
[RecSys] 뉴럴넷 기반 추천시스템 서베이 페이퍼 리뷰
뉴럴넷 기반 추천 시스템 서베이 페이퍼 리뷰
A Survey on Neural Recommendation: From Collaborative Filtering to Information-rich Recommendation 논문에서 정리한 뉴럴넷 기반 추천시스템의 큰 흐름에 대해 알아봅니다.
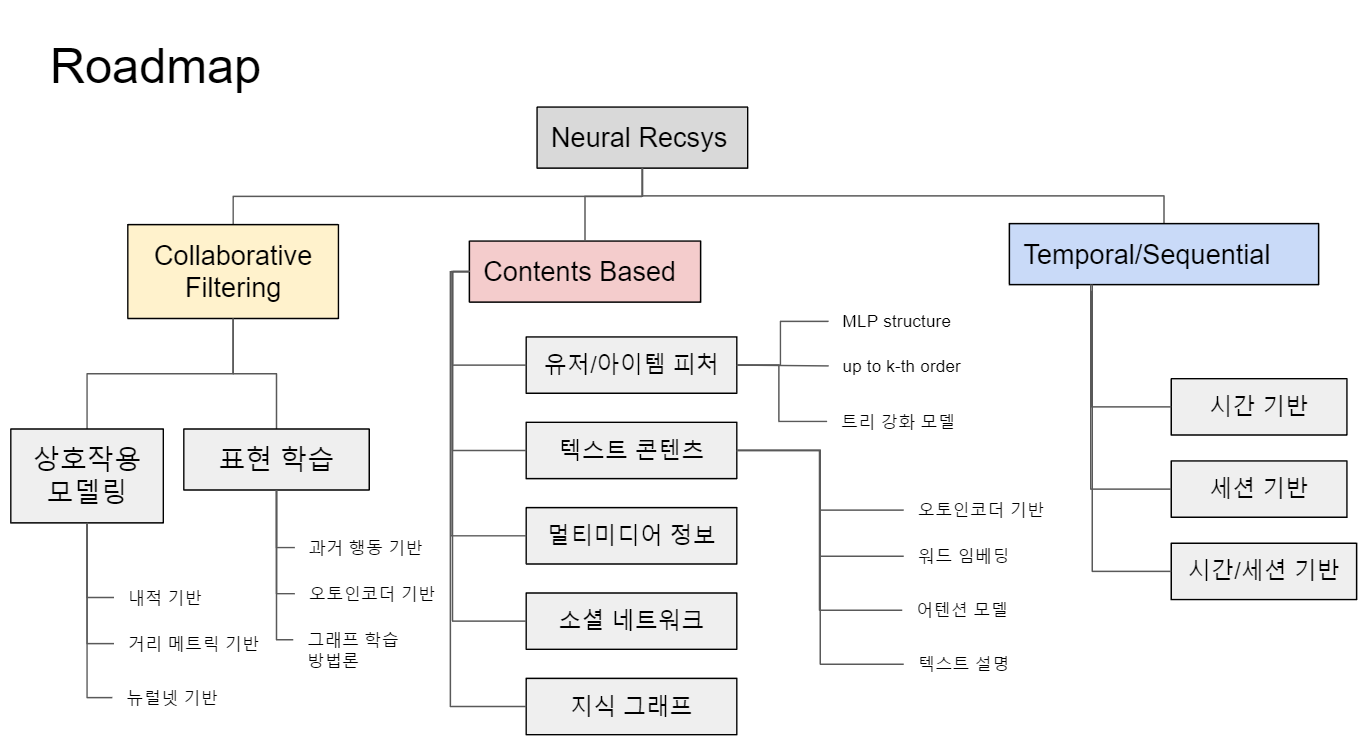
1. 본 논문에서는 크게 3가지 접근법으로 나눔: Collaborative Filtering, Contents Based, Temporal/Sequential
2. 자연어, 그래프 등 비정형 데이터를 다루는 신경망 모델의 접근법이 추천 분야에 활발히 적용/응용되고 있음
3. 각 방법론이 발달한 배경을 통해 실제 문제 상황에서 마주할 수 있는 다양한 형태의 데이터와 비즈니스 환경에 적합함 모델을 취사선택할 수 있음
Contents
1. 들어가며
motivation
하루가 다르게 새로운 방법론이 등장하는 머신러닝 분야에 몸 담고 있는 엔지니어에게, 빠르게 변화하는 흐름을 그 때 그 때 따라잡아야한다는 부담감은 일종의 끝나지 않는 과제처럼 마음에 머무르고 있을 것입니다. 한동안 현업에 치여서 이러한 동향을 놓친듯 할 때 참고하면 좋을 것이 바로 survey paper인데요.
본 추천시스템 서베이 페이퍼는 2021년 상반기에 공개된 페이퍼로, 강화학습이나 GNN처럼 특정 방법론에 한정되지 않고 어느 정도 일반적인 방법론을 두루 다루면서도 최신성이 좋다는 점이 매력적이라 한번 정리해 보았습니다. 이 포스트를 통해, 최근 학계에서 주목받는 알고리즘들에 대한 개략적인 흐름을 살펴보고, 각 방법론이 유용한 데이터/비즈니스 상황에 대해 표로 정리해 보려고 합니다. 이는 개인적인 관찰과 의견에 기반한 내용으로, 이 글을 읽으시는 분들의 조언과 지적이 필요합니다.
이 논문에서는 크게 3가지의 접근법으로 나누어 딥러닝 기반 추천 알고리즘을 나누고 있습니다.
1) Collaborative Filtering
2) Contents Based
3) Temporal/Sequential
이 외에도 여기서 제시하는 Taxonomy에서는 다뤄지지 않거나 별도로 분리되지 않는 GNN, Context-aware, 강화학습 기반, Conversational Recommender Systems(CRS), Multi-armed Bandit 등 다양한 추천 방법론의 갈래가 존재합니다. 각각의 주제에 대해 다루는 서베이 페이퍼가 공개되어 있으니 관심있는 독자 분들은 참고하셔도 좋을 것 같습니다.
덧붙여, 방법론의 별칭 옆에 노란색 작은 숫자 ex) SVD++ [3881]는 글을 작성하는 당시까지의 피인용수를 적어두었습니다. 해당 논문이 얼마나 큰 관심을 받았는지 참고하는 용도로 보아주세요.
2. Collaborative Filtering Models
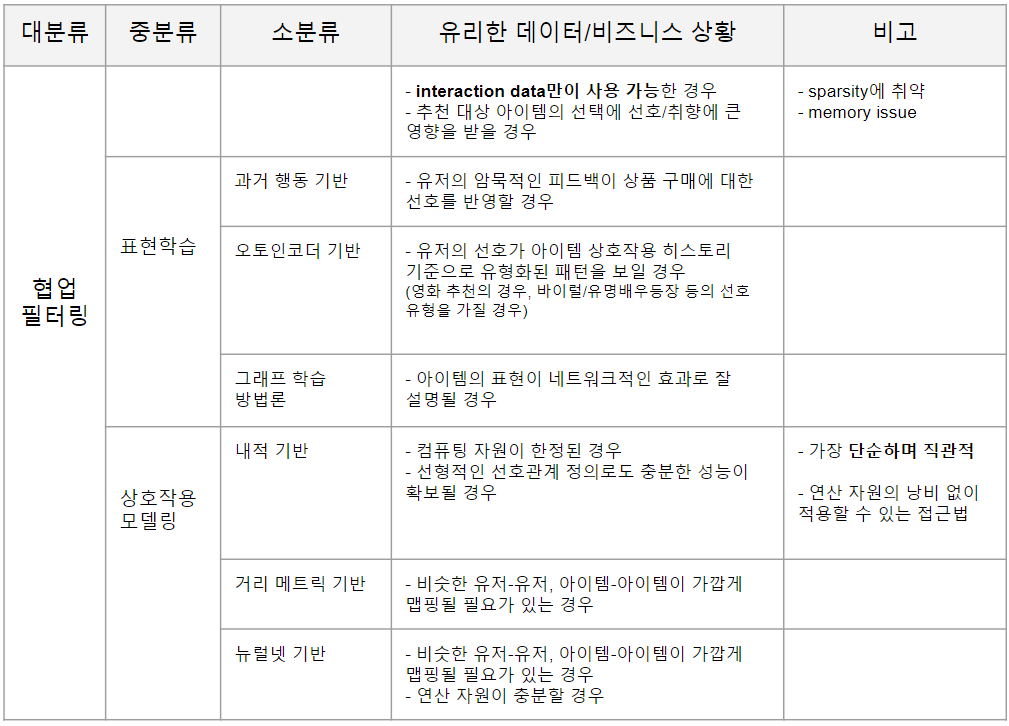
Collaborative Filtering (CF, 협업 필터링) 기반 모델의 아이디어는, 모든 유저의 협업적인(collaborative) 행동을 활용해, 타겟 유저의 행동을 예측하자는 것입니다. 직관적으로는, “너랑 비슷한 걸 좋아하는 애들은 이걸 좋아했으니 너도 좋아하겠지” 라는 가정으로 추천을 제공하는 접근법이라고 할 수 있습니다. 초기에는 유저/아이템 기준으로 행동의 유사도를 메모리 기반으로 직접 계산하는 방법론이 제안되었는데, 그 이후(대략 Netflix Prize에서 SVD 모델이 우승한 이후) Matrix Factorization 방법론이 각광받았습니다.
