
[RecSys] 온라인 행동 예측을 위한 Neural-network Field-aware Factorization Machine
Inmobi에서 온라인 유저 행동 예측을 위해 Neural-network Field-aware Factorization Machine을 적용한 사례를 알아봅니다.
부제: Why Neural net Field Aware Factorization Machines are able to break ground in digital behaviours prediction

1. 온라인 유저 행동 예측을 위해, 선형 모델으로부터 시작해 다양한 구조의 Factorization Machine 기반 모델을 적용
2. FM(Factorization Machine), FFM(Field-aware Factorization Machine), DeepFM(Deep neural net with FM), NFM(Neural Factorization Machine), DeepFFM, NFFM(Neural Feature-aware Factorization Machine)을 적용, 각각의 실험 결과와 장단점을 설명. 결론적으로는 NFFM이 우수한 성능을 보임
3. 이러한 모델을 학습하고 서빙하기 위한 디테일한 설정을 소개
본 포스트는 Inmobi의 Gunjan Sharma가 발표한 영상을 토대로 작성한 노트입니다. 영상은 여기에서 보실 수 있습니다.
Contents
- 들어가며
- 배경 설명
- Factorization Machine 계열 모델의 실험 결과
- NFFM(Neural Feature-aware Factorization Machine) 구현 디테일
1.들어가며
InMobi는 글로벌한 온라인 타겟 광고를 제공하는 기업입니다. 이러한 기업의 매출 성과를 위해서는 온라인 상의 유저 행동을 예측하는 것이 매우 중요한데요. 좋은 성능의 추천 모델은 곧 수십억의 매출 향상과 직결되기 때문에, 비즈니스 성공을 위해 우수한 모델을 개발하는 일이 필요한 상황이었다고 합니다.
Inmobi의 엔지니어들이 최종적으로 NFFM (Neural-network Field-aware Factorization Machine) 모델을 개발하기 까지 다양한 Factorization Mahcine 기반 모델을 적용한 이야기를 공유해 주었고, 이 포스트에서는 그 영상에 담긴 이야기를 간략하게 정리해 보도록 하겠습니다.
2. 배경 설명
2-1. Existing context and challenges
- 일반적으로 linear/logistic 모델과 tree-based 모델을 주로 사용함.
- 실제 적용될 경우 두 모델은 각각의 장단점을 가짐.
- Linear Regression: unseen combination에 대해 잘 일반화함, 때때로 underfit될 가능성 존재, 더 적은 RAM 필요
- Tree model: unseen combination에 대해 잘 일반화 못함, 때때로 overfit되며, 종종 RAM을 터지게할 수 있음. 특히 매우 많은 수의 feature를 사용할 경우 메모리 이슈 발생.
- 우리는 이 두 모델의 가운데에 있는 어떤 모델을 찾아 성능을 극대화하고 싶음.
2-2. Why think of NN for CVR/VCR prediction
- LR(Linear Regression)에 cross feature를 사용하는 것은 현 문제에 적합하지 않았음
- 또한 때때로 학습과 예측 단계에서 다루기 까다로워짐(cumbersome)
- 여기서 언급된 모든 주된 예측 작업은 복잡한 곡선을 따름
- LR 모델은 interaction term이 제한되어 있어 트리 기반에 비해 개선의 여지가 컸음
- 몇몇 효과적인 모델을 적용해 보았으나 트리 기반의 모델을 이길 수 없었음.
- 우리의 팀은 피처들 간의 고계(high-order) interaction을 찾아내기 위해서는 뉴럴넷이 필요하다고 판단했음
- 뉴럴넷은 unseen combination에 일반화하는 성능도 가지고 있음.
2-3. Challenges involved
- 전통적으로 뉴럴넷은 분류 문제에 더욱 활용되고 있음
- 우리의 예측을 regression으로 모델링하고 싶었음
- 대부분의 피처가 카테고리형이었고 이 말은 one-hot encoding을 사용해야함을 의미함.
- 효과적인 학습을 위해 아주 많은 데이터를 요구하기 때문에 NN모델은 좋지 않은 성능을 내기 마련이었음.
