 스택?
- 추천팀이 자체적으로 관리하지는 않고, 서치 클러스터를 관리하는 팀이 있음. 쏠라를 조금 고쳐서 씀
- 같은 세그에 있으면 같은 결과를 보이나?
- 아님. 세그 외에 다양한 피처들이 있기 때문임
- 피처 선정은 EDA로 하나?
- 피처를 뽑는 것은 굉장히 엔지니어링이라기 보다는 경험적인 분야인듯. 그래서 논문도 보고, 물어도 보고 하면서 피처 개발을 해나감
- AB 샘플군은?
- 샘플 안뽑고, 기존 유저를 반으로 잘라 사용 ㄷㄷ
- 기존 시스템을 현재 시스템으로 옮기는데 얼마나 걸림?
- 처음 만들 때는 세달, 서치에서 만든 플랫폼을 옮겨오는데 한달 정도 걸린듯. 그 이후 계속 개선하는 작업 (LTR 도입 등)
- 유저입장에서는 개인화에 따라 선호할만한 상품을 보여줄텐데 플랫폼입장에서는 다양한 상품을 고르게 보여주는 것도 중요할 듯. 특정 상품에 매출이 편향되는 현상을 어떻게 방지?
- 매우 중요한 질문. 유저 선호를 이용하면서 상품추천에 편향되게 됨. 논문도 있음. 유저 선호를 사용하는 naive estimator는 regret이 optimal하게 수렴할 수 없다는 내용이었음.
- 그래서 유저의 true preference를 찾아내기 위한 장치를 도입함. 가령 첫번째 위치했다고 클릭하는 현상을 보정하기 위해, 첫째 위치한 애들 중에 못하면 뒤로 보냄. 꼴찌로 보여준 애들 중에 잘하면 앞으로 보냄. 아래 있는 상품에게 이익을, 위에 있는 상품에게 불이익을 줌
- 추천 영역이나 트렌드에 대해서 타 직군에서 모니터링할 수 있는 시각화 툴이 있나?
- 그렇다. 우리도 필요함. 어떤게 나가지? 안나가지? 이걸 보려면 필요함.
- 점수로 우선순위 세우는 일에 문제는 없었는지, 기준 정의는 어떻게 했는지, 속도 이슈는 없는지
- LTR의 레이블을 뭐로 쓰느냐 이야기인거 같은데, 비즈니스 목적에 따라 다름. 체류시간일수도 있고..
- 레이블을 뭐로 잡느냐가 AB test에서 다른 메트릭 안떨어뜨리고 전반적으로 좋은 모델을 만드는게 굉장히 중요한 작업
- 사용자에게 특화된 추천과 상업적으로 특화된 추천 중 어떤거?
- 전자를 추구함.
- 추천이란 사용자가 의사결정을 빠르게 내릴 수 있도록 돕는 기능이라고 생각함. 그게 플랫폼에도 장기적으로 좋은 것임
- fake성 이름은 어떻게 필터링?
- 우리가 안함.
- AB test하는 타이밍
- 피처 하나 만들면, 모델 새로 만들면.
- 해보고 결과 안좋으면 끔.
- 유저 세그 관리는 어떤식으로? 어떤 데이터로?
- 법적 이슈가 있음. 데모 정보 등을 그렇게 많이 사용하지 않음.
- 클릭로그 등을 이용해서 추정하고 싶기는 하는데, 어려움
- 들어올 때마다 같은 상품을 보여주는 것보다 여러 상품을 보여주고 싶을 것 같은데 어떻게함?
- 앞서 살펴본 user preference 관련 논문에서도 랜덤으로 노출시키는 것이 매우 좋은 방법이라고 말하고 있음.
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요. 내용에 대한 지적, 혹은 질문을 환영합니다.
출처
https://tv.naver.com/v/11212875#comment_focus https://deview.kr/2019/schedule/276#
Leave a comment