해당 논문에서는 CF 기반 모델을 크게 2가지로 나누었습니다.
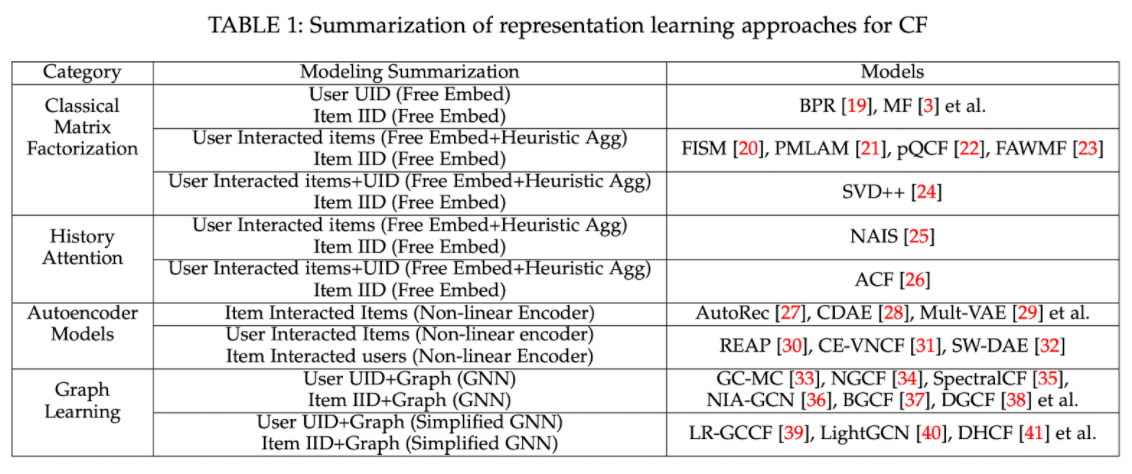
1) Representation Learning (표현 학습)
2) Interaction Modeling (상호작용 모델링)
2.1 Representation Learning (표현 학습)
이 방법론은, 유저와 아이템을 각각 잘 표현하는 임베딩 행렬을 만들어 내는 접근법입니다. 유저와 아이템의 interaction 정보가 주어졌을 때, 이들을 one-hot이 아닌 dense한 representation으로 표현해 냄으로써 유사한 아이템과 유저를 찾아냄으로써 특정 유저가 좋아할만한 상품이나 컨텐츠를 추천해 줄 수 있겠죠.
입력 데이터와 처리 방식에 따라, 3가지로 나눌 수 있습니다.
1) 과거 행동 기반 Attention Aggregation model
2) 오토인코더 기반 모델
3) 그래프 학습 방법론
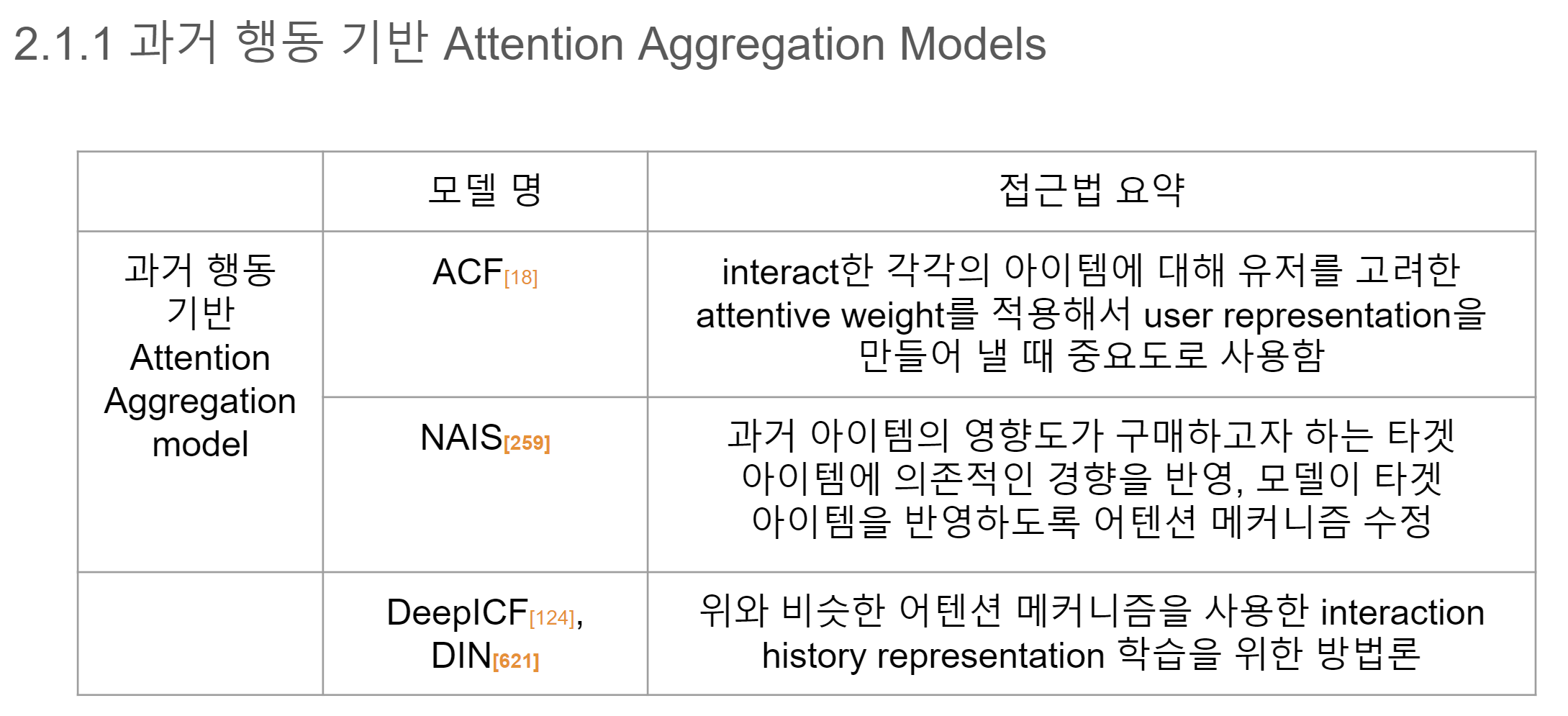
2.1.1 과거 행동 기반 Attention Aggregation Models
과거의 one-hot 유저 ID와 아이템 ID를 받는 고전적인 latent factor model들은 각각의 유저와 아이템을 자유 임베딩(free embedding)에 맵핑시켰습니다. 이런 방법 대신에, 더 나은 유저 representation 모델링을 위해 유저의 과거 행동 기록을 사용하는 것이 제안되었는데요.
