
[Recsys] Next Item Recommendation with Self-Attentive Metric Learning
추천 문제를 해결하는 큰 갈래 중에, 고객 활동의 sequential한 정보를 활용하는 방법론 중 item-item 간의 상관관계를 self-attention 메커니즘을 사용해 파악하고자 한 접근을 살펴봅니다!
안녕하세요! 배우는 기계 러닝머신입니다. ![]()
이번 포스트는 고려대학교 DSBA 연구실에서 유튜브에 공개한 논문 리뷰 발표를 들으며 개조식으로 정리한 글입니다. 좋은 발표를 제공해주신 천우진님께 감사드립니다. ![]()
해당 논문의 원문은 이 링크에서 확인할 수 있으며, 발표 영상은 여기에서, 발표 자료는 이 곳 에서 확인하실 수 있습니다.
Introduction
- 클릭 로그, 구매 이력, page view 등의 개인화된 데이터가 범람함에 따라 이러한 historical data를 활용해 미래의 유저 행동을 예측하고자 하는 연구가 진행되어 옴
- 여러 접근법 중, 유저-아이템 간의 co-occurrence 정보를 활용해 sequential한 패턴을 파악하고자 하는 방법이 존재
-
본 논문에서는 이러한 auto-regressive tendency를 반영해 효율적인 recsys를 고안함.
-
Local-global approach 방법으로 2개로 쪼개어 접근:
- self-attention으로 최근 행동에서 드러나는 item-item interaction 파악 -> short-term representation 획득 (local approach)
- metric learning으로 user-item간의 interaction 파악 -> long-term representation 획득 (global approach)
-
metric learning:
- 정의: 두 정보가 주어졌을 때, 이 정보를 vectorize하는 embedding function과 유사도를 측정하는 metric을 정의하여 학습하는 방식 (ebay second-hand car recsys example 참조)
- self-attention으로 얻은 preference representation과 item embedding 간의 distance를 기반으로, 이를 최소화하도록 학습하는 프레임워크.
- 즉, 좋아하는 상품과 vector space 상에서 가깝게 mapping 되도록 유도하는 학습법을 의미하는 듯.
-
contributions
- sequential rec task의 새로운 프레임워크 제안: self-attention + short & long intents
- 12개 벤치마크 데이터셋에 대해 SOTA 모델들과 큰 차이로 좋은 성능
- hyperparameter와 ablation studies를 다양하게 진행ablation studies: 융삭연구 - 모델, 알고리즘의 특징을 제거해나가며 해당 특성이 모델의 퍼포먼스에 미치는 영향을 연구하는 작업.
- Attention weight를 통한 Visualization 제공
Related Work
-
Sequence-aware Recommender systems
- RNN을 활용해 시간의 흐름에 따른 rating 변화를 파악한 연구가 있었음, 그러나 이는 rating prediction task에 특화됨
- MF with Markov chain: 행동 sequence를 반영하는 Markov-based representation과 + item과의 Matrix Factorization
- Trans 계열 (TransE,TransR): item간의 관계를 다른 공간에 나타내어 학습하는 방법론들
-
Neural Attention model
-
Attention Mechanism: RNN의 long-term dependnecy를 개선해주며, CNN 모델에게는 input의 중요 부분에 집중할 수 있도록 도움
-
Self-attention: input sequence의 attention weight들이 다른 input sequence에 끼치는 영향을 파악, 정확도와 계산 복잡도 측면의 개선 가능
-
AttRec: Short-term intents modeling with self-attention
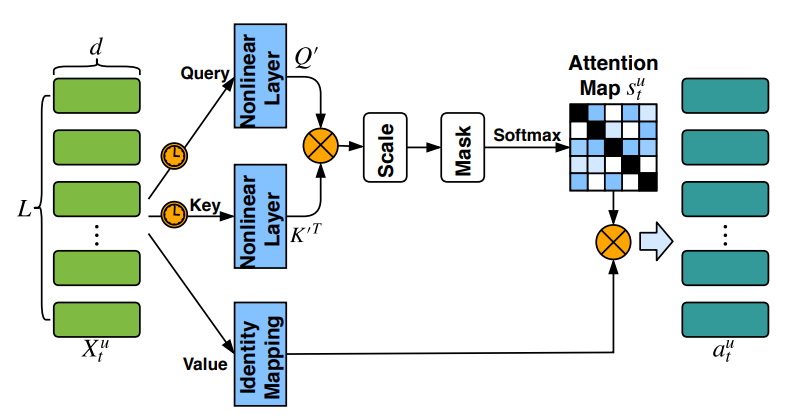
- Self-Attention Module: 최근의 행동을 관찰해 현재의 선호도 정보를 파악함.