- 몇몇 피처는 매우 많은 수를 포함하고 있었고 이는 학습을 더 어렵게 함.
- 모델은 학습과 서빙을 위한 운용이 쉬워야함
- spark는 custom 뉴럴넷에 적합하지 않았음
- 모델은 쉽게 디버깅되고, 비즈니스 변화를 설명할 수 있어야함
- 뉴럴넷을 오랫동안 사용하지 않았던 이유는 이해가 부족해서였음
3. Factorization Machine 계열 모델의 실험 결과
3-1. FM(Factorization Machine)
- 각각의 카테고리형 변수에 대해 k차원의 latent vector가 있음
- 이 k는 하이퍼 파라미터임
- 예를 들어 3개의 카테고리 변수 PV(publisher latent vector), AV(Advertiser latent vector), GV(Gender latent vector)가 있고, 각 각 카테고리 변수에는 3(퍼블리셔가 SONY인지, CNBC인지, ESPN인지)/4(아디다스인지, 나이키인지, 코카콜라인지, P&G인지)/2(남성인지 여성인지)의 cardinality를 갖는다고 할 때 최종 예측 확률(pCVR)은 $PV^T \cdot AV+AV^T \cdot GV+GV^T \cdot PV$로 계산함. (여기서 $\cdot$는 내적)
- 즉, 각 카테고리에 해당하는 피처간의 유사도를 계산하여 총합을 내림.
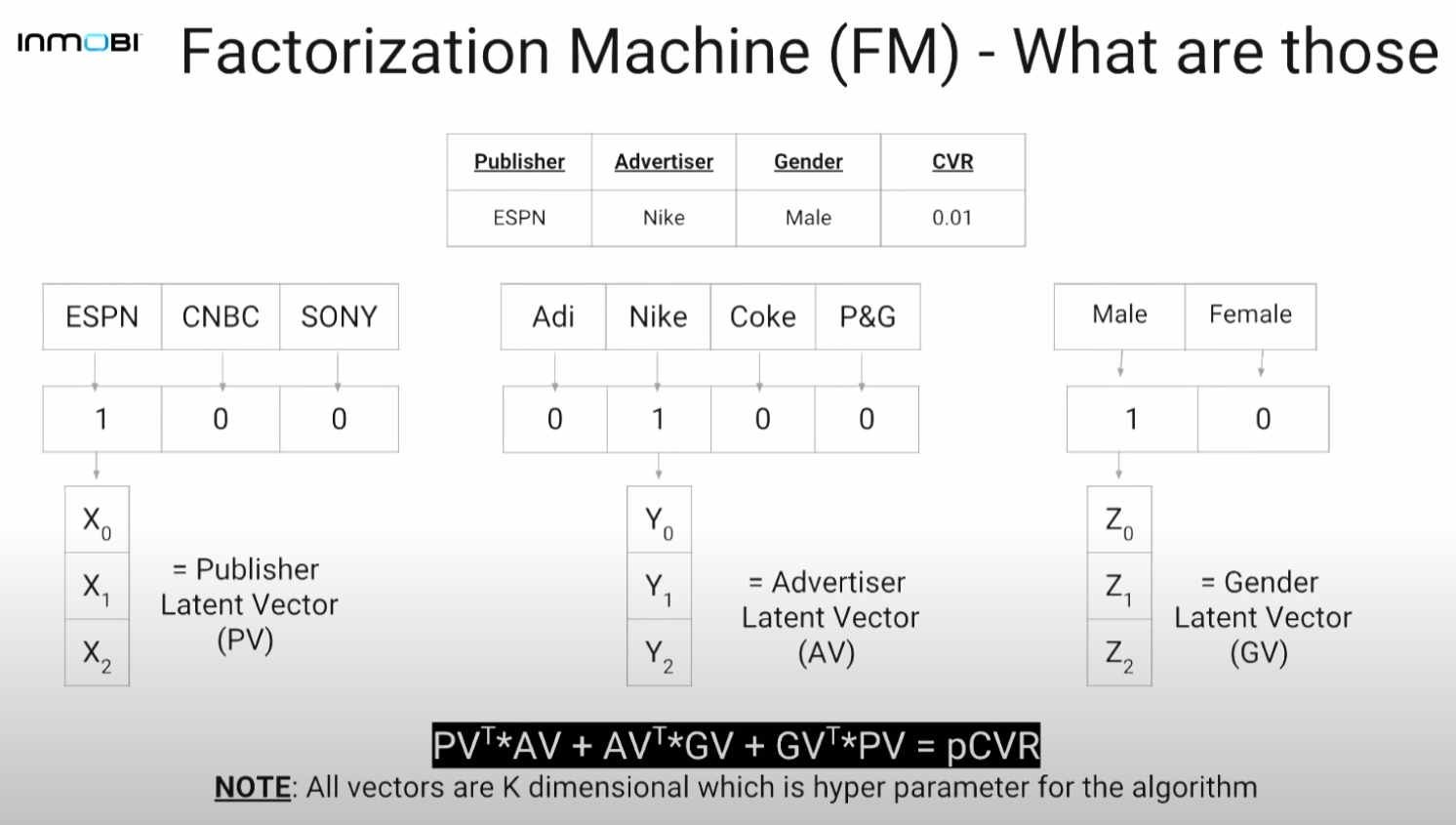
3-2. FM(Factorization Machine) 계속
- 각각의 feature value에 대해 k차원의 representation을 사용함
- 모든 피처들에 대한 second-order interaction을 잡아냄
($A^TB=\mid A\mid \cdot \mid B\mid \cdot cos(\theta)$) - 기본적으로 쌍곡선(hyperbola)의 결합의 총합이 최종 예측에 사용됨
- LR 모델보다는 효과가 좋지만 여전히 트리 기반의 모델보다는 강력하지 못함
- 영화의 매출을 예측하는 모델을 예시로 들어 설명해 보겠음.
- feature는 영화, 성별, 도시를 들 수 있고, latent feature는 액션, 코미디, 호러 등을 들 수 있음.