- FISM [471], SVD++ [3881] …
그런데 유저의 선호를 모델링함에 있어 각 과거 아이템은 다른 기여도를 가질 것이라는 지적이 제기되었습니다. 이러한 문제를 해결하기 위해, Attention Mechanism을 결합한 방법론이 다수 제시 되었습니다.
- ACF(Attentive Collaborative Filtering) [18], NAIS(Neural Attentive Item Similarity model) [259], DeepICF(Deep Item-based CF) [124], DIN(Deep Interest Network) [621] 등
2.1.2 오토인코더(AutoEncoder, AE) 기반 표현 학습
오토인코더는 입력을 재복원하여 출력을 입력과 동일하게 만들어내도록 하는, 마치 장구의 모양을 띠는 네트워크를 말합니다.
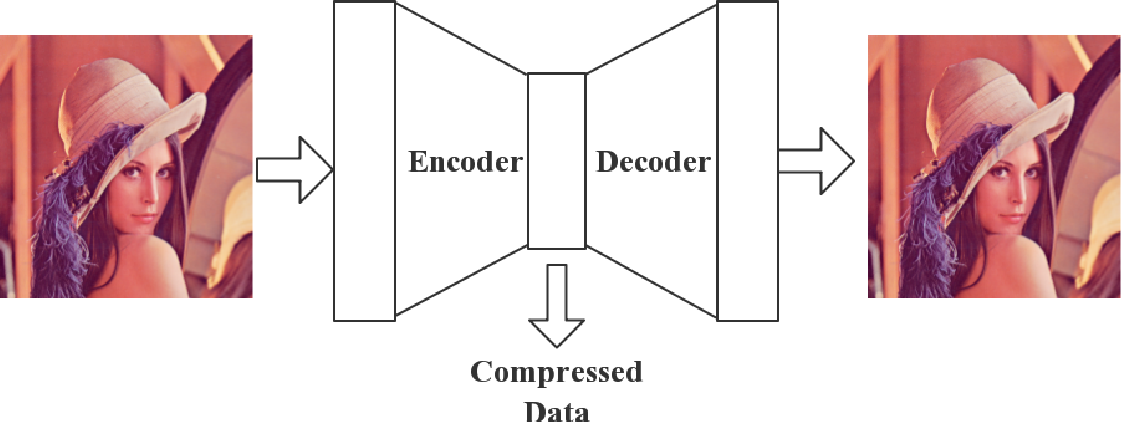
크게 인코더와 디코더로 나뉘어져 있는 이 네트워크는, 두 파트 사이의 병목 부분에서 입력 데이터의 잠재된 표현(latent representation)을 학습하게 됩니다. 입력된 정보를 잘 압축하는 역할을 하는 부분이 인코더이고, 이를 잘 풀어내어 원래의 형상으로 만드는 것이 디코더의 역할입니다.
데이터를 압축하여 데이터 샘플 간의 의미적인 정보를 잘 보존하는 잠재 표현을 만들어 내는데, 이를 활용해 가까운 유저와 아이템 사이의 관계를 잘 학습하여 추천에 활용하겠다는 것이 오토인코더 기반 표현학습의 전략입니다. 달리 말해, 유저와 아이템 사이의 의미적인 관계를 잘 보존하는 매니폴드(manifold)를 학습한다고도 할 수 있겠습니다.
오토인코더 기반 모델은 불완전한 user-item matrix를 입력으로 받아, 인코더로 각 인스턴스의 잠재 표현을 학습합니다. 반대로 디코더 파트에서는 잠재 표현을 기반으로 입력 값을 재복원하는 구조를 띠고 있습니다. 비슷한 접근을 취하는 방법론으로는, 딥러닝이 아닌 선형적인 모델을 사용하는 Matrix Factorization 류의 알고리즘을 들 수 있습니다.
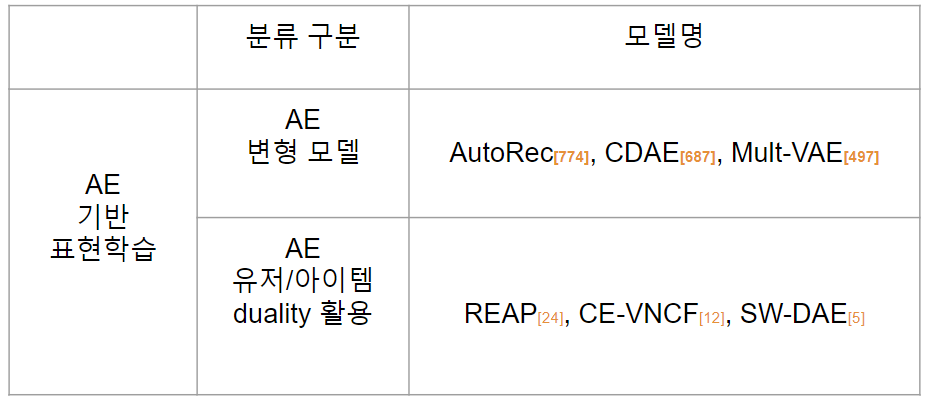
본 논문에서 AE 기반 모델을 두가지 카테고리로 분류하고 있습니다.
1) 오토인코더 변형 모델 (DAE, VAE): 유저 혹은 아이템 인코더를 학습하는 딥러닝 기법
2) 오토인코더의 유저/아이템의 이중성을 활용: 아이템과 유저 표현을 학습하는 두 병렬 인코더를 놓은 뒤, 아이템에 대한 유저의 선호를 모델링하기 위해 내적을 사용합니다.
2.1.3 그래프 기반 표현 학습
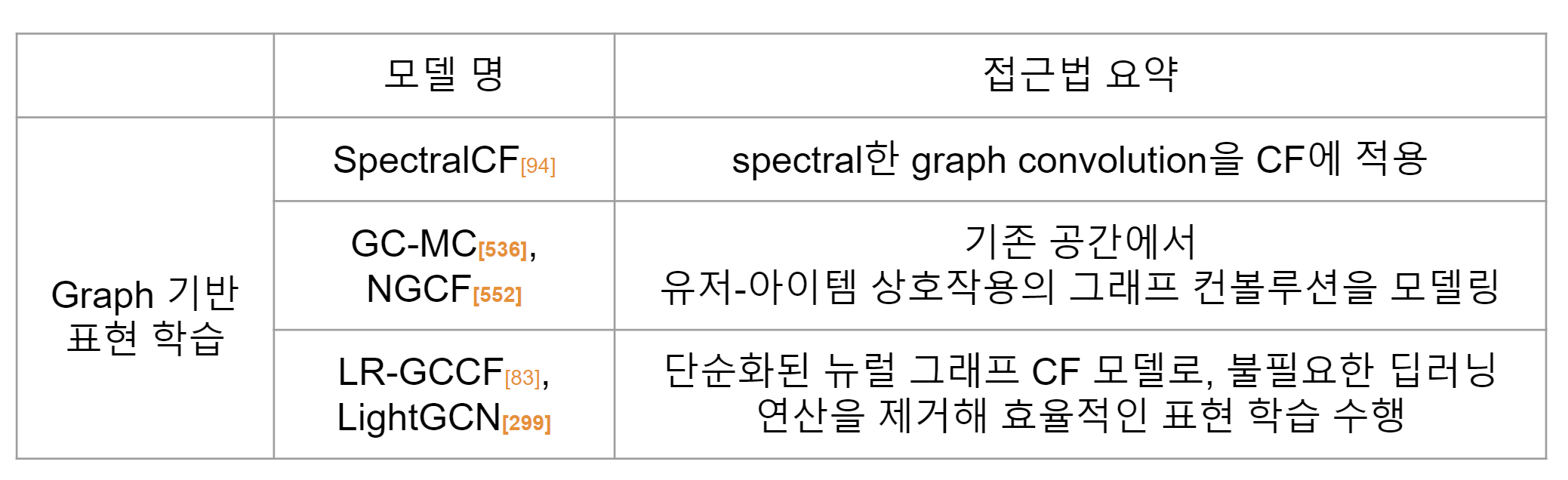
그래프 뉴럴넷(GNN)의 발전에 따라, 네트워크 내에서 한 개체가 갖는 관계적인 의미를 반영하여 추천에 활용하려는 움직임이 계속되고 있습니다. 여기서 살펴볼 방법론들은 그래프 구조를 활용해 추천에 적용하는 알고리즘들입니다.
