
[RecSys] 연관 규칙 추천 (Association Rule Mining)
추천 시스템의 가장 원시적이지만 강력한 Baseline으로 사용되는 Association Rule에 대해 배워봅니다.
기저귀를 샀던 김씨는 맥주도 사던데, 당신도 기저귀를 샀으니 맥주를 사는거 어때요?
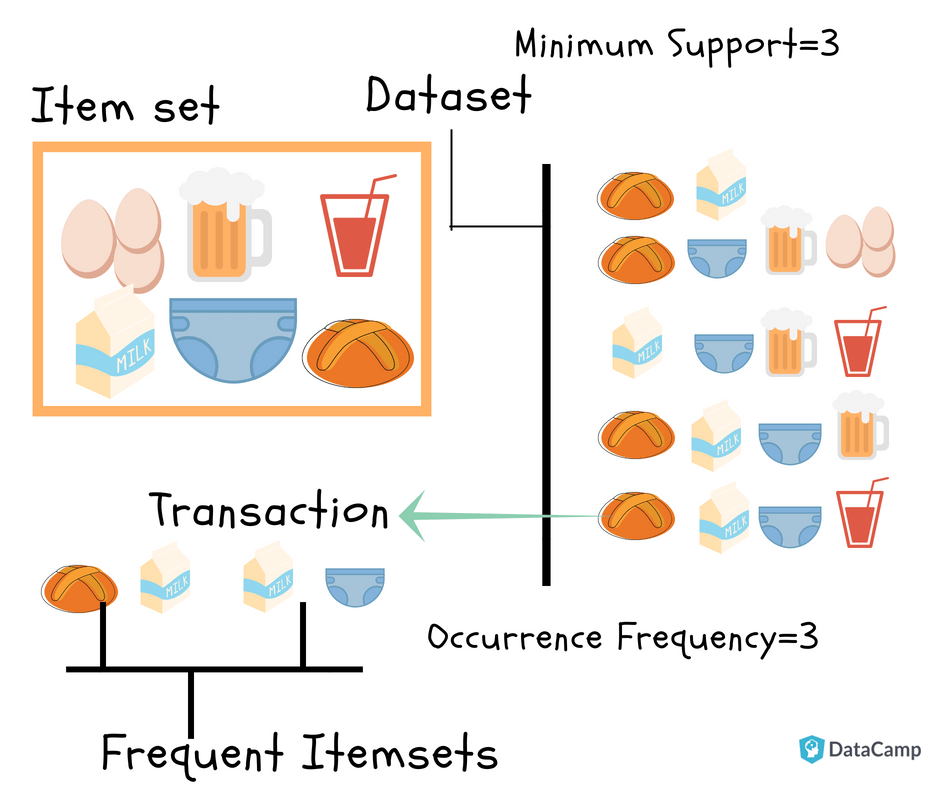
1. 연관 규칙 추천은 “A를 사면 B도 산다”는 규칙을 찾는 것
2. “A를 사면”은 조건절(antecedent), “B도 산다”를 결과절(Consequent)이라고 부름
3. 오직 빈번하게 등장하는 아이템 셋에 대해서만 고려하는 A priori 알고리즘을 적용해 빠른 규칙 생성이 가능
4. 파이썬의 mlxtend 라이브러리를 통해 쉬운 구현이 가능함
Contents
1. 연관 규칙 추천(Assocication Rule based Recommendation)이란?
연관 규칙 추천이란, 어쩌면 이 글을 읽는 많은 분들이 데이터 마이닝, 혹은 빅데이터의 개론 강의에서 한 번쯤은 접해봤을 “기저귀와 맥주” 예시와 관련이 있습니다. 얼핏 어울리지 않는 “기저귀”와 “맥주”가 같이 자주 팔린다는 패턴을 활용해 추천을 한 일화, 혹시 들어 보셨나요? 장을 보러 온 부모님이 자신들이 마실 맥주를 구매하는 것이 매우 지당한 이야기 같지만, 데이터 없이 이러한 연관을 떠올린다는 것은 매우 힘든 일일 것입니다.
