
[RecSys] 우버 이츠가 GNN으로 메뉴 추천 하는 방법
배달 플랫폼 Uber Eats가 GNN을 활용해 추천 서비스를 개선한 이야기를 살펴봅니다.
Uber AI가 공개한 “How Uber uses Graph Neural Networks to recommend you food (live stream)”을 듣고 정리한 내용입니다.
1. 우버 이츠가 도시별로 유저, 레스토랑, 메뉴를 노드로 갖는 그래프를 과거 주문 이력을 바탕으로 구축함. 이 그래프에 GraphSAGE를 활용하여 메뉴와 유저의 노드 임베딩을 구하고, 이 임베딩간의 유사도를 피처로 사용하여 최종 추천에 활용함
2. 그 결과 유의미한 on/offline 성능 향상을 확인함
3. 이러한 그래프 피처를 학습하고 서빙하기 위한 데이터 파이프라인을 소개
본 포스트는 Uber AI의 Ankit Jain이 발표한 영상을 토대로 작성한 노트입니다.
영상은 여기에서 보실 수 있습니다.
또한, 블로그 포스트도 참고했습니다.
Contents
1. 들어가며
우버 이츠는 미국을 비롯한 전 세계에서 널리 사용되는 배달 플랫폼 서비스입니다. 2020년 기준 6,600만명의 유저가 사용하며, 약 6,000개의 도시에서 서비스되며 60만개의 레스토랑이 등록되어 있습니다. 전 세계 배달 시장의 30%를 차지하고 있다고 하니 (출처) 실로 거대한 서비스인데요.
이러한 우버이츠에서 효율적이고 강력한 피처를 생성하기 위해 GNN을 사용한 이야기를 생생하게 전해주고 있는 자료가 있어 공부하고 정리해 보았습니다. 대부분의 내용은 영상을 들으며 요약한 내용이고, 부족한 부분을 블로그 포스트에서 보충했습니다.
그래프 뉴럴넷(이하 GNN)이 추천 분야에서 주목받은지 꽤 오랜 시간이 지났으나, PinSAGE처럼 실제 프로덕션 레벨에서 GNN을 활용한 사례를 공개적으로 보여주는 자료를 찾아보기 힘든 와중에 발견해 개인적으로 매우 흥미롭게 들었습니다.
본 발표의 제목은 “Enhancing Recommendations on Uber Eats with Graph Convolutional Networks”입니다. 발표자는 Uber AI의 Ankit Jain이고, Piero Molino와 함께 협업했다고 합니다.
발표자가 제시하는 3가지의 아젠다는 다음과 같습니다.
1) graph representation learning
2) dish recommendation on Uber Eats
3) Graph learning on Uber Eats
2. Graph Learning 소개
GNN 기반 모델을 설명하기에 앞서, Graph Representation Learning에 대한 간단한 개요를 살펴보고 넘어갑니다.
[Graph Neural Network]
그래프 형식의 데이터는 어디에나 존재합니다. 가령 소셜 네트워크, linked open data, biomedical graph, Information network, Internet as a graph, 뇌 신경망 등이 그 예시입니다.
[Tasks on graphs]
이러한 그래프 데이터에서는 다양한 머신러닝 태스크를 수행할 수 있습니다. 가령 아래의 4가지 태스크를 예로 들 수 있는데요. 예를 들어, 페이스북 친구 관계 네트워크가 있을 때 이를 사람이 노드(node)이고, 친구 관계가 엣지(edge)인 그래프로 볼 수 있겠죠. 이 예시를 가지고 아래의 태스크를 설명하도록 하겠습니다.
1) node classification: 주어진 노드의 타입을 예측하는 태스크입니다. 네트워크 내의 사람이 남성인지, 여성인지 구별하는 태스크를 생각할 수 있습니다.
2) link prediction: 두 노드가 연결되었을지 그렇지 않을지 예측합니다. 네트워크 내 두 사람이 친구인지 아닌지를 예측하는 태스크라고 할 수 있습니다. 추천의 문제가 이 태스크와 관련이 있을 것입니다.
3) community detection: 노드들 간에 밀집된 형태로 연결된 클러스터를 찾아냅니다. 가령 여러 사람들이 비슷한 패턴을 공유한다면, 그 사람들이 동호회나 학회와 같은 커뮤니티에 소속되어 있다는 것을 발견할 수 있을 것입니다.
4) network similarity: 두 (서브)네트워크가 얼마나 유사한지를 밝힙니다. 페이스북 내 PyTorch KR 커뮤니티와 Recsys KR 커뮤니티가 얼마나 같은지, 다른지를 수치화해보는 작업을 생각해 볼 수 있겠죠.
[Learning framework]
이제 이 그래프 데이터에서, 위와 같은 다양한 태스크를 수행함에 있어 어떻게 학습을 수행하는지를 살펴보겠습니다.
모든 기계학습 문제는 학습 프레임워크에 데이터를 맵핑하는 과정으로 이루어집니다. 그래프 데이터에서는, 노드를 특정 임베딩 공간으로 맵핑하는 인코더 함수를 정의합니다. 여기에 네트워크 스트럭쳐에 기반한 노드 유사도 함수를 정의해서, 그래프 내에서 유사한 노드 두 개가 있을 때 이들이 각각 임베딩 공간으로 맵핑된 결과물이 유사도 함수로 측정된 결과가 높게 나오도록 유도하는 방식으로 학습이 이루어 집니다.
