
[Recsys] HAN(Heterogeneous Graph Attention Networks) paper review
Heterogeneous Network + Graph Attention Networks
다양한 노드 타입을 갖는 Heterogeneous Network의 meta-path 내/외부에 attention을 적용하여 aggregation하는 HAN에 대해 알아봅니다.
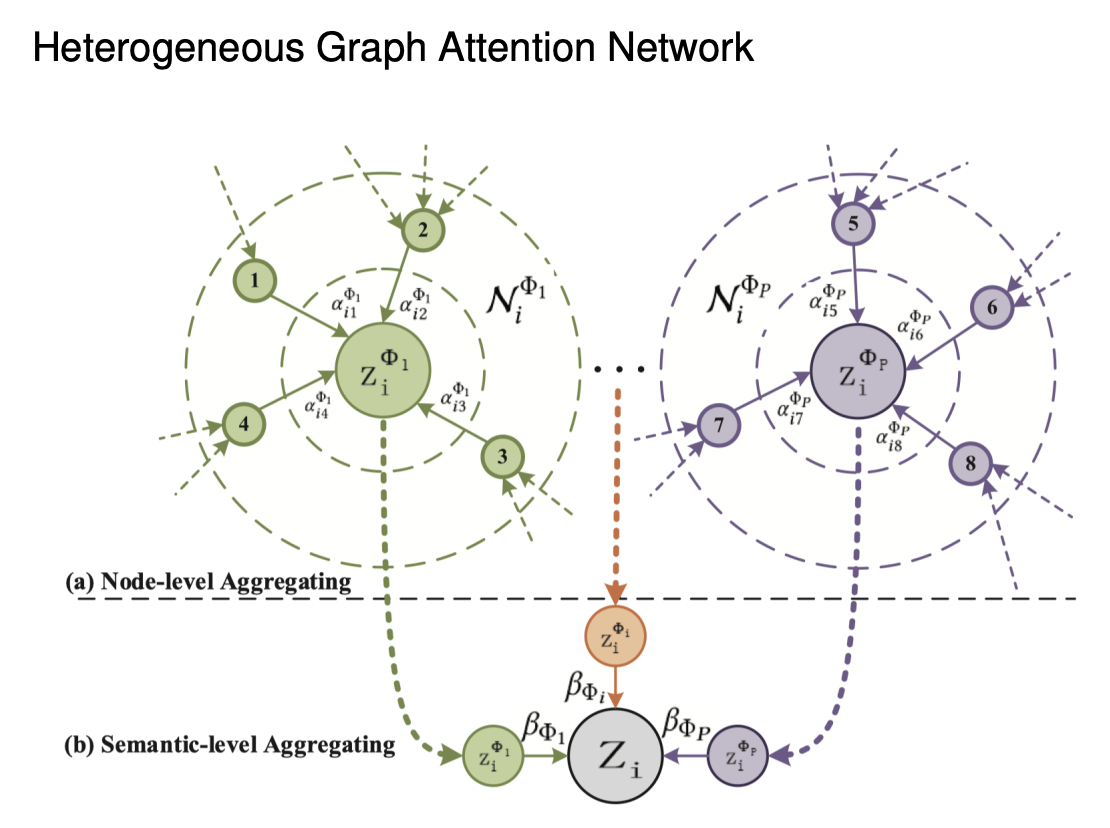
1. 그래프를 meta-path 기반으로 sub graph로 만들어 줌.
2. 그 sub graph 내부의 aggregation(Node-level Aggregation)과 sub graph 간의 aggregation(Semantic-level Aggregation)을 수행함에 있어, Attention score를 구함으로써 가중치 학습
본 포스트는 고려대학교 산업경영공학부 DSBA 연구실 이정호님의 세미나 영상을 토대로 작성한 노트입니다. 영상은 여기에서 보실 수 있습니다.
Contents
- Heterogeneous Network란?