이처럼 연관 규칙 추천의 접근법은, 얼른 말해 “A를 사면 B도 산다”는 규칙을 찾는 것인데요. 이를 찾아내는 방법은 전체 거래 내역을 살펴 보아, “A를 사는 사람은 B도 산다”라는 패턴에서 규칙을 찾아내는 것입니다. 정리하자면, “A를 사는 사람은 B도 사던데, 당신은 A를 샀으니 B라는 상품은 어떠세요?” 하며 추천하는 접근이죠.
이처럼 다양한 item이 등장하는 전체 거래에서 특정 item이 연결되는 방법, 그리고 그 이유를 결정하는 규칙을 발견하기 위한 학습 방법론입니다. 이는 Market Basket Analysis, Affinity Analysis로도 알려져 있습니다.
복잡하고 거대한 딥러닝 기반 추천시스템도 특정 도메인에서는 잘 튜닝된 연관 규칙 추천 모델을 쉽게 이기지 못할 정도로 단순하지만 강력한 방법입니다. 그럼 이제 시작해 보겠습니다.
2. 데이터 형태와 용어 설명
2-1. 용어 설명
먼저, 연관 규칙 추천에서 사용되는 용어를 살펴보겠습니다. 앞서서, 연관 규칙 추천은 “A를 사는 사람은 B도 산다”라는 패턴을 찾아낸다고 했는데요. 이 서술을 둘로 쪼개어 보면, “A를 사면”과 “B도 산다”로 나누어볼 수 있겠습니다.
이 앞부분에 해당하는 “A를 사면”은 조건절(antecedent) 이라고 하고, “B도 산다”를 결과절(Consequent) 이라고 합니다. 각각 “IF”와 “THEN”으로 연결지어 이해할 수도 있겠습니다. 또, Item Set이란 이 조건절과 결과절을 구성하는 상품의 집합을 나타냅니다. 여기서 조건절에 들어가 있는 상품과 결과절에 들어가 있는 상품은 상호 배반적(mutually exclusive, disjoint)이어야 합니다.
- (햇반, 김치) -> (맥주, 땅콩) : 가능
- (맥주, 땅콩) -> (맥주, 기저귀) : 불가능
2-2. 연관 규칙 생성
이제 이러한 규칙을 생성해 볼 차례입니다. 하나의 장바구니, 가령 “기저귀, 맥주, 김치”가 있을 때, 많은 규칙을 만들어낼 수 있을 것입니다.
예를 들면,
1) 만약 기저귀가 구매되면, 맥주도 같이 구매된다
2) 만약 기저귀와 맥주가 구매되면, 김치도 같이 구매된다
3) 만약 김치가 구매되면, 맥주도 같이 구매된다
등이 가능하겠죠.
이러한 경우의 수는 장바구니 내의 상품의 수에 따라 급속도로 증가하는데, 가령 6개의 아이템으로 구성된 인벤토리라 할지라도 수백개의 규칙이 가능해져버리게 됩니다. 이 때 불필요한(성능이 낮은) 규칙을 배제하기 위해, 다양한 성능 지표를 적용하여 연산 효율화할 수 있겠죠. 이 장에서는, 이러한 지표를 먼저 알아봅니다. 그 전에, 데이터의 형태는 어떤지 먼저 보겠습니다.
2-3. 데이터 형태
데이터셋은 아래의 테이블처럼 장바구니 형태로 구성됩니다. 각각의 장바구니를 영수증으로 생각해도 됩니다. 이 때, 구매한 상품의 수량은 고려하지 않습니다. 햇반 10개를 사든, 1개를 사든 모두 동일하게 햇반입니다.