유저-아이템 인터렉션 그래프의 관점에서, 개별 인터렉션(구매, 조회..) 기록은 해당 유저의 1계 연결(first-order connectivity)으로 볼 수 있습니다.
이를 자연스럽게 확장해보면, 고계 연결성(high-order connectivity)을 user-item 그래프 구조에서 찾는 방법을 생각해볼 수 있을 텐데요. 가령 2계 연결(second-order connectivity)은 같은 아이템을 똑같이 상호작용한 비슷한 유저로 구성되어 있을 것입니다.
GNN이 커뮤니티 내에서 그래프 구조를 모델링하는데 성공함에 따라, 유저-아이템 bipartite 그래프 구조를 모델링하는 연구가 진행되고 있습니다. 아래는 bipartite graph의 예시입니다.
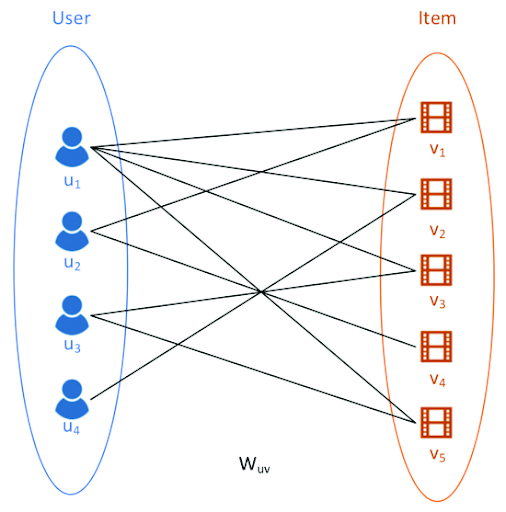
대부분 알고리즘의 작동 방식은, 유저-아이템 bipartite 그래프가 주어졌을 때 propagation을 통해 반복적으로 이웃의 정보를 교환함으로써 최종 아이템/유저 임베딩을 생성해내고, 이를 기반으로 유사도를 계산하여 추천을 제공하는 메커니즘을 따릅니다.
2.2 상호작용 모델링 (Interaction Modeling)
Representation Model (표현 학습 모델)에서 학습된 유저/아이템 임베딩이 있을 때, 이 임베딩에 기반해 유저의 타겟 아이템에 대한 선호를 추적하는 모델을 말합니다.
즉, 앞선 과정에서 유저와 아이템에 대한 표현을 잘! 학습한 뒤에, 이 표현을 기반으로 어떤 아이템이 어떤 유저랑 서로 가까울 것 같냐, 달리 말해 어떤 아이템을 유저가 좋아하느냐를 알아낼 수 있는 거리측도와 같은 기준을 찾는 모델을 말합니다.
Metric learning을 추천시스템에 적용한 접근으로 이해할 수 있을 것 같습니다. Metric learning이란, 인공신경망으로 데이터간 유사도가 잘 수치화된 잠재/임베딩 공간을 학습하는 방법론을 말합니다.
유저의 예측된 선호를 모델링하는 방식에 따라 3가지로 나누고 있습니다.
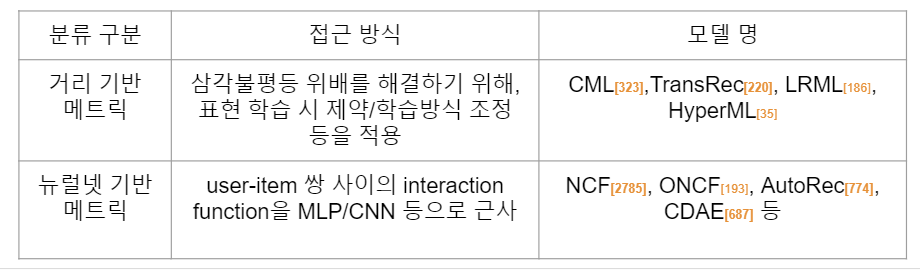
1) 전통적인 내적 기반 접근
2) 거리 기반 모델링
3) 뉴럴넷 기반 접근법
대부분의 경우에서는 내적을 사용한 방법론에 익숙하실 것입니다. 여기서는 내적의 한계와 그 개선을 위한 방법론을 소개하고 있지만, 결론적으로는 단순한 내적이 대부분의 경우에 효율적임을 알 수 있습니다. 특히 online으로 추천이 제공되거나, large scale의 연산이 필요한 경우처럼 시공간적인 연산상의 제약이 있을 경우 내적은 어느 정도의 성능을 포기하더라도 충분히 훌륭한 기능을 수행합니다.
논문에서 소개하는 내적 기반 접근의 한계점은 크게 두 가지입니다.
1) 삼각 불평등(triangle inequality) 위배
내적은 오직 유저와 과거 아이템의 표현이 비슷해지도록만 장려하고, 유저-유저와 아이템-아이템 관계를 유사하게 만드는 것에 대한 보장은 하지 못함.
2) 선형적인 상호관계만을 모델링함
유저와 아이템 사이의 비선형적인 복잡한 관계를 잡아내는 데 실패할 수 있음.
이러한 한계를 극복하기 위해, 다음과 같은 방법론들이 제시되었습니다.