수식으로 표현하면 다음과 같습니다. 노드 $u, v$가 있을 때, $z_{u}, z_{v}$는 각각 노드 $u, v$의 임베딩 벡터입니다. 두 노드를 유사도 함수 $similarity()$에 넣으면 임베딩 벡터 $z_{u}, z_{v}$간의 내적과 근사한 값이 나오도록 인코더 모델의 파라미터를 최적화 하는 방식으로 학습이 이루어 진다는 말입니다.
$similarity(u,v) \approx z_{v}^{\top}z_{u}$
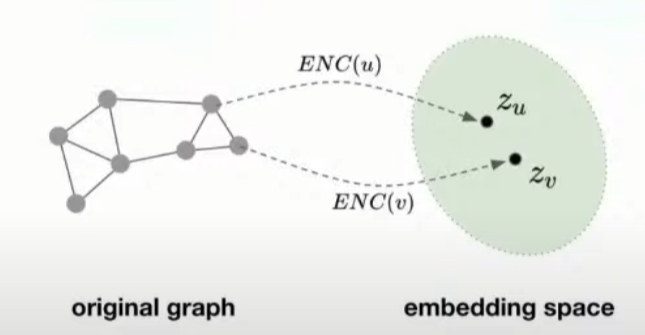
따라서 노드를 임베딩 공간 내의 벡터 representation으로 맵핑해 인코딩하는 함수를 학습하고자 하는 것이 목적이라 할 수 있습니다. 결과적으로는 그래프 공간 상에서 유사한 노드들이 우리가 결과물로 얻어낸 임베딩 공간 상에서도 유사한 measure를 갖도록 만들어주는, 그러한 인코더 함수를 얻고 싶은 것입니다.
요약하자면, 다음 프레임워크를 따릅니다.
1) 유사함의 기준을 정의
2) 유사도 함수 정의
3) 인코딩 함수 정의 후 최적화
[Shallow encoding]
이제 인코딩 하는 방법에 대해서 살펴보겠습니다. 가장 간단한 형태의 인코딩 접근법으로, embedding lookup 테이블을 활용하는 방식이 있습니다. 말하자면 특정 대상이 있을 때 이미 정해진 임베딩 테이블에서 대상의 index를 사용해 한 벡터를 조회하는 방식인데요.
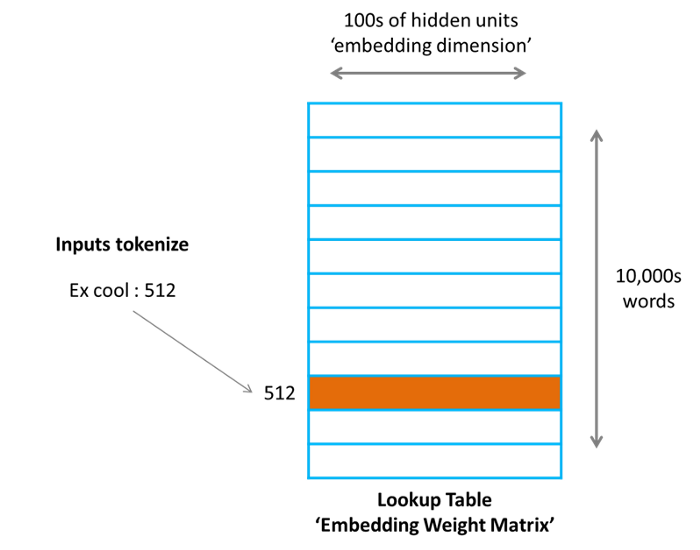
이러한 방법을 사용하는 예로 Matrix Factorization, Node2vec, Deepwalk 등이 있습니다. 단순한 자연어처리에서의 임베딩 레이어와 같다고 생각할 수 있습니다. “사과”라는 단어는 [0.5, 0.2, 0.62]이고, “배” 라는 단어는 [0.45, 0.24, 0.7] 와 같은 식으로 조회되는 임베딩 벡터를 떠올릴 수 있겠죠.
이러한 방식에서는 별도의 임베딩 메트릭스가 존재하고, 그 매트릭스를 구성하는 한 행(row)은 하나의 노드에 대응됩니다. 자연히 벡터의 사이즈는 사전에 정의한 embedding size가 되겠죠. 그런데 한 가지 문제가 있습니다. 너무 많은 노드가 들어가면 이 테이블은 몹시 거대해 질 것입니다. 메모리를 먹는 귀신이 되겠죠.
[Shallow encoding의 한계]
1) 너무 많은 파라미터의 수
만약 V개의 꼭지점을 가질 경우, 전체 네트워크 내의 모든 노드의 임베딩을 만들어내려면 $O( \mid V \mid \times dim)$의 수를 갖는 파라미터를 계산해야 할 것입니다. 여기서 $V$는 꼭지점 수, $dim$은 임베딩 차원이 됩니다. 매우 많은 파라미터를 학습해야 한다는 것이 첫번째 문제입니다.
2) 새로운 노드(unseen node)에 대한 임베딩을 만들 수 없음
Matrix Factorization 접근법을 취하는 대부분 알고리즘의 문제는 학습 과정에서 등장하지 않는 노드의 임베딩을 만들어낼 수 없다는 것입니다.(불가능하거나, 매우 오랜 시간이 필요하겠죠).
새로운 샘플의 임베딩을 얻기 위해서는 전체를 재학습하거나(이는 매우 unfeasible하죠) 몇 SGD 에폭 간의 Ad hoc(즉석의) 트레이닝을 통해 adaptation을 수행할 수 있습니다. 그러나 이는 실제 프로덕션 환경에서 불가능할수도 있고, 매우 시간소모가 큰 해결 방법입니다. 항상 새로운 노드가 등장하기 마련인 dynamic realworld에서는 굉장히 불리한 접근임을 알 수 있습니다.