[장바구니 형태]
| 장바구니 번호 | 구매 상품 |
|---|---|
| 1 | 햇반, 김치 |
| 2 | 햇반, 맥주, 땅콩 |
| 3 | 기저귀, 맥주, 김치 |
| 4 | 햇반, 김치, 기저귀, 맥주 |
| 5 | 햇반, 김치, 기저귀 |
| 6 | 김치, 맥주, 땅콩 |
아래의 형태 외에도, 각각의 상품을 하나의 칼럼으로 갖는 행렬의 형태로도 표현할 수 있습니다.
[상품 행렬 형태]
| 장바구니 번호 | 햇반 | 김치 | 맥주 | 기저귀 | 땅콩 |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 |
| 2 | 1 | 0 | 1 | 0 | 1 |
| 3 | 0 | 1 | 1 | 1 | 0 |
| 4 | 1 | 1 | 1 | 1 | 0 |
| 5 | 1 | 1 | 0 | 1 | 0 |
| 6 | 0 | 1 | 1 | 0 | 1 |
2-4. 규칙 성능 지표
1) 지지도(Support)
$Support(A \rightarrow B) = P(A) \space or \space P(A,B)$
첫번째로 살펴 볼 지표는 지지도입니다. 지지도는, A라는 조건이 등장할 확률($P(A)$)을 의미합니다.
하지만, 대부분의 패키지에서는 후자의 형태, 즉 A와 B가 동시에 등장할 확률 ($P(A,B)$)로 구현합니다.
지지도는 빈번히 등장하는 상품 집합을 찾기 위해 사용합니다. 지지도가 높을수록, 이 규칙을 적용할 가능성이 높아집니다. 지지도가 높은 상품 집합은 우리의 장바구니에서 자주 등장하는 조합이니 자주 노출 될 가능성이 더욱 높겠죠?
2) Confidence(신뢰도)
$Confidence(A \rightarrow B)= \frac{P(A,B)}{P(A)} = P(B \mid A)$
A라는 상품이 주어졌을 때 B 상품이 등장할 조건부 확률을 나타냅니다. 지지도가 단순히 “같이 등장하는” 빈도만을 반영한다면, 신뢰도는 “A라는 상품이 장바구니 내에 주어졌을 때 ($P(A)$)”를 전제함으로써 유의미한 규칙만을 추려냅니다.
3) Lift(향상도)
$ lift(A \rightarrow B)= \frac{P(A,B)}{P(A)}*P(B) $ 향상도는, 생성된 규칙이 얼마나 유용한지를 나타내기 위해 사용합니다. 향상도는 1을 기준으로 더 높으면 긍정적인 관계, 더 낮으면 부정적인 관계를 의미합니다.
- lift가 1이면 A와 B는 통계적으로 독립
- lift > 1은 A와 B 사이에 긍정적인 관계
- lift < 1은 A와 B 사이에 부정적인 관계
lift가 1.25라면, 햇반과 김치가 독립이라고 가정했을 때에 비해서 0.25개가 더 팔렸다는 의미가 됩니다. 따라서 그만큼 효과적인 규칙이라는 의미입니다.
confidence로도 충분히 이런 목적을 이룰 수 있을 것 같은데, 왜 향상도가 필요할까요?
장바구니에 기본 아이템이 포함되어 있을 경우, 가령 스몰비어 집에서 맥주의 경우 맥주가 포함된 거래에서 모두 confidence는 높지만 lift는 낮을 것입니다.
4) Leverage(레버리지)
레버리지는, A와 B가 독립적이라고 가정할 때의 결합 확률(joint probability)과 실제 결합 확률의 차이를 나타냅니다.
$ leverage(A \rightarrow B) = P(A,B) - P(A) \times P(B)$
이를 사용하면, 해당 규칙에서 등장하는 상품들이 얼마나 유의미하게 같이 등장하는지를 살펴볼 수 있습니다.