- second-order interaction의 직관: 모든 latent feature에 대해, 모든 original feature쌍에 대해 이 pair들을 감안했을 때 해당 latent feature가 얼마나 매출에 영향을 미치는가를 반영
- 최종 예측값은 모든 latent feature에 걸친 선형 총합(linear sum)임
- 두 벡터간의 내적을 취해주는 것은 latent feature space내의 유사도를 구해주는 것
3-3. FFM(Field-aware Factorization Machine)
- FM의 진화된 형태로, 한 feature에서 latent vector를 만들 때 다른 카테고리(Field)에 대한 latent vector를 각각 만들어서 학습시킴.
- 최종 예측 확률(pCVR)은 $PV_A^T \cdot AV_P + AV_G^T \cdot GV_A+GV_P^T \cdot PV_G$로 계산
- 손실함수는 RMSE를 사용할 수 있음. 이를 역전파를 사용해 학습하여 각각 그리고 모든 interaction의 값을 학습할 수 있음
- FM과 마찬가지로 k차원의 latent vector를 사용하지만 각각의 cross feature에 대해 개별적인 latent vector를 갖는 것이 차이점임
- FM처럼 second order interaction이지만 자유도(degree of freedom)가 더 높음.
- 직관: latent feature들이 다른 cross feature들과 다르게 상호작용함.
- FM보다 훨씬 낫지만, 트리기반 모델을 이기지는 못함

3-4. Deep neural net with FM: DeepFM
- FM과 딥러닝 아키텍쳐를 함께 사용하는 모델로, sparse feature에서 dense embedding을 뽑아 각각 hidden layer와 FM에 투입함. 그 결과값을 addition으로 결합하여 sigmoid를 태우고 확률값의 형태로 출력
- sigmoid(FM+ NeuralNet(PV:+AV:+GV))=pCVR
- 이 모델은 NN모델과 FM모델의 결합으로, 최종 출력값은 두 모델의 출력값의 합임.
- 여기서는 전체 그래프를 한번에 최적화함.