가령 유튜브에서는 실시간으로 수많은 비디오가 업로드 될텐데, 이 경우 Matrix Factorization 모델을 새로 계산하는 것은 불가능한 일일 것입니다.
이 두 가지를 요약하자면 비효율성때문에 shallow encoding이 불리하다는 말입니다.
3) 노드 피처 활용 불가
추가로 추천에 유용한 정보를 제공할 수 있는, 그리고 그래프 임베딩을 학습함에 있어 중요한 시그널을 주는 노드의 피처를 사용할 수 없다는 점에서 큰 단점을 가집니다.
이러한 한계를 보았을 때, 새로운 방법론이 필요함을 느낄 수 있습니다.
[Graph Neural Network]
많은 GNN의 variants 중에, spectral/spatial이라는 두 가지 큰 부류가 있습니다. 이 중 spatial한 녀석을 들여다 볼 건데 그 이유는 이게 spectral(정확히는 GCN)한 녀석보다 더 확장하기(scale) 쉽기 때문입니다. Spectral Convolution을 사용하는 방법론은 대표적으로 GCN이 있고, Spatial Convolution을 사용하는 방법론은 GraphSAGE를 들 수 있습니다.source Uber Eats는 GraphSAGE를 활용했으므로, Spatial한 variant를 살펴보려 합니다.
핵심 아이디어는 다음과 같습니다. 노드 representation을 얻기 위해, 이웃으로부터 제한된 BFS(breadth-first search)를 통해 재귀적으로 정보를 통합할 때 뉴럴 네트워크를 사용합니다.
가령 A라는 노드의 representation을 얻기 위해, A 주변에 있는 노드들을 참고하고, 그 과정에서 자기 스스로의 정보도 참고하게 되는 구조를 띠게 됩니다.
이웃과 자신의 정보를 반복적으로 결합해 표현을 학습해 나가는 과정은 아래에 자세히 설명하겠습니다.
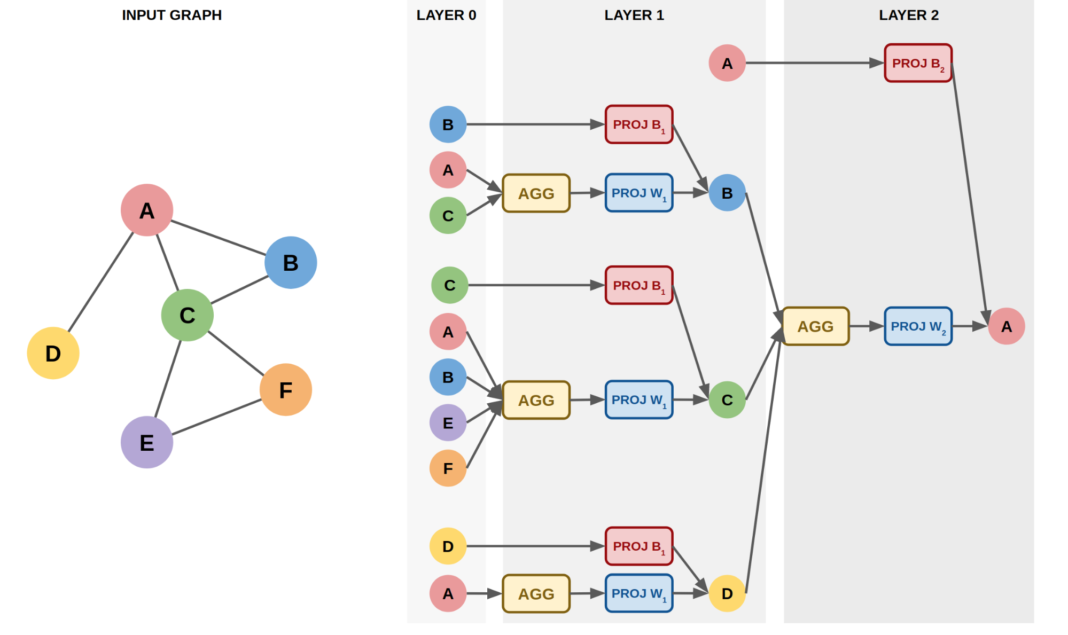
입력 그래프가 왼쪽의 6개 노드를 가진 그래프라고 합시다. 이 때 A라는 노드의 임베딩을 2개의 레이어를 거쳐서 얻으려고 할때, 전파가 어떻게 이루어 질까요? A와 연결된 노드는 B,C,D 이고, 자신의 정보 역시 잃어서는 안되기 때문에 A를 추가해 줍니다.
따라서 Layer 1에서 Layer 2로 이어지는 오른쪽 부분에 A, B, C, D라는 4개의 노드가 놓이게 됩니다. 2개의 레이어를 갖는 구조이기 때문에, 이 A, B, C, D 노드가 각각 연결된 노드에서도 정보를 넘겨 받게 됩니다. 만약 레이어의 개수가 $n$개로 더 많았다면, 이러한 방식을 재귀적으로 $n$회만큼 반복했겠죠.
이렇게 물려있는 형태를 펼쳐 놓은 것이 오른쪽의 그림이라고 정리할 수 있겠습니다. Layer 0부터 값을 어떻게 전달하는지 살펴보면, B,A,C라는 노드가 Layer 1에 있는 B라는 노드에 값을 전파하고 있는 형태라는 것을 파악할 수 있습니다. 자기 스스로인 B의 값을 전달하는 한편, A와 C라는 주변 노드의 값을 AGG라는 과정을 통해 전파하게 되는데요.