- GAT(Graph Attention Networks) 리뷰
- HAN(Heterogeneous Graph Attention Networks) 알고리즘 소개
- 실험
1. Heterogeneous Information Network
1-1. Heterogeneous Information Network의 특징
- 같은 노드지만 다양한 관계를 가질 수 있음
- 노드들 간의 관계를 동해 다양한 정보를 추출
- Path1: 같은 배우가 출연한 작품
- Path2: 같은 감독의 작품
- 다양한 TYPE 노드를 통해 이웃을 다양하게 정의
- 배우 기준 m1의 이웃: m3
- 감독 기준 m1의 이웃: m2
- 이러한 다양한 관계를 각각 다르게 활용해 주어야 함
- hetero graph는 inductive bias를 추가해 준 것으로 볼 수 있음
1-2. heterogeneous network를 쓰는 이유
1) side information 활용
- 노드의 type, 연결 관계 등에 대한 side info를 활용함으로써 더욱 풍성한 연결 정보를 가져 올 수 있음.
- 기존의 GNN 방법론에 추가적으로 side info를 활용하는 방법론이 제시됨
2) meta path 기반 방식의 한계점
- meta-path 설정은 도메인 지식이 필요하며, 이를 찾고 추출하는 데는 시간이 오래 걸림
- path 설정 시 사용되지 않는 정보가 존재함(손실정보)
2. GAT(Graph Attention Networks) 리뷰
2-1. GAT
- 이웃의 정보를 weighted mean으로 통합함
- 가중치 설정을 위해 trainable attention weight를 사용함
- 어떤 이웃이 나와 유사한가?, 어떤 이웃이 나에게 유익한 정보를 주는가?에 대한 대답을 찾으며 학습
- 기존의 GCN은 모든 이웃에 대한 가중치를 동일하게 두어 mean을 쳐주는 등의 접근을 취했는데, 어떤 이웃이 더 중요한지도 학습하도록 해보자
- 그러한 아이디어에서 제안된 것이 GAT layer임.
2-2. GAT의 두 가지 방식
1) coefficient matrix 활용
- transductive한 방식
- 노드 수 * 입력차원의 입력 매트릭스를, (선형변환 한 뒤 ?) coefficient matrix와 곱해줌으로써 중요도를 계산.
- 인접행렬의 0이 아닌 원소들에 대해 스코어 값을 구하는 형태가 됨. 연결되지 않은 노드 사이에는 마스킹이 처리된 꼴 (실제로 마스킹 처리는 어려움, 구하고 배제하는 식으로 처리)
2) score를 계산하는 learnable parameter 사용 - inductive한 방식
- 두개 노드에 해당하는 벡터를 가져와 learnable parameter에 태우고, 각각의 스코어 값을 계산함
- multi-head attention 방식 적용 가능
3. HAN(Heterogeneous Graph Attention Networks) 알고리즘 소개
3-1. Meta Path 기반 이웃 정의
- meta path는 노드 타입에 따른 다양한 path를 의미하며, 특별한 의미를 가짐
- 각 노드는 노드 타입에 따라 연결되는 형태가 달라지며, 도메인 지식에 따라 유의미한 패턴을 가지는 경우 meta path라고 명명함
- 길이가 지나치게 긴 meta path는 사용하지 않고, 3-5의 길이 정도를 사용
3-2. 제안된 모델
- meta path 내의 각 노드 타입에 따라 선형 변환을 시켜줌. 같은 공간으로 맵핑 시켜줌. 즉 노드 타입에 따라 상이한 공간에 있는 벡터를 모두 동일한 공간에 위치하게 유도함 (이는 다른 논문의 저자들이 노드의 각자 위치를 보존하게 하는 것과 차이가 있다고 함)
- 이로써 source node를 기준으로 다양한 형태의 이웃 노드가 정의됨
- 이렇게 함으로써 통합될 때 유의미한 정보를 가지고 올 수 있다고 저자들은 주장함
- 학습할 때는 이웃의 타입에 따라 고유한 서브 그래프를 구성함
- 각 관계별로 상이한 attention을 수행
3-3. 각 관계별 Attention 수행
- 앞서 같은 차원으로 임베딩해주는 과정을 거친 뒤, 각 path별로 sub graph를 나눔
- ex) 유저-감독-유저 등