- Query, Key, Value 모두 최근 L개의 item으로부터 얻어냄.
- t 시점 기준 최근 L개의 상품을 사용
- 이 L개의 상품을 d차원의 임베딩 벡터로 나타내어 행렬화함 (X_t_u)
- Query와 Key를 Relu를 이용한 non-linear transformation을 통해 같은 공간으로 projection 시킴. Relu 통과 전에, X_t_u 행렬과 Query/key weight matrix를 각각 곱해줌. 이를 통과한 matrix를 Q’, K’으로 정의 (value는 identity mapping)
- 여기서 그대로 Relu에 통과하면 bag of embedding 형식을 가지기 때문에, 시간 순서의 sequential한 정보를 잡아내지 못함. 따라서, 두 time embedding을 각각 XW_Q와 XW_K에 더해줌.
- Q’과 K’^T를 행렬곱하여 Scaling factor sqrt(d)로 나누어준 뒤 softmax를 취해 줌. 이 결과 s_t_u라는 attention score matrix가 나옴. 이 matrix의 크기는 L*L.
- High matching scores (같은 상품은 당연히 높은 attention을 받는 문제를 해소)를 피하기 위해 diagonal element를 mask해줌.
- 최종적으로 얻은 attention map과 L개 아이템의 임베딩을 곱해주어 (value) short-term intent representation을 얻어냄. (L*d의 matrix)
- 모든 시점의 representation을 하나의 벡터 값으로 나타내기 위해 평균 연산 (1*d의 matrix)
AttRec: User Long-Term Preference Modeling
-
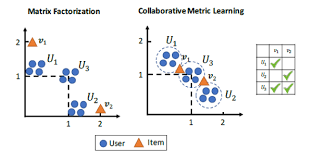
기존에는 item embedding과 user embedding간의 matrix factorization을 통해 interaction을 계산했으나, 이러한 dot product가 metric learning의 inequality property를 훼손하여 sub-optimal로 가게 함.
- 내적을 사용해 embedding하기 때문에, 유저는 좋아하는 상품과는 직선 상에, 좋아하지 않는 상품에 대해서는 수직을 이루도록 학습이 됨. 그러나 두 상품을 다 선호하는 유저의 경우 두 상품 각각의 가운데 위치하게 됨. 이러한 방식의 표현은 손실이 존재할 수 밖에 없음.
- 따라서 (Euclidean) distance 기반의 유사도 measure를 통해 item과 user간 interaction을 표현 (user u가 item i를 선호하면 둘 사이의 distance가 작을 것이다.)
-
Objective Function
- Long-term rec score (user u와 다음 item간의):
- 특정 user와 다음 시점의 item에 대한 embedding
- 해당 user가 다음 시점의 item을 구매/선호할 경우 둘 사이의 거리가 짧아짐.
- user에 대한 general한 preference를 반영한 embedding
-
Short-term rec score (user u와 다음 item간의):
- 이전에 attention의 결과로 얻은 1*d의 short-term preference vector와 다음 item의 임베딩간의 vector 거리를 계산
- 만일 구매한 item이라면 거리가 짧아지도록 학습됨.
- short-term preference와의 관계를 반영하기 위한 embedding
-
위의 1.과 2.에 weight parameter를 곱해주어 선형결합한 값을 y_t+1_u로 사용. 이는 t+1 item을 user u가 선호할 확률을 의미함.
- 이러한 y를 objective function에 사용, user가 관심 있는 positive item과 관심 없는 negative item 사이의 pairwise ranking method를 사용, X,V,U,W를 모두 학습
해당 자료는 고려대학교 DSBA 천우진님의 영상 자료를 보고, 학습한 자료입니다. https://www.youtube.com/watch?v=ei_SMGaWJEw&t=891s
- Long-term rec score (user u와 다음 item간의):
Leave a comment