여기에서 AGG라는 함수의 파라미터를 조정해 나가는 과정에서 학습이 이루어집니다. 즉, 각각의 노드에 대해서 임베딩을 학습하는 Shallow Embedding 방식이 아닌, 저 AGG를 구성하는 파라미터를 최적화 함으로써 어떤 방식으로 값을 이웃에 전파하면 되는지 룰을 학습해 어떤 노드가 들어온다 하더라도 임베딩 값을 생성해낼 수 있는 것입니다.
이러한 학습 방식 덕분에, Inductive한 예측을 수행할 수 있습니다. 반면 GCN의 경우에는 Transductive한 특성 때문에 쉽게 unseen node에 대응하기 어렵다는 단점이 있습니다.
[Neighborhood Aggregation]
전체 모델 네트워크는 여러 개의 레이어를 가지게 되는데, 각 레이어는 BFS 상 깊이(depth)의 한 레벨을 의미합니다. 이 때 노드들은 각 레이어마다 임베딩을 가지게 됩니다. 즉, 레이어 1의 노드 b의 임베딩과 레이어 2의 노드 b의 임베딩은 다른 것이지요.
그러나 레이어 1에서 노드 a로 유입되는 노드 b의 임베딩 웨이트는 레이어 1에서 노드 c로 유입되는 노드 b의 임베딩 웨이트와 같습니다. 이러한 구조로 인해 scalability를 얻을 수 있게 됩니다. 학습이, 그래프 내에 얼마나 많은 노드가 존재하는지에 구애받지 않게 되는 것이죠. 노드 수 보다는 뉴럴넷 내의 뉴런의 수가 얼마나 되는지에 영향을 받습니다. 모든 뉴럴넷 파라미터가 전체 노드에서 공유되기 때문입니다.
노드 $v$가 레이어 0에서 갖는 임베딩값은 그 자체의 입력 피처 $x$를 의미합니다. 입력값 자체를 학습가능한 임베딩을 썼을까요? 라는 질문이 나왔는데, 대답은 No였습니다. 학습은 기본적으로 레이어 층에서 이루어지게 됩니다. (어떻게 피처를 전달할까에 대한 규칙, 즉 aggregation rule만 업데이트 됩니다.) 발표자는 그 접근(learnable parameter를 쓰는 접근)이 옳다 생각하지 않는다고 말했습니다.
[Inductive capability]
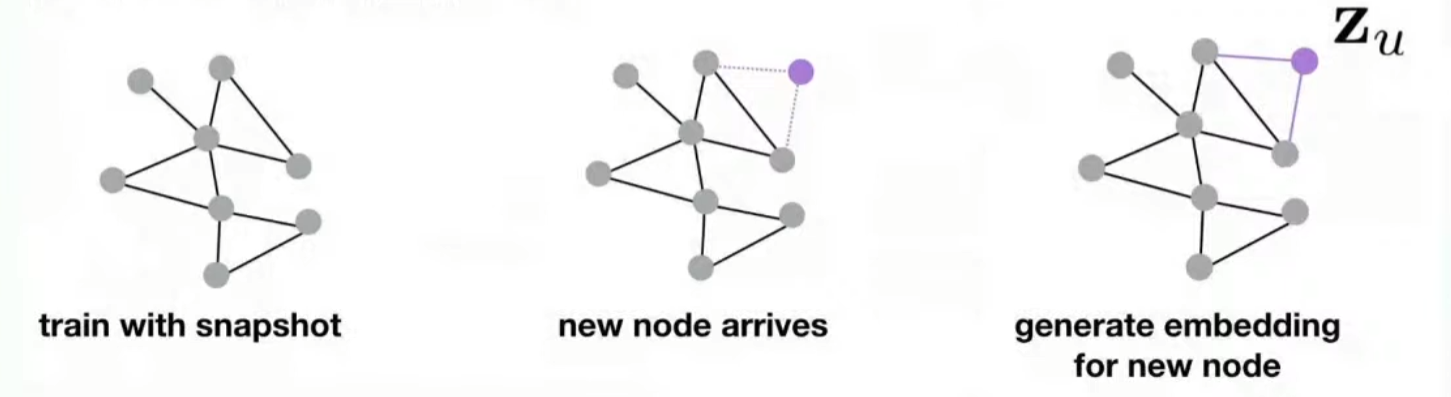
실제 어플리케이션에서는, 새로운 노드가 종종 그래프에 추가되는 경우가 있습니다. 우버 이츠의 경우에는 새로운 메뉴나, 레스토랑이 추가되는 경우를 생각해 볼 수 있겠죠. 이 새로 추가된 노드에 대해서 재학습 없이 임베딩을 부여할 수 있다면 자원이나 운영 측면에서 유리할 것입니다. 이러한 특성을 Inductive Capability라고 부릅니다.
그러나 앞서 살펴본 shallow method로는 이렇게 간편하게 새로운 노드에 대한 임베딩을 얻어낼 수 없을 것입니다. 이를 해결하는 방법은, 노드의 임베딩을 snapshot으로 학습하여 새로운 노드가 도착할 경우 이 노드에 대한 새로운 임베딩을 생성하는 것입니다. shallow 방법에서와 같이 노드별로 개별적인 임베딩을 학습하는 것이 아니라, 네트워크의 parameter를 학습하는 것인데요.