- 이렇게 sub graph를 나눈 뒤 graph attention으로 aggregation한 정보를 다시 한번 2-step으로 통합하는 과정을 거치는 것이 이 논문에서 제시한 방법임
3-4 모델 학습 시나리오
- 유저-감독 sub graph와, 유저-영화 sub graph 등이 나누어져 있는 상황
- 각각의 노드는 20차원으로 init 되어 있음. 앞에서 w parameter를 통한 임베딩 과정이 multi-head를 통해 나옴으로써 이러한 20차원의 벡터가 여러개씩 있음
- 먼저 유저-감독 sub graph를 가지고, 각 multi-head마다, 각각의 유저 20차원 감독 20차원의 벡터가 있을 것임
- 이를 concat하여 40차원으로 만들고, 여기에 40차원짜리 공유된 weight learnable parameter를 곱해 줌으로써 attention score에 해당하는 scalar값이 나옴 (target node와 source node 사이의 attention score)
- 여기서는 S1,S2라는 두 개의 감독 노드로부터 0.5, 0.3이라는 스코어가 각각 나왔다고 해보겠음
- 이렇게 구해진 weight에 따라서, source node t를 업데이트 함에 있어 S1의 vector는 0.5의 비중, S2의 vector는 0.3의 비중으로 propagation받음
- 마찬가지로 유저-영화 sub graph가 있을 때 동일한 방식으로 40차원짜리 공유 weight learnable parameter와 concat vector를 내적, score를 구해주고 가중치로 사용, 업데이트
- 이제 두 meta-path 간의 정보 공유를 할 차례임. 지금까지 둘 사이의 정보 공유는 없었음
- 업데이트 후 각각의 meta path별로 구해진 20차원의 노드 벡터 2개를 각각 다시 fully connected layer에 태움. 이는 path type에 상관없이 공유되는 learnable parameter임. activation function을 hyperbolic tangent function에 태움으로써 -1~1사이의 값으로 변환해 줌
- multi-head마다 각각 이러한 작업을 수행하여 다시 20차원의 벡터를 얻어냄
- 이 얻어낸 20차원의 path별 벡터를 path와 상관없이 공유되는 20차원짜리 learnable parameter attention vector와 곱해 줌으로써 path별 attention을 구해줌
- 유저-감독에는 0.8, 유저-영화에는 0.2라는 스코어가 나온다고 해보겠음
- 유저-감독에서 업데이트된 t의 20차원 벡터에는 0.8의 가중치를, 유저-영화에서 업데이트된 t의 20차원 벡터에는 0.2의 가중치를 적용해서 통합
- 최종 loss는 semi-supervised 방식의 cross-entropy 사용
- 최종적으로 얻어낸 3개의 multi-head에서의 t 노드에 대한 20차원 벡터 3개를 concat하여, cross-entropy 로스 적용
- movie node의 라벨을 통해 학습을 진행 (액션, 코메디, 드라마 등)
- label이 없는 타입 혹은 명명되지 않은 label은 supervised loss에는 포함되지 않음
- 분류기는 KNN(k=5) 사용
4. 실험
- DBLP/ACM: 논문 자료
-
IMDB: 영화 추천
- HAN이 가장 효과가 좋았다
- 2가지 attention을 사용하지 않고, 그냥 attention을 사용하면 GAT와 동일한 구조인데, 새로 적용한 방법이 도움이 되었다고 주장(GAT보다 잘 되니까)
- GCN, GAT에서는 클러스터링 결과가 좀 섞여 나오는데, metapath2vec, HAN의 경우 잘 뭉쳐짐. 물론 HAN이 metapath2vec보다 더 잘됨
- attention 시각화: 방법론의 정성적인 의미 확인
- 자기 자신의 attention이 가장 크고, 다른 큰 노드는 실제로 유의미한 것들이었음 (유사한 학회의 논문들)
- 가장 약하게 걸린 애는 관련이 매우 적은 논문
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요. 내용에 대한 지적, 혹은 질문을 환영합니다.
Leave a comment