5) Conviction(확신도)
확신도(conviction)는 통계적으로 독립일 때와 비교해 보았을 때 얼마나 규칙이 강력한지를 측정하는 데 쓰입니다.
$ Conviction( A \rightarrow B) = \frac{1-Support(B)}{1-Confidence(A \rightarrow B)} = \frac{P(A) \times P(\hat \space B)}{P(A \cup \hat \space B)}$
여기서, $P(\hat \space B)$는 B가 결제에서 등장하지 않을 확률을 의미합니다.
확신도는 ‘A와 B가 독립적이지 않을 경우 A가 B 없이 등장할 확률’과 ‘A가 B 없이 등장한 실제 확률’를 비교하게 됩니다. 일반적인 신뢰도(1개 상품만을 대상으로 구하는 방식의 신뢰도)와는 달리, P(A)와 P(B)를 모두 사용합니다. 또, 확신도는 완전히 독립적인 상품들을 비교할 때는 값이 1을 갖게 됩니다.
향상도와는 반대로, 확신도는 방향이 있는 측도입니다($A \rightarrow B$와 $B \rightarrow A$가 다름). 그 이유는 확신도가 결과절의 상품이 부재한 경우의 정보를 사용하기 때문입니다.
3. 연관 규칙 생성 알고리즘
3-1. Brute Force (무차별 탐색)
Brute Force란, 무차별 대입으로 모든 경우의 수를 무식하게 전부 시도해 보는 방법을 말합니다. 규칙을 생성하는 데에는, brute-force 방식을 적용해 모든 조합을 고려해서 계산하는 것이 혹시라도 모를 모든 좋은 조합을 발견해 내기에 좋겠죠. 하지만 앞서 언급했 듯이 상품의 가지수가 늘어남에 따라 연산량이 기하급수적으로 증가하게 됩니다. (상품이 n개일 때 탐색해야 할 모든 경우의 수는 $n*(n-1)$ )
모든 규칙을 리스트업하고 각각 confidence와 support를 계산하여, 최소한의 threshold를 넘지 못하는 규칙을 제거하는 방식으로 좋은 규칙을 찾아낼 수 있겠죠. 하지만 이는 연산적으로 불가능한 알고리즘입니다.
3-2. A priori
그래서 고안된 방법이 A priori 방법론입니다. 이는 오직 빈번하게 등장하는 아이템 셋에 대해서만 고려 하는 방법입니다.
만약 햇반의 지지도(전자의 방법으로, $P(햇반)$)가 0.2라고 했을 때, 이 상품이 포함된 다른 장바구니 {햇반,김치}의 지지도는 0.2를 넘을 수 없습니다. 이 둘이 동시에 등장할 확률은 햇반이 등장할 확률보다 기껏해야 같은 값이 최대일 것이기 때문이죠.
이러한 성질을 anti-monotone property라고 합니다. 한 상품 집합의 지지도는 그의 부분집합의 지지도를 넘지 못한다는, 지지도 수식의 특성을 말하는데요. 달리 말해 minimum support를 넘지 못하는 상품 집합의 상위 집합(superset)은 모두 minimum support를 넘지 못한다는 말입니다.
따라서 상품 2개가 들어있는 조합을 고려했을 때 일정 minimum support를 넘지 못했다면, 그 다음에 계산할 해당 상품 2개가 포함된 3개짜리 조합을 고려할 때 볼 필요도 없어지는 셈이죠. 이와 같은 규칙을 적용함에 따라 연산량을 크게 줄일 수 있습니다.
실제 이 알고리즘을 사용할 때에는, 지지도(support)와 향상도(lift) 중 어느 것을 중점적으로 둘지 맥락에 따라 고민해 보아야 합니다. support가 높으면 규칙을 적용할 가능성은 높지만, lift를 사용하면 효과는 확실하게 되는 셈이죠. 즉 support는 노출의 가능성, lift는 전환의 성공 확률을 각각 중점으로 뒀을 때 더 가중치를 둬야할 성능 지표가 됩니다.