즉, 임베딩 그 자체를 학습하는 것이 아니라, 임베딩을 만들어내는 함수의 파라미터를 학습함으로써 unseen node에 대한 임베딩을 필요에 따라 만들어 낼 수 있도록 디자인하는 것입니다. 단순한 Fully Connected layer를 생각해보면, 뉴럴넷의 웨이트를 학습만 해 놓으면 어떤 테스트 데이터를 넣는다 할지라도 그에 상응하는 예측값을 출력해 줄 수 있겠죠. 이처럼 새로운 노드가 등장했을 때 이에 상응하는 임베딩 값을 만들어 낼 수 있는 네트워크를 학습해보자는 전략입니다.
3. Uber Eats에서의 Graph Learning 추천
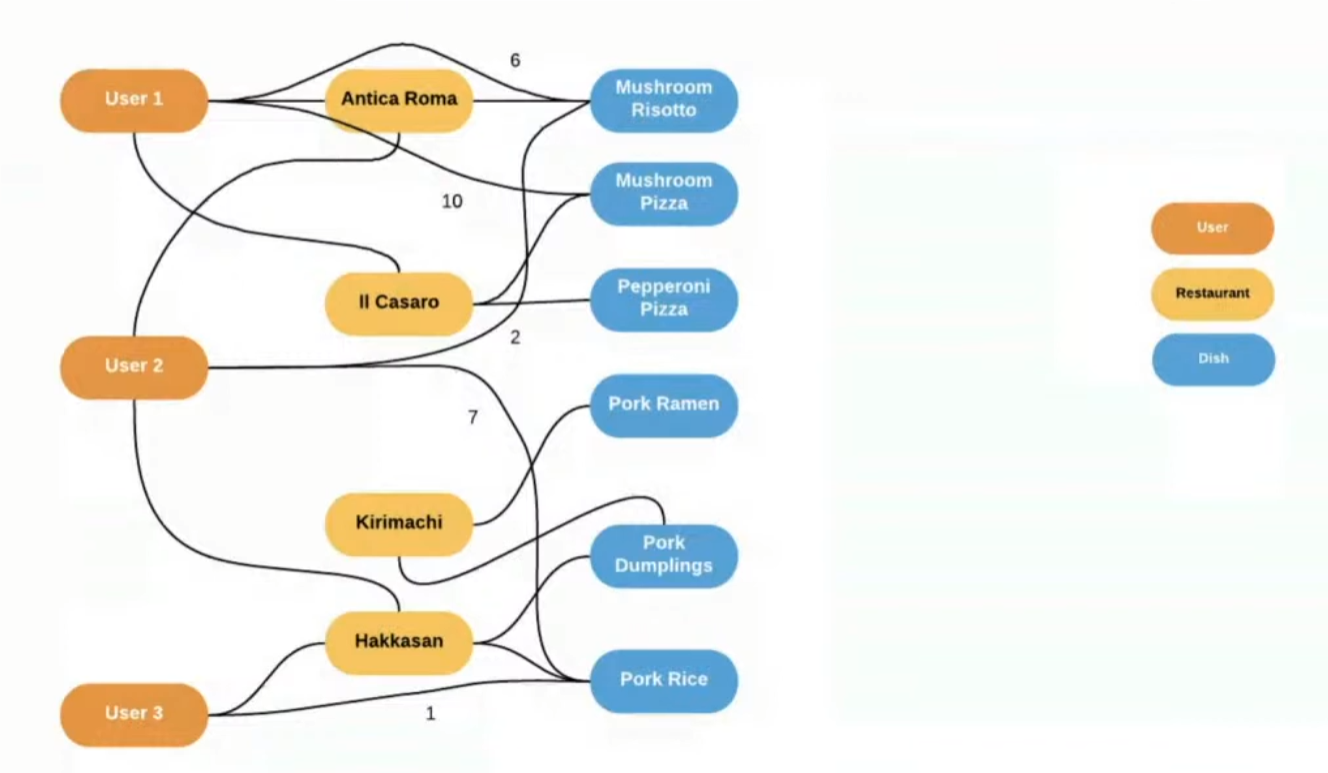
추천을 위한 Uber Eats의 그래프 유저, 레스토랑, 음식 메뉴라는 세 종류의 노드가 존재하고, 과거 내역에 따라 이 노드간에 연결이 이루어집니다.
[Bipartite graph for dish recommendation]
먼저 유저와 메뉴의 interaction으로부터 bipartite 그래프를 생성합니다. 유저와 레스토랑, 음식 메뉴라는 세 가지 노드가 있을 때, 유저가 최근 M일간에 특정 음식을 주문 했다면 그 음식과 연결하게 됩니다. 이 두 노드를 연결하는 엣지에는 음식 주문의 빈도가 weight로 사용됩니다. 우버 이츠의 추천에 활용되는 그래프에는 다음의 2가지 특성을 가지고 있습니다.
Uber Eats 그래프의 property
1) Graph is dynamic: 새로운 유저와 음식이 매일 추가됨
2) 각 노드는 음식 이름의 word2vec 값과 같은 피처 값을 가짐
발표자인 Ankit Jain은 전체 모델에 대해서 설명하지는 않으나, 모델의 성능에 중요한 영향을 미쳤던 부분에 대해서 깊이있게 다루었습니다. 바로 손실 함수 부분인데요.
[Max margin loss]
Max margin loss가 이루고자 하는 주된 아이디어는 “유사도 점수보다는 상대적인 ‘ranking’에 신경을 쓰겠다”는 것인데요, 이는 완전히 새로운 접근법은 아닙니다. 아래와 같은 수식을 통해 이를 실현하고 있습니다.