- 이 모델은 FM에서 얻은 latent vector를 두번째 최적화로써 뉴럴넷에 태우는 것보다 더 나은 성능을 보임(FNN)
- FM보다는 낫지만 FFM보다는 나쁜 성능
- 직관: FM은 second order interaction을 찾고, 뉴럴넷은 latent vector를 사용해 higher order nonlinear interaction을 찾음.
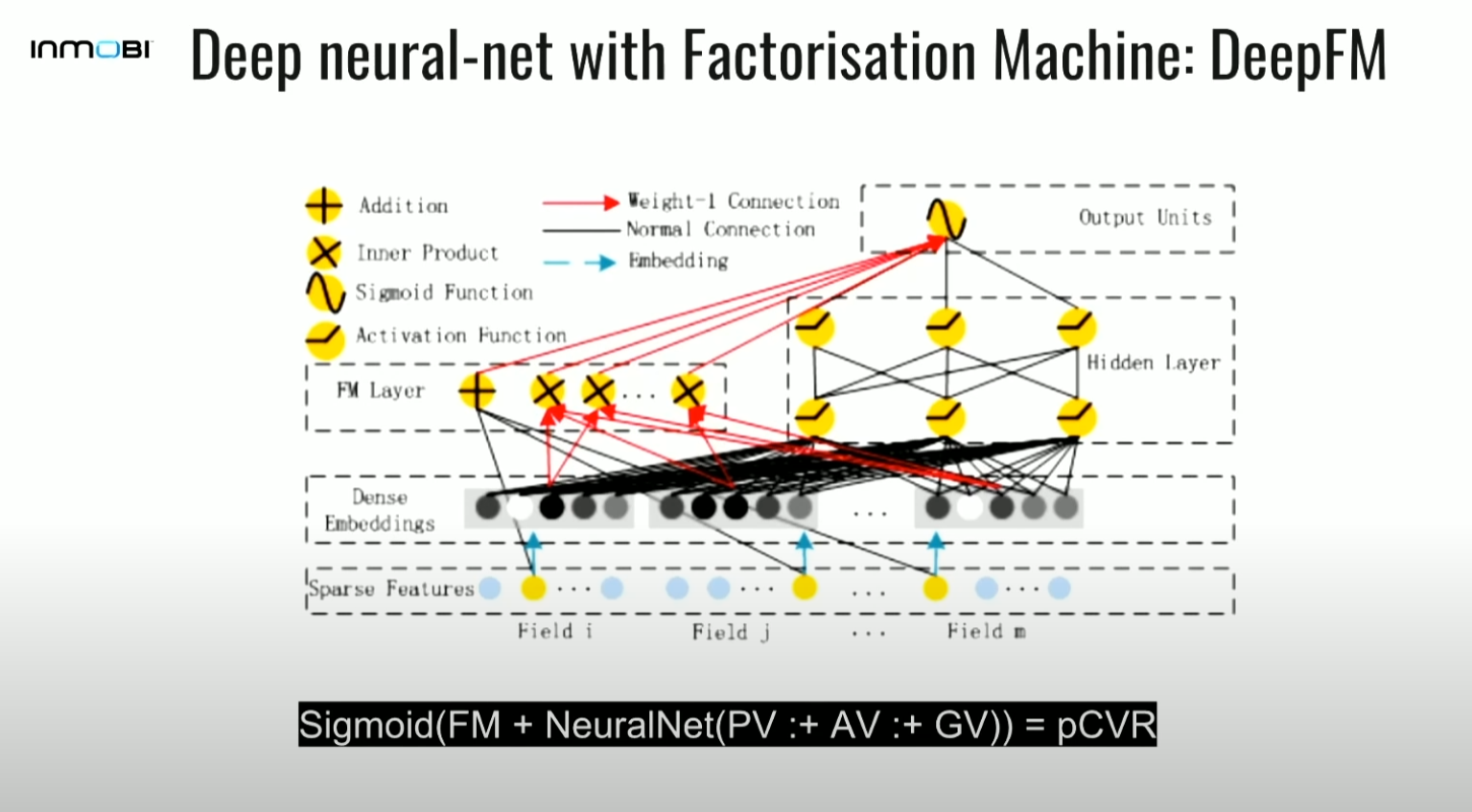
3-5. Neural Factorization Machine: NFM
- sparse vector를 입력받아 입력된 feature에 상응하는 latent vector를 bi-interaction pooling layer를 거침으로써 second order interaction의 정보를 구하고, 이를 뉴럴넷에 통과시킴
- raw latent vector 대신에 second order feature를 뉴럴넷에 통과시킴.