3. Contents Based Models
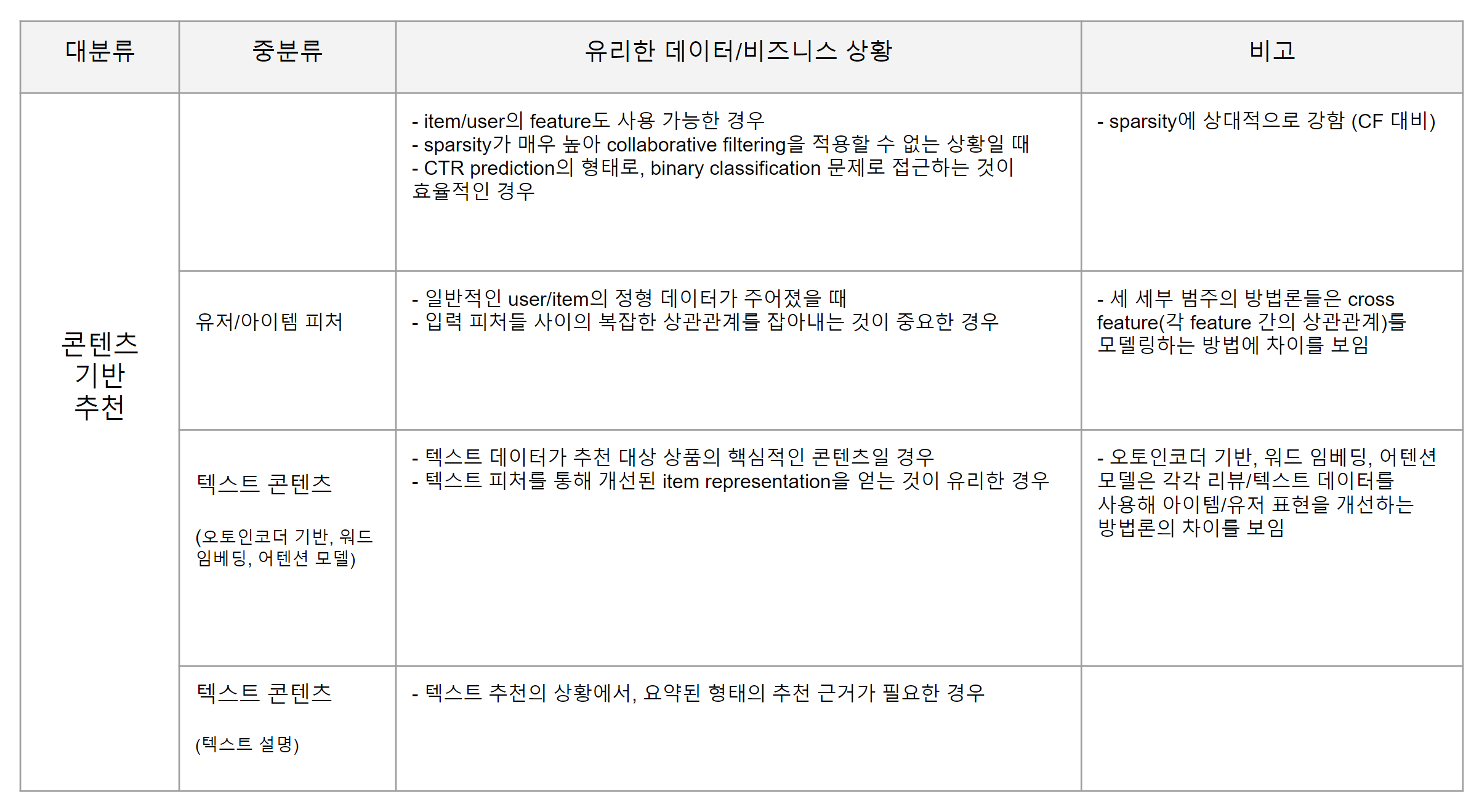
컨텐츠 기반 추천 모델(Contents Based Models) 은, 익히 아시다시피, 아이템 혹은 유저의 특징을 사용하는 것이 추천에 유용하지 않을까? 하는 접근에서 출발합니다.
Collaborative Filtering (CF)에서 학습된 아이템 representation은 유저들의 행동 패턴에서 협업적인 시그널만을 인코딩함으로써, 아이템이 갖는 의미적인 연관성을 무시하게 되는 문제를 갖는데요. 이를 개선하기 위해 상호작용 데이터 외에 보조적인 데이터를 활용하려는 방법론이 Contents Based Model이라고 할 수 있겠습니다.
여기서는 컨텐츠 기반 추천 모델을 크게 5가지 범주로 나누고 있습니다.
1) 유저와 아이템의 일반적인 특성
2) 텍스트 콘텐츠 정보
3) 멀티미디어 정보(오디오, 비디오, 이미지 등)
4) 소셜 네트워크
5) 지식 그래프
여기서는 시간 관계상 1)과 2) 까지만을 다루려고 합니다. 추후에 보강하도록 하겠습니다.
3.1 일반적인 피처 정보 모델링 (Modeling General Feature Interactions)
이 파트에서는, 유저/아이템에 부가적으로 달려있는 피처를 사용한 모델들을 다룹니다.

고전적인 피처 정보 모델링
뉴럴넷을 사용하지 않은 피처 모델링에는, 많은 분들이 익숙하실 Factorization Machine 류의 방법론이 있을 것입니다.
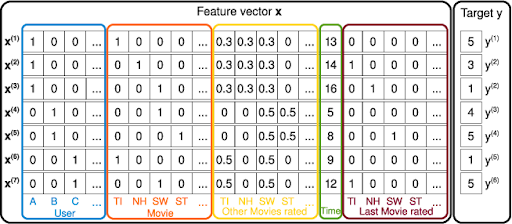
먼저 Factorization Machine [1926] 은, 일반적으로 매우 sparse한 feature 상황을 모델링하기 위해, 각 피처 i를 잠재 임베딩 v_i에 맵핑하여 모든 두 피처 인스턴스 사이에 2계 상호작용(second-order interaction)을 모델링합니다.
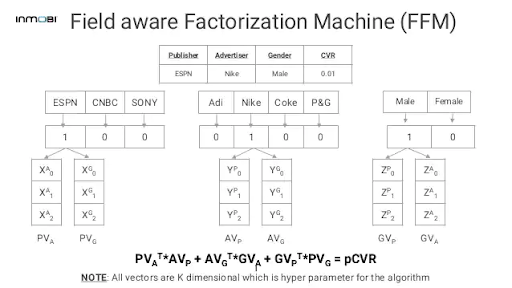
이를 개선한 알고리즘으로 Field-aware Factorization Machine [460]이 있습니다. 이는 필드를 고려하는 특성에 기반하여 복수의 잠재 임베딩을 사용하여 각 피처마다 학습 수행하는 모델입니다.
뉴럴넷 기반 피처 정보 모델링
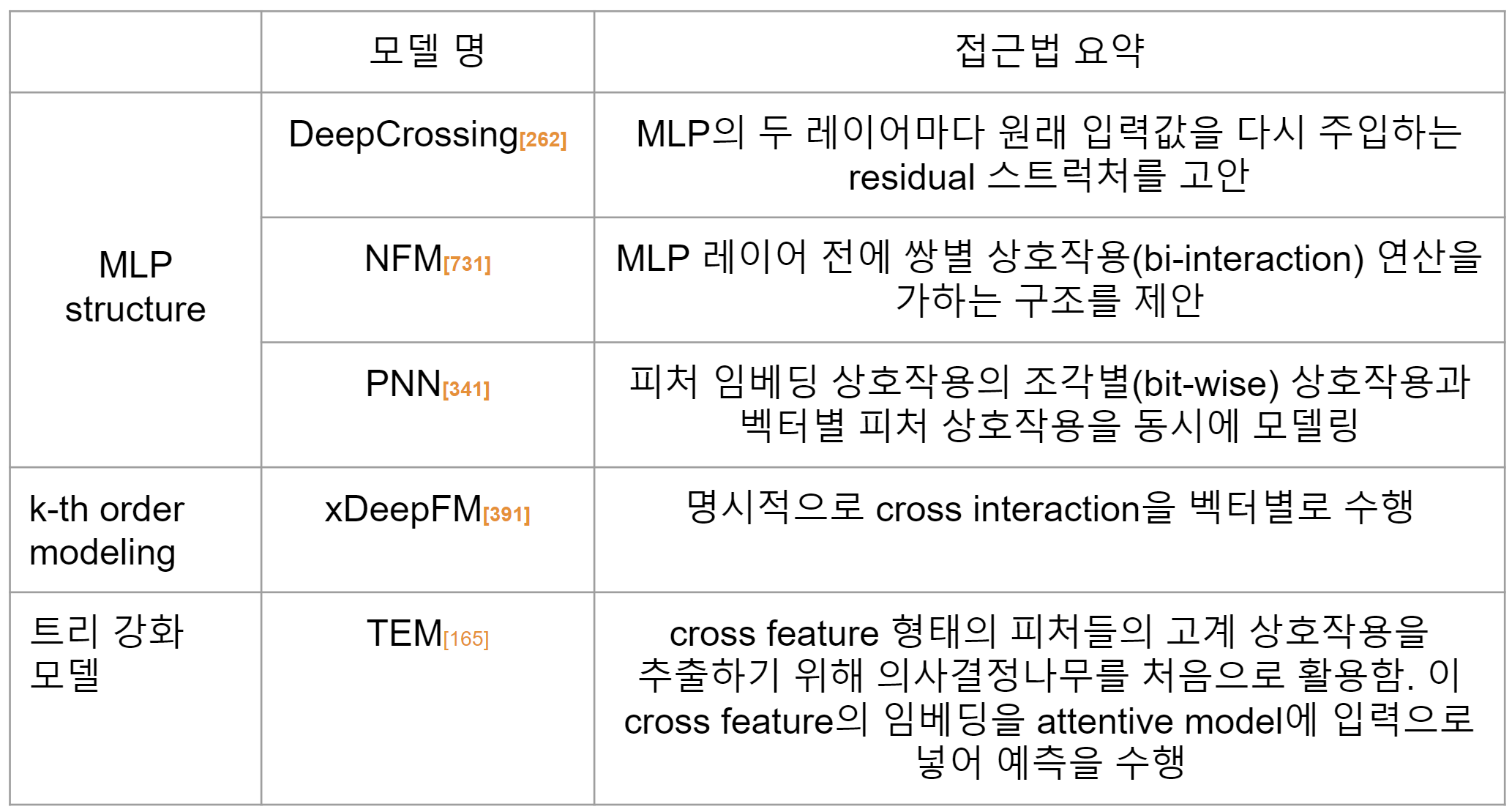
딥러닝 기반 방법론은 크게 3가지 범주로 나뉩니다.