$L = \Sigma_{(u,v)\in E} max(0, -z_u^{\top} z_v + z_u^{\top} z_n + \Delta)$
여기서 $u,v,n$은 노드집합 E의 원소이고, $v$는 유저 $u$에게 positive한 노드, $n$은 별도로 샘플링한 negative 노드를 의미합니다. 여기에 $\Delta$라는 margin을 붙임으로써, positive pair인 $z_u,z_v$와 negative pair인 $z_u,z_n$ 사이의 유사도 점수의 차이가 최소 $\Delta$ 만큼의 차이는 만들도록 유도하게 됩니다.
이러한 방식으로 샘플들 간의 절대적인 유사도보다는, negative 샘플과 positive sample 간의 상대적인 유사도를 기준으로 학습을 수행하게 됩니다. 이는 SVM에서 사용하는 것과 비슷한 방식의 loss function으로 생각할 수 있습니다.
이 loss function을 통해 유의미한 개선을 얻어내었지만, 여기에 부가적인 조치를 취하여 프로덕션에 적용했다고 합니다.
그 부가적인 조치에 대해서 아래에 이어가겠습니다.
[New loss with Low rank positives]
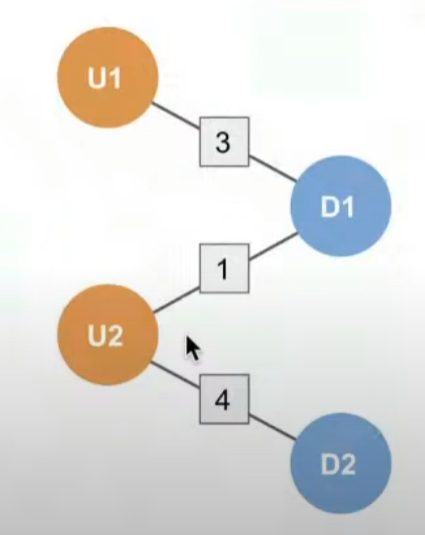
low rank positives는, 주문한 이력이 없는 negative sample과는 달리 주문한 이력은 있지만 positive sample만큼은 아닌 샘플들을 의미합니다. 즉 짜장면을 5번 주문했고, 피자는 1번 주문했을 경우 짜장면을 positive로 생각할 때 1번밖에 주문하지 않은 피자는 low rank positive가 됩니다.
negative sample과 positive sample을 비교하는 것 뿐만아니라, 상대적으로 덜 주문한 상품(low rank positive)과 자주 주문한 상품(positive sample)를 비교하도록 학습을 설계함으로써, 달리 말해 조금 더 구분이 어려운 문제를 모델에게 제공함으로써 성능 향상을 유도한다는 아이디어로 볼 수 있을 것입니다.
수식은 다음과 같습니다.
$L = \Sigma_{(u,v)\in E} \alpha_n max(0, -z_u^{\top} z_v + z_u^{\top} z_n + \Delta_n) + \alpha_l max(0, -z_u^{\top} z_v + z_u^{\top} z_l + \Delta_l)$
이 low rank positive들과 positive를 비교하는 max margin loss 텀을 하나 더 추가함으로써 성능 향상을 얻어냈습니다.
1번 텀(negative vs possitive)에서의 margin인 $\Delta_n$에 비해서 2번 텀(positive vs low rank positive)의 margin인 $\Delta_l$이 더 작습니다. ($\Delta_l \lt \Delta_n$)
여기에서 이러한 질문이 나왔습니다.
Q: 저 weight를 그냥 단순히 순서로만 놓는게 아니라 다르게 안해봤나? 가령, 주문 빈도 5와 1이 차이가 나는 정도를 반영해서 넣을 수도 있을 것 같은데.
A: 가중치 놓고 제곱하는 등 다양한 방법을 해봤는데 잘 안나왔다. 이게 최고였다.
loss function 외에 좋은 개선을 가져온 다른 접근 방법으로는, aggregation rule에 대한 새로운 전략이 있었습니다.
[Weighted pool aggregation]
Weighted pool aggregation은 엣지의 가중치에 기반해 이웃의 임베딩을 aggregation하는 방식입니다. 즉, 특정 노드의 임베딩을 앞서 말한대로 shallow 방식이 아닌 웨이트 파라미터의 계산 결과로써 획득한 뒤, 주변의 임베딩 결과값을 결합하는 식으로 이루어집니다.
아래의 그림에서, $h_D$라는 노드의 임베딩을 구할 때, 이미 구해진 $h_A$, $h_B$, $h_C$ 노드의 임베딩으로부터 5,2,1이라는 weight가 각각 있을 때 message passing의 과정에서 $A$노드의 임베딩에 5만큼의 가중치를 붙여주는 방식입니다. 이로써 네트워크상에서 노드 사이에 존재하는 영향도의 강도를 반영하여 임베딩을 학습할 수 있습니다.
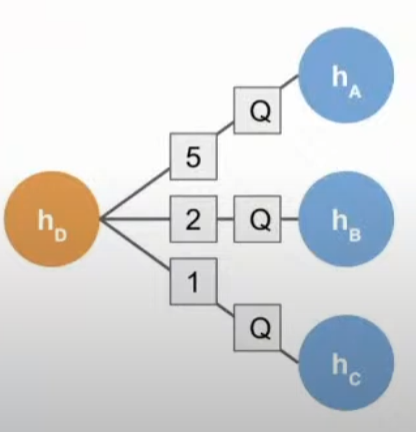
Aggregation Function은 다음과 같이 정의됩니다.