- NeuralNet(PV. $\cdot$ AV.+AV. $\cdot$ GV.+GV. $\cdot$ PV)=pCVR
- 직관: 뉴럴넷은 second order interaction을 입력받아 higher order nonlinear interaction을 찾음.
- DeepFM보다 더 나은 성능을 보임. 이는 아래의 두 이유때문임.
1) 네트워크의 크기가 더 작음으로써 수렴이 더 빨리 이루어짐.
2) 뉴럴넷이 second order interaction을 입력받아 higher order interaction으로 쉽게 변형할 수 있음. - 그러나 여전히 FFM보다는 낫지 않은 성능
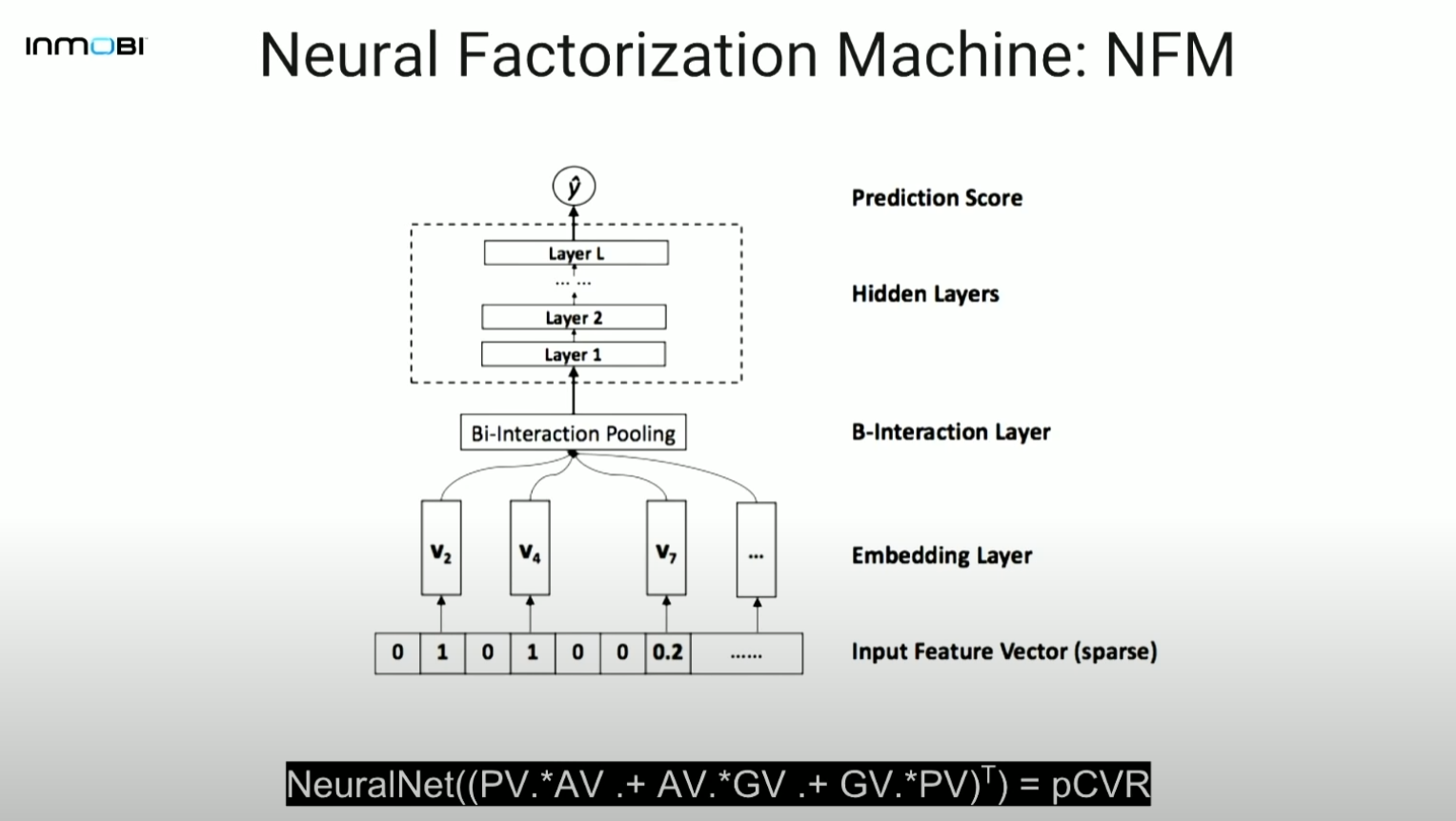
3-6. DeepFFM
- DeepFM의 간단한 업그레이드 버전임.