1) 암묵적(implicit) MLP 스트럭쳐
2) 명시적(explicit) 최대 k차(up to k-th order) 모델링
3) 트리 강화 모델
3.2 텍스트 컨텐츠 모델링
추천에서 텍스트 컨텐츠는 크게 두가지의 입력 형태로 나눌 수 있습니다.
1) 컨텐츠 설명: 유저/아이템과 연관된 텍스트. (e.g. 기사의 요약본, 유저의 컨텐츠 설명 등)
2) 유저-아이템 쌍을 잇는 텍스트 정보: 유저가 달아놓은 아이템 태그, 유저가 남긴 상품 리뷰등
이러한 텍스트 컨텐츠를 활용한 모델링 방법론를 4가지의 카테고리로 분류하고 있습니다. 앞의 1)2)3)은 추천 자체를 어떻게 제공할지에 대한 고민이고, 4)는 추천의 설명가능성에 조금 더 집중한 방법론들이라고 이해하면 좋을 것 같습니다.
1) 오토인코더 기반 모델
2) 워드 임베딩
3) 어텐션 모델
4) 추천을 위한 텍스트 설명
3.2.1 오토인코더 모델
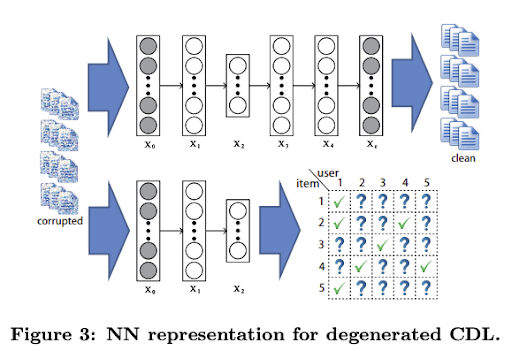
아이템 컨텐츠를 raw feature (Bag-of-words, item tag representation 등)로 다룸으로써, 오토인코더 모델을 활용해 아이템의 잠재표현(latent representation)을 학습하는 알고리즘입니다.
모델 예시는 다음과 같습니다.
1) CDL(Collaborative Deep Learning) [1383]
아이템의 콘텐츠 잠재표현과 협업 시그널을 동시에 학습
2) CVAE(Collaborative Variational AutoEncoder) [309]
VAE로 평점 행렬과 주변 컨텐츠 정보를 동시에 복원
3.2.2 워드 임베딩 활용
단어의 임베딩 값을 사용하여 컨텐츠를 나타내고, 이를 추천에 활용하는 기법이 제안되었습니다.
모델 예시는 다음과 같습니다.
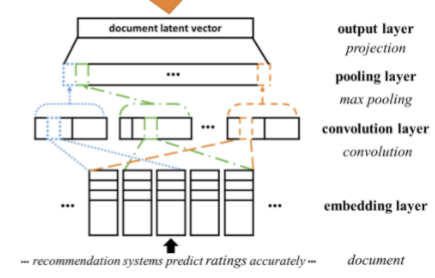
1) ConvMF(Convolutional Matrix Factorization) [540]
도큐먼트의 임베딩 매트릭스에 CNN을 적용하여 도큐먼트의 잠재표현을 학습, CF에 활용
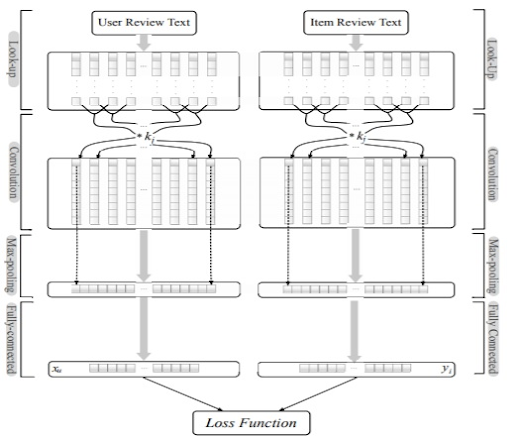
2) DeepCoNN [624]
리뷰 기반 추천을 위한 모델로, 2개의 병렬 TextCNN 스트럭처를 활용함.
하나는 사용자가 작성한 리뷰 컨텐츠를 활용해 사용자의 행동을 학습하고, 다른 하나는 아이템에 대해 작성된 리뷰에서 아이템 임베딩을 학습함.
3.2.3 어텐션 모델 (Attention Models)
다양한 자연어 어플리케이션에서 그 효과가 입증된 어텐션 메커니즘을 적용한 접근법입니다. 여러 컨텐츠 내의 단어들에 대해 선택적으로 가중치를 부여함으로써, 유저의 컨텐츠 선호 임베딩을 모델링합니다.
예를 들어, 트윗 내에서 등장하는 트리거 단어를 학습해 해시태그 추천을 제공하는 등의 경우를 생각할 수 있을 것입니다.
모델 예시는 다음과 같습니다.
1) DAML (Dual attention mutual learning between ratings and reviews for item recommendation) [56]
듀얼 어텐션 스트럭처를 사용, 유저와 아이템 표현을 모두 결합해 사용

3.2.4 추천을 위한 텍스트 설명
콘텐츠 입력을 사용해 추천 정확도를 올리는 것이 아닌, 추천의 설명을 제공하는 목표로 텍스트를 사용하는 방법론입니다.
텍스트 활용 설명가능 추천은 크게 두 접근으로 나뉩니다.
1) 추출 기반 모델
추천 설명을 위해 중요한 텍스트 조각을 선택하는 데 집중합니다. 어텐션 메커니즘이 활용됩니다.
2) 생성 기반 모델
유저의 평점 기록과 리뷰 데이터가 있을 때, 이들을 활용해 인코더-디코더 스트럭쳐를 학습하는 방법론입니다.