$AGG = \Sigma_{u \in N(v)} w(u,v) Q h^{k-1}_u$
여기서 $Q$는 Fully connected layer를 의미합니다.
[Offline evaluation]
위에서 설명한 방법을 통해 Downstream personalized ranking을 그래프 노드 임베딩을 사용해 학습했고, 그 결과 다음과 같은 성능을 얻었다고 합니다.
| Model | Test AUC |
|---|---|
| 이전의 프로덕션 모델 | 0.784 |
| graph embedding을 추가한 모델 | 0.877 |
결론적으로 graph embedding을 활용한 결과 기존 production model 대비 12%의 AUC 성능 향상을 얻어낼 수 있었습니다.
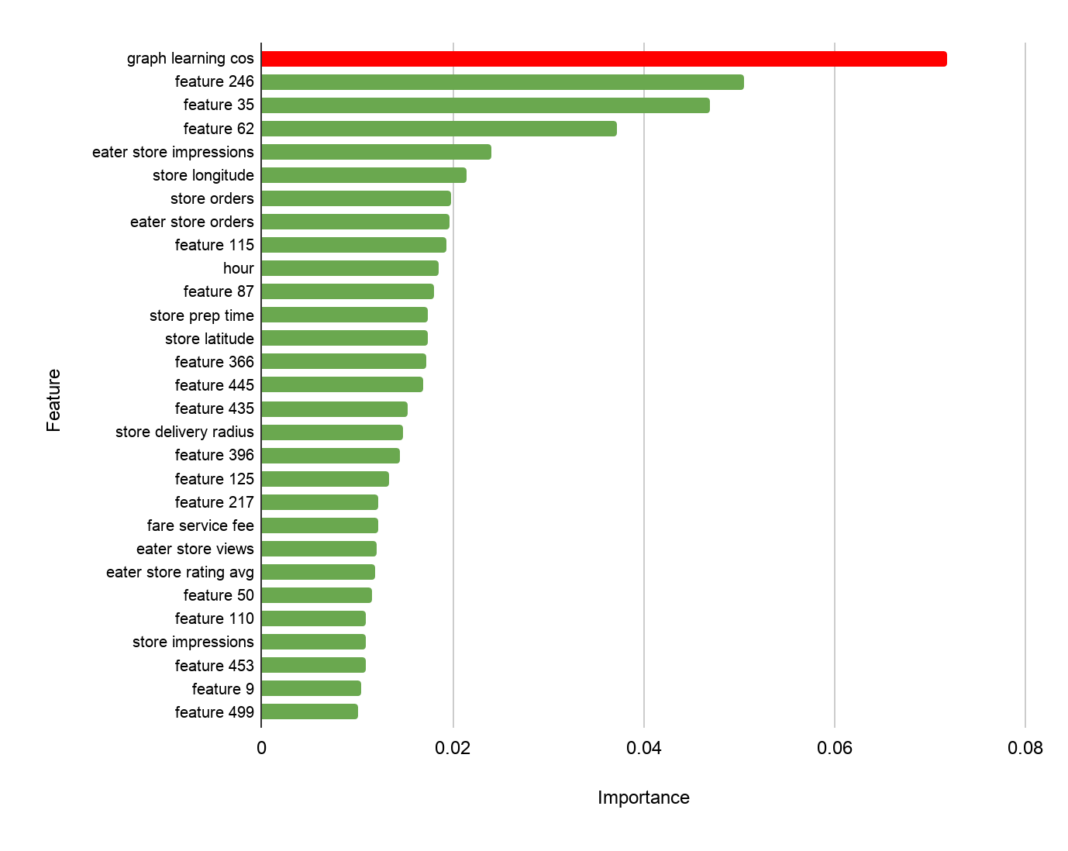
임베딩을 피처로 활용해 XGboost와 같은 모델을 붙여 downstream task를 수행하는데, 그 모델의 feature importance 값이 가장 높은 피처가 바로 이 Graph learning cosine similarity였다고 합니다. 이는 유저-아이템 쌍이 있을 때 이 둘의 그래프 임베딩 값 사이의 내적을 구한 유사도 값으로 생각됩니다.
[Online evaluation]
이어서 샌프란시스코 내에서 직접 A/B 테스트를 수행했습니다. CTR 측면에서 유의미한 uplift가 있었음을 확인했다고 합니다. 결론적으로, 그래프 학습 피처를 사용한 음식 추천이 샌프란시스코에서 사용되고 있으며, 곧 전 지역으로 확대될 예정이라고 합니다.
4. 데이터 및 학습 파이프라인
추천시스템에서 그래프 표현 학습의 성능을 확인한 후, 모델 학습과 실시간 프로덕션 환경을 위한 확장가능한 데이터 파이프라인을 구축했다고 합니다. 이번 장에서는 데이터 및 학습 파이프라인이 어떻게 구성되어있는지 살펴 봅니다.
또한, 각각의 도시에 대해 모델을 학습했다고 합니다. 이는 그래프가 느슨하게 연결되어 있었기 때문이라고 합니다.
구축을 위해, 익명화 처리된 전체 주문 데이터를 과거 몇 개월에서 가져와 4단계를 거친 데이터 파이프라인을 설계하여 우리의 모델을 학습하기 위해 필요한 networkx 그래프 포맷으로 데이터를 변형시킵니다.
이 파이프라인은 raw한 주문 데이터에서 직접적으로 사용할 수 없는 통합된 피처들도 추출하는데, 이 피처 중에는 유저가 해당 음식을 주문한 총 횟수 같은 피처가 포함되어 있습니다. 이는 앞서 살펴 보았듯이 그래프의 엣지의 가중치로 사용됩니다. 또한, 이 파이프라인은 오프라인 분석에 사용될 수 있는 과거 시간 프레임을 사용한 그래프를 만드는 것이 가능합니다.