- DeepFM, FFM보다 더 성능이 좋음.
- 학습이 느림
- FFM part가 예측의 heavy lifting에 큰 부분을 차지. 이는 더 빠른 gradient convergence 때문으로 보임.
- 직관: latent vector를 취해 뉴럴넷에 넣어 high order interaction을 얻고 FFM으로 second order interaction을 학습함
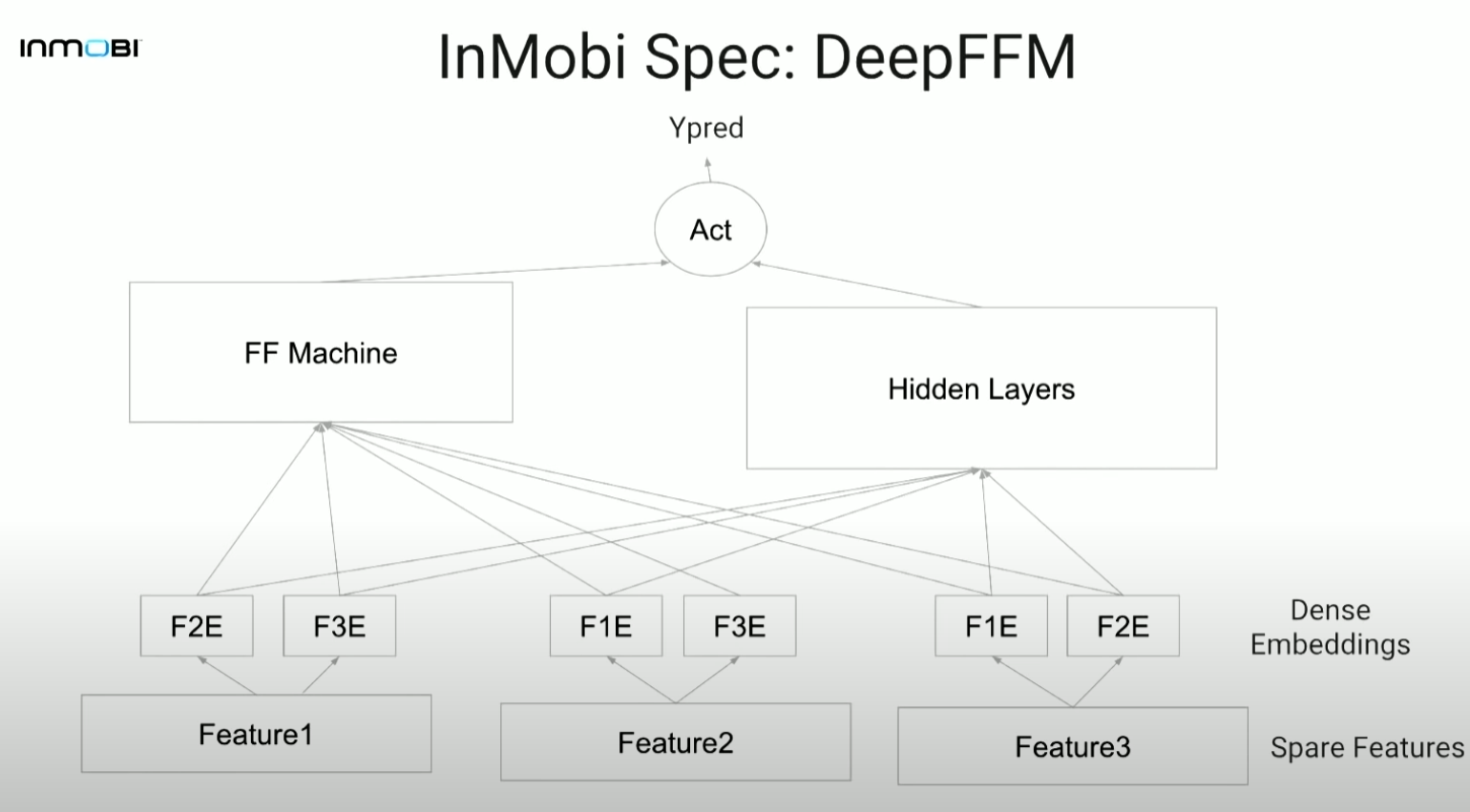
4. NFFM(Neural Feature-aware Factorization Machine) 구현 디테일
4-1. NFFM(Neural Feature-aware Factorization Machine)
- NFM의 FFM 버전, simple upgrade of NFM으로 볼 수 있음
- 최종적으로 적용한 모델
- 다른 어느 모델보다 유의미하게 좋은 성능
- DeepFFM보다 더욱 빠른 수렴
- 직관: FFM으로부터 second order interaction을 얻어 이를 뉴럴넷에 태움으로써 higher order nonlinear interaction을 얻음.
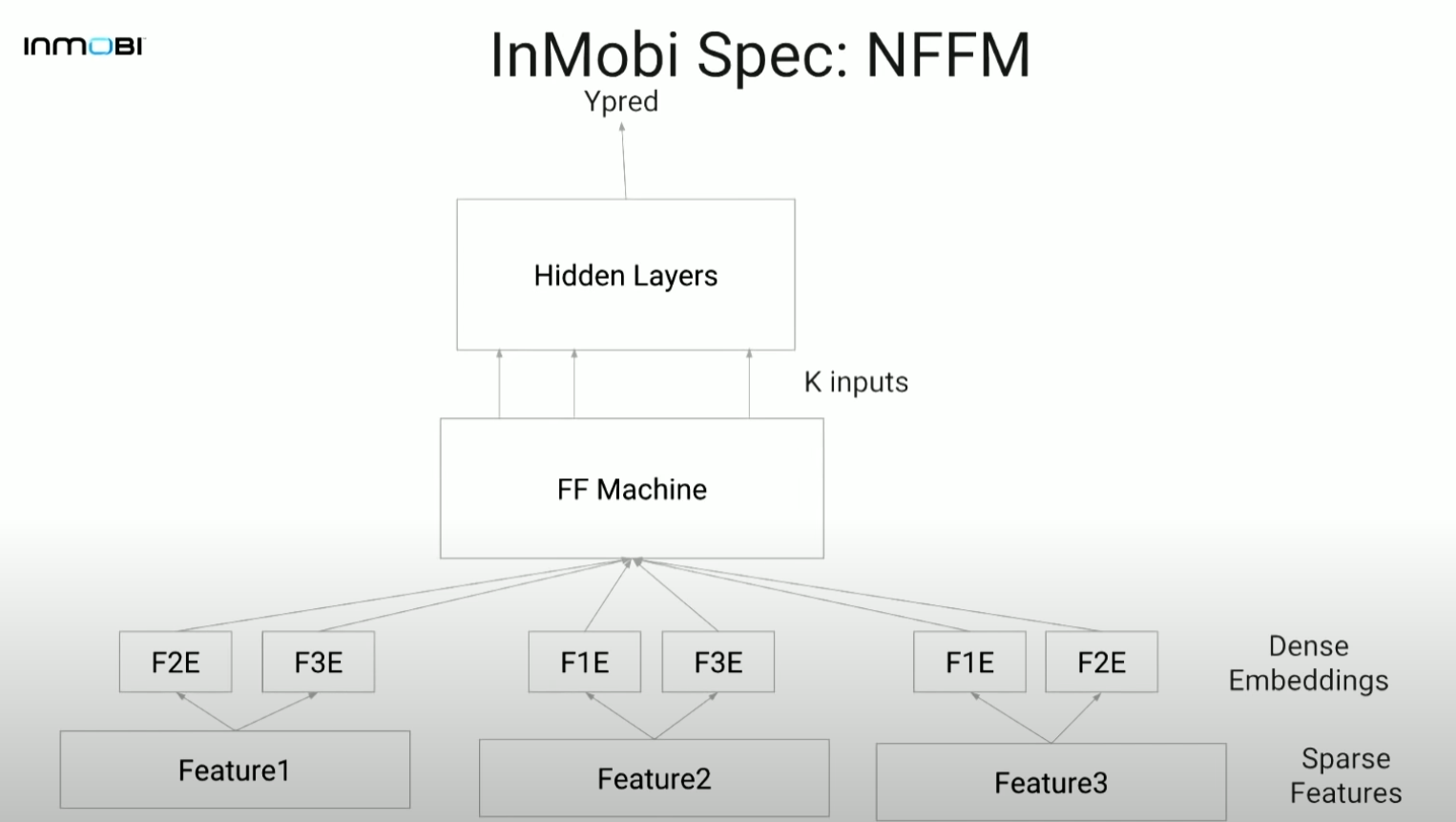
4-2. Implementation details
- Hyperparameters: k, lambda, num of layers, num of nodes in layers, activation functions