4. Temporal / Sequential Models
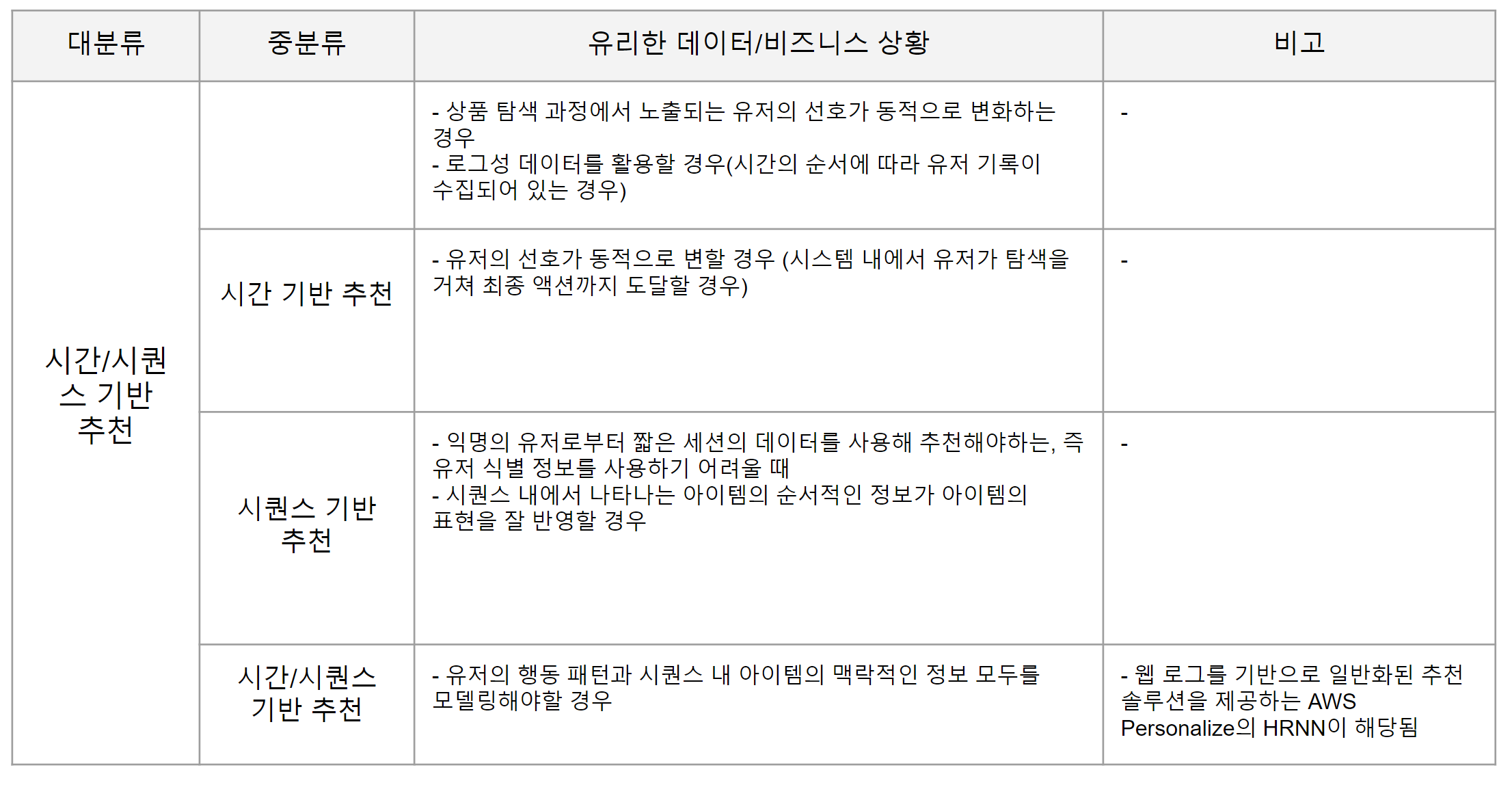
시간 및 시퀀셜 데이터를 활용한 모델 역시 직관적인 아이디어에서 시작합니다.
“고객이 시스템 내에서 일정한 여정을 가지는데, 이를 예측해 다음 행동을 먼저 추천함으로써 고객에게 몰랐던 상품을 알려주고 고객의 시간을 절약해줄 수 있지 않을까?”
유저의 선호는 정적이지 않고, 시간에 걸쳐 바뀌어 나갑니다. 달리 말해, 진화해(evolve) 나갑니다. 이러한 상황을 더 잘 다루기 위해, temporal/sequential 모델은 유저의 동적인 선호와 시간에 걸친 시퀀셜한 패턴에 주목합니다.
즉, 시간이라는 새로운 축을 두고 이러한 축을 기준으로 어떻게 고객의 선호가 변화해 나갔는지, 다른 고객은 비슷한 맥락에서 어떤 상품을 탐색했는지를 모델링합니다. 쉽게 말해 크리스마스 트리를 구매한 고객은 그 다음에 슬리퍼를 구매하기 보다는 크리스마스 트리 장식을 살펴본다는 식의 관찰에 기반합니다.
이러한 방법론은 3개의 범주로 나눌 수 있습니다.
1) 시간 기반 추천
2) 세션 기반 추천
3) 시간/세션 기반 추천

4.1 시간 기반 추천 (Temporal based recommendation)
시간에 걸친 유저 선호의 시간적 변화를 잡아내는 데 주목한 방법론입니다. 시계열 패턴을 모델링하는 문제에서 RNN이 탁월한 성능을 보여, 많은 방법론이 RNN을 사용하고 있는데요.
대표적인 모델 하나를 소개하고 넘어가겠습니다.
1) RRN(Recurrent Recommender Networks) [498]: 2개의 RNN 모델을 사용하여, 유저와 아이템 잠재 벡터의 변이(evolution)가 시간에 걸쳐 학습됨.
최근에는, Neural Turing Machines(NTM)과 메모리 네트워크(Memory Network)로 시간적인 변이를 모델링하는 트렌드가 있습니다.
4.2 세션 기반 추천 (Session based recommendation)
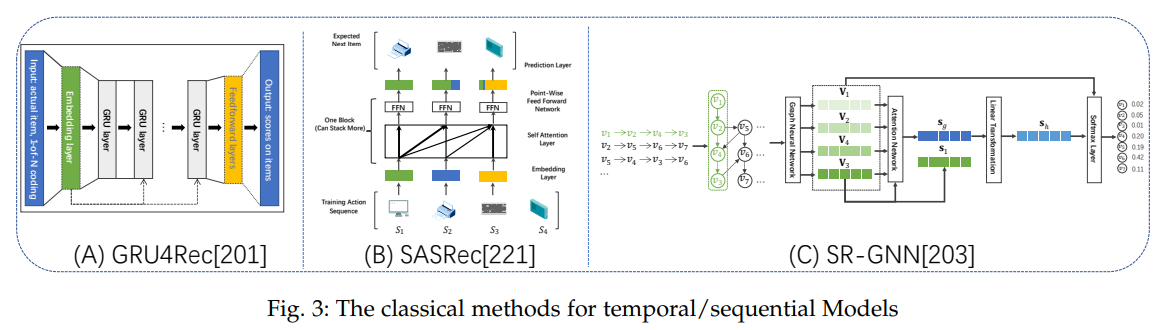
익명의 유저로부터 짧은 세션의 데이터를 사용해 추천해야하는, 즉 유저 식별 정보를 사용하기 어려울 때 시퀀셜한 아이템 변천 패턴을 모델링하는 방법론입니다. 많은 웹/앱 서비스에서 마주할 수 있는 상황으로 활용 가치가 높아 보입니다.
알고리즘을 간단히 정리한 내용은 다음과 같습니다.