아래의 다섯 가지 과정을 그림의 흐름에 따라 설명하겠습니다.
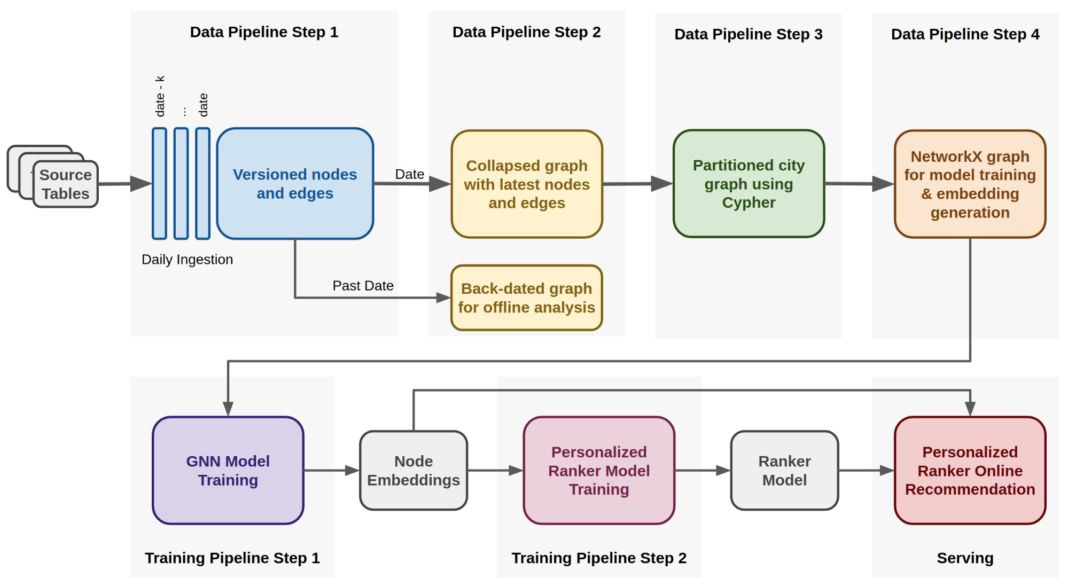
1) 첫번째 파이프라인으로, 아파치 하이브 테이블로부터 데이터를 끌어오는 다수의 job이 실행됩니다. 이들은 parquet 파일 형태로 이 테이블들을 ingest하여 HDFS로 옮깁니다. 이 parquet 파일 내에는 노드와 엣지 정보가 각각 들어 있습니다. 각 노드와 엣지 정보는 timestamp에 따라 버저닝된 특징들(properties)을 가지고 있으며, 이들은 과거 시간을 기준으로 한 그래프를 구축하는데 사용됩니다.
2) 두번째 단계로는, 특정 날짜가 주어졌을 때 각각의 노드와 엣지의 최신 특성을 유지하고, 이들을 HDFS에 Cypher 포맷을 이용해 저장하는 작업입니다.
프로덕션 모델을 학습할 때, 특정된 날짜는 현재의 날짜이지만 과거 그래프를 가져오기 위해 과거 날짜가 특정지어 지더라도 과정은 동일합니다.
3) 세번째 단계에서는, 아파치 스파크 수행 엔진 내에서 Cypher 쿼리 언어를 사용해 도시별로 파티션된 복수의 그래프를 생성합니다.
4) 마지막으로, 도시별 그래프를 networkx 그래프 포맷으로 변환해 모델 학습과 임베딩 생성 과정에 투입합니다. 이 과정은 TensorFlow 프로세스로 구현되며 GPU에서 수행됩니다.
생성된 임베딩은 룩업테이블에 저장되어, 앱이 실행되고 제안 요청이 일어날 때 랭킹 모델에 의해 조회되는 룩업테이블에 저장된다고 합니다.
5. 마치며
지금까지 우버 이츠가 어떻게 GNN을 활용하여 개인화 추천 서비스를 개선했는지를 알아보았습니다.
GNN 모델에서 link prediction을 활용해 직접적으로 추천을 제공하는 방법만을 생각했었는데, 우버이츠에서 사용하는 방식처럼 피처를 생성하는 방식을 적용한다면 기존에 user-item 쌍별 feature를 활용해 예측을 수행하는 프로덕션 레벨의 모델이 존재할 경우 큰 부담 없이 PoC를 수행하고, 실제 적용까지 진행할 수 있을 것 같다는 생각이 들었습니다.
또, 모델을 개션하는 다양한 방법을 접했을 때, 결과물만 놓고 보았을 때는 상당히 놀랍고, 또 어떻게 이런 생각을 했지? 하는 막연한 기분이 들곤 했는데, 그 아이디어가 출발한 계기, 즉 그들이 풀고자 했던 문제와 거기에서 해결책으로 제시된 아이디어 자체는 굉장히 직관적이고 간단한 아이디어였음을 새삼 느끼게 되었습니다.
재미있네요. 앞으로도 이렇게 실제 어플리케이션에 적용한 사례를 공유하는 자료를 자주 공유하려고 합니다. 긴 글 읽어주셔서 감사합니다!
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요. 내용에 대한 지적, 혹은 질문을 환영합니다.
출처
https://eng.uber.com/uber-eats-graph-learning/
https://www.youtube.com/watch?v=9O9osybNvyY&t=939s
Leave a comment