- Tensorflow로 구현됨
- Adam optimizer
- L2 regularization, no dropout (추후 테스트 해볼 예정)
- no batch norm (추후 테스트 해볼 예정)
- 1 layer에 100개 노드로도 충분히 작동하고 잘 수렴함, 수가 늘어날수록 성능은 좋을 수 있으나 학습 시간이 길어짐
- Relu activation: 빠른 수렴
- k=16 (2의 제곱수로 실험해봄) 논문에는 수가 늘어날수록 성능이 좋아진다는 말이 있었으나 학습 시간 대비 효과가 없어 16으로 선정
- 두 사용 사례에 모두 손실함수로써 weighted RMSE을 적용함. 여기서 가중치는 특정 combination을 볼 확률을 의미
- unseen feature value에 대한 예측은, 같은 필드 내의 다른 latent vector를 평균내어 사용
4-3. implementing at low-latency, high-scale
- MLeap: Spark와 Tensorflow로 학습된 모델을 지원하는 프레임워크로, 트리 기반 모델 학습을 위해 스파크로, 뉴럴넷 기반 모델 학습을 위해 텐서플로로 모델을 구현하는 데 도움을 줌
- offline training and challenges: yarn 클러스터에서 TF 모델을 학습할 수 없으므로, HDFS에서 데이터를 끌어오는 게이트웨이로써 GPU 머신을 사용하여 GPU에서 모델을 학습
- Online serving challenges: TF serving은 상당히 낮은 처리량(throughput)을 가지고(즉 느리고), 우리의 QPS에서 잘 scale되지 않았음. 우리는 decent TTL을 가진 로컬 LRU 캐시를 사용해 TF serving을 scale up함
- 이 아이디어는 먼저 대부분의 경우에 캐시로 접근하고, 처리가 안되면 그때야 TF 서빙으로 가서 값을 받아옴으로써 처리를 효율적으로 하는 것
- (참고: throughput이 높다는 것은 가벼운 모델을 의미하고, throughput이 낮다는 것은 무거운 모델을 의미함)
4-4. Future Works
- hybrid binning NFFM: FE에서 사용되는 binning을 적용해 NFFM
- 분산처리된(distributed) training and serving
- Dropouts & Batch norm
- latent vector를 interpret 할 방법 (t-SNE 사용 등)
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요. 내용에 대한 지적, 혹은 질문을 환영합니다.
출처
https://www.youtube.com/watch?v=MMTuoFFRCCs
Leave a comment