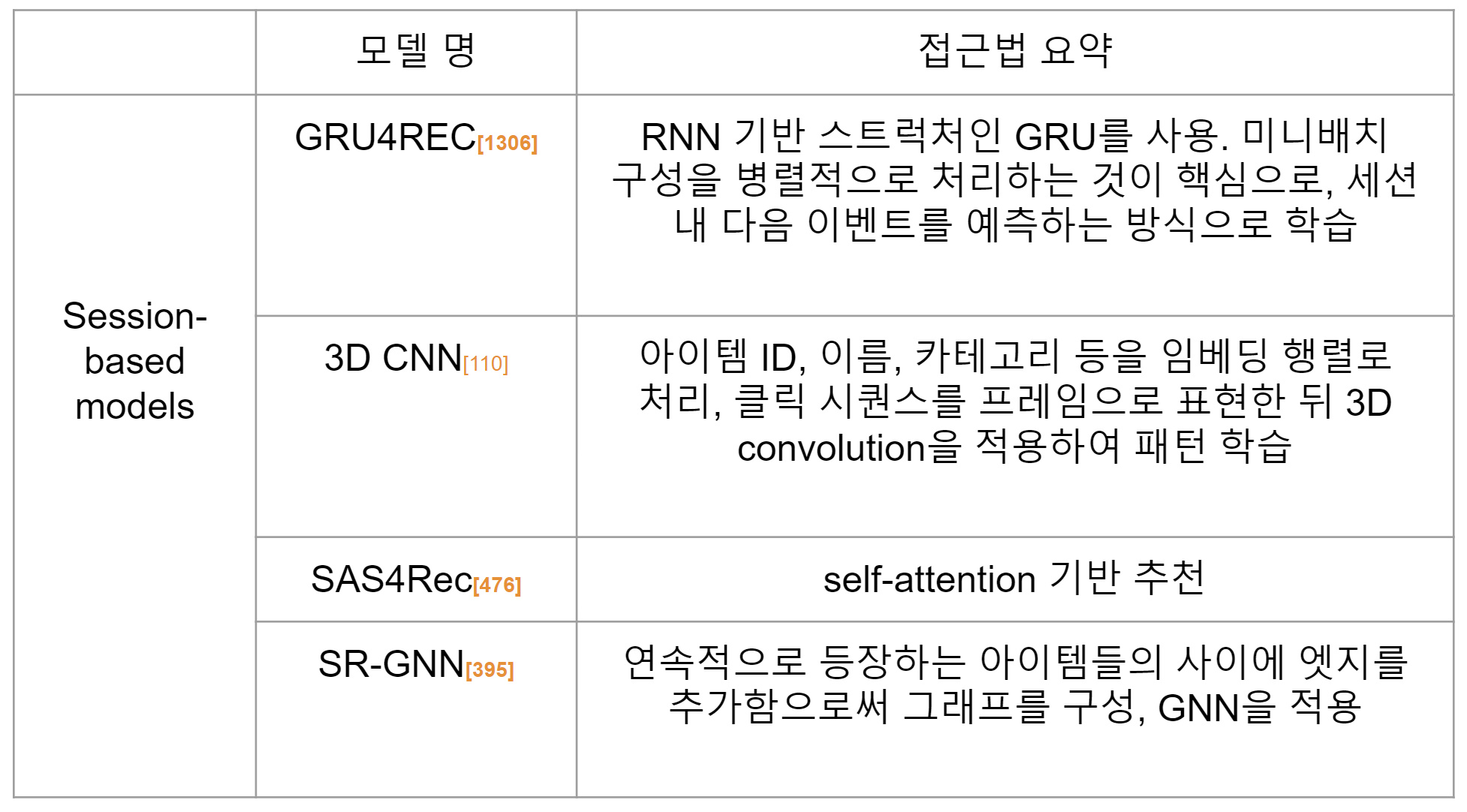
4.3 시간/세션 기반 추천 (Temporal and session based recommendation)
이 방법론은 4.1과 4.2의 접근을 결합한 방법론으로, 유저 선호의 시간적 변이와 아이템의 시퀀셜한 패턴을 동시에 고려합니다.
두 가지 솔루션으로 분류할 수 있습니다.
- 1) 유저의 장기 선호와 단기 동적 선호를 학습
- H-RNN (Hierarchical Recurrent Neural Network)[356], HAN(Hierarchical Attention Network)[183]
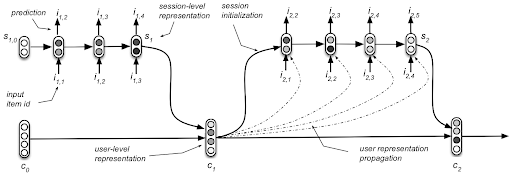
- 특히 H-RNN은 Amazon Personalize에서 사용되는 궁극의(?) 알고리즘으로 알려져 있는데요. 유저가 여러 세션에 걸쳐 시스템에 들어올 경우 장기적인 유저의 선호와 해당 세션에서의 단기적인 유저 의도를 동시에 모델링하는 GRUusr(GRU-user), GRUses(GRU-session) 두개의 네트워크를 학습합니다. 더 자세한 내용은 추후에 포스트로 다루도록 하겠습니다.
- 2) 뉴럴넷 모델을 사용해 유저의 통합된 표현을 학습
- Caser(Convolutional Sequence Embedding Recommendation)[523]
- GNN 활용 트렌드 소개: 여기에 덧붙여, 저자는 순차적인 정보와 구조적인 정보를 동시에 잡아내는 그래프 구조를 활용함으로써, 시간/세션 기반 추천을 강화하는 방법론들에 대해 소개하고 있습니다.
5. 정리하며
딥러닝을 추천에 적용한 방법론은 끊임없이 쏟아져 나오고 있고, 지금도 다채롭고 번뜩이는 아이디어로 기존의 문제를 해결하려는 움직임이 활발합니다. 이러한 알고리즘을 공부하고 그 흐름을 따라가는 일은 벅차기도 하지만 새로운 즐거움을 준다는 점에서 매력적인 공부인 것 같습니다.
한편으로는, 한참 알고리즘을 살펴보다가 다소 맥빠지는 소리일지는 모르겠지만 앞선 포스트의 서론에 말했듯이, 알고리즘이 아닌 다른 큰 부분을 살펴보는 안목이 중요한 것 같습니다.
추천이라는 기술은 그 목적 자체가 고객의 마음을 읽고 그들이 원하는 것을 더 빠르게, 더 즐겁게 전달하는 것이 목적이라 생각합니다. 따라서 단순한 기술적인 접근만으로 해결할 수 없는 부분이 많은데, 추천이라는 서비스를 지탱하는 다양한 기둥 중에 알고리즘이라는 한 기둥이 주는 즐거움에 젖어 더욱 중요한 것을 잃지 말아야겠다는, 스스로에게 주는 경고를 일기처럼 남기며 논문 리뷰를 마칩니다. 읽어 주셔서 감사합니다!
Appendix: 주요 알고리즘 구현체 레포지터리 주소 모음
SVD++
- https://github.com/cheungdaven/recommendation
- https://github.com/AmazingDD/daisyRec
Mult-VAE
- https://github.com/dawenl/vae_cf?utm_source=catalyzex.com
GCMC
- https://github.com/tanimutomo/gcmc
- https://github.com/hengruizhang98/GCMC-Pytorch-dgl
NGCF
- https://github.com/huangtinglin/NGCF-PyTorch
- https://github.com/talkingwallace/NGCF-pytorch
- https://github.com/xhcgit/NGCF-implicit
- https://github.com/xiangwang1223/neural_graph_collaborative_filtering
LightGCN
- https://github.com/gusye1234/LightGCN-PyTorch
- https://github.com/kuandeng/LightGCN
Collaborative metric learning
- https://github.com/changun/CollMetric (tf)
- https://github.com/MogicianXD/CML_torch (torch)
TransCF
- https://github.com/pcy1302/TransCF
Neural Collaborative filtering
- https://github.com/search?q=neural+collaborative+filtering
DNN for youtube
- https://github.com/ogerhsou/Youtube-Recommendation-Tensorflow (tf)
- https://github.com/onozeam/YoutubeDNN (torch)
Deep FM
- https://github.com/ChenglongChen/tensorflow-DeepFM
- https://github.com/Johnson0722/CTR_Prediction
- https://github.com/chenxijun1029/DeepFM_with_PyTorch
xDeepFM
- https://github.com/batch-norm/xDeepFM
- https://github.com/Leavingseason/xDeepFM
RRN
- https://github.com/RuidongZ/Recurrent_Recommender_Networks (tf)
Session-based recommendations with recurrent neural networks
- https://github.com/bekleyis95/RNN-RecSys?utm_source=catalyzex.com
SASRec
- https://github.com/kang205/SASRec
- https://github.com/pmixer/SASRec.pytorch
SR-GNN(Session-based recommendation with graph neural networks)
- https://github.com/CRIPAC-DIG/SR-GNN
- https://github.com/userbehavioranalysis/SR-GNN_PyTorch-Geometric
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요. 내용에 대한 지적, 혹은 질문을 환영합니다.
출처
https://arxiv.org/pdf/2104.13030.pdf
Leave a comment