4. 코드 예제
연관 규칙 추천의 코드 예제를 살펴보겠습니다.
먼저, 연관 규칙 분석에 사용되는 mlxtend 라이브러리를 설치합니다.
> pip install mlxtend
연관 규칙 추천에 사용할 데이터는, 온라인 리테일 데이터 셋 입니다.
라이브러리를 호출하고, 데이터를 로드합니다.
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
df = pd.read_excel('http://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx', engine="openpyxl")
df.head()
그리고 약간의 전처리를 해 줍니다.
df['Description'] = df['Description'].str.strip()
df.dropna(axis=0, subset=['InvoiceNo'], inplace=True)
df['InvoiceNo'] = df['InvoiceNo'].astype('str')
df = df[~df['InvoiceNo'].str.contains('C')]
이제 이 결제건으로 구분된 데이터를 one-hot encoding 해 줍니다. 여기서는 프랑스의 주문 내역만을 살펴볼 건데, 총 392건의 결제 내역이 포함되어 있습니다.
인코딩을 해주는 부분은, sum 연산으로 1 이상의 값이 채워져있는 것을 1로 바꾸어주기 위함입니다.
basket = (df[df['Country'] =="France"]
.groupby(['InvoiceNo', 'Description'])['Quantity']
.sum().unstack().reset_index().fillna(0)
.set_index('InvoiceNo'))
def encode_units(x):
if x <= 0:
return 0
if x >= 1:
return 1
basket_sets = basket.applymap(encode_units)
basket_sets.drop('POSTAGE', inplace=True, axis=1)
display(basket_sets)
드디어 모델을 학습할 차례입니다.
frequent_itemsets = apriori(basket_sets, min_support=0.07, use_colnames=True)
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1)
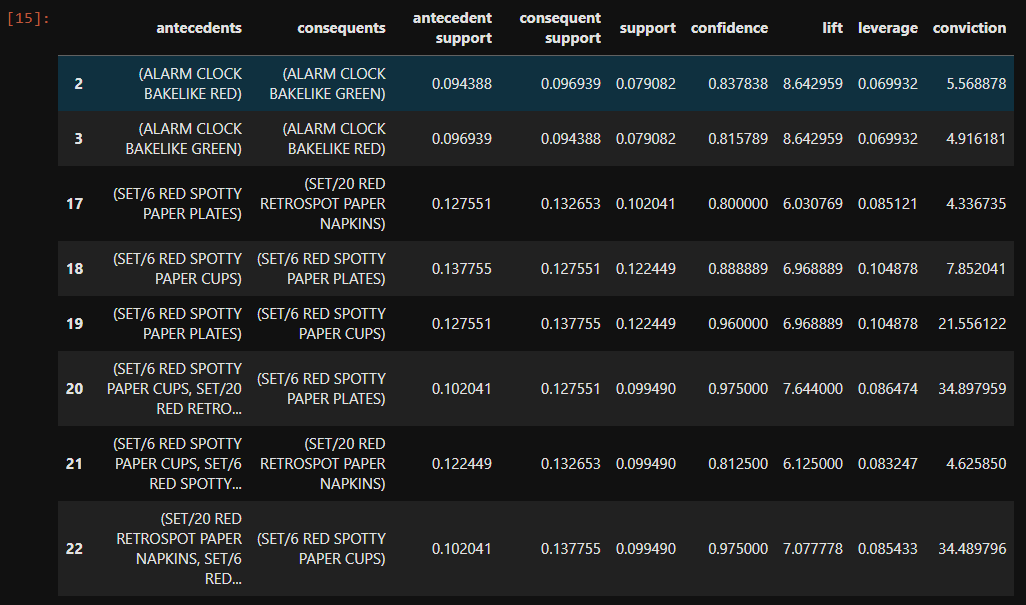
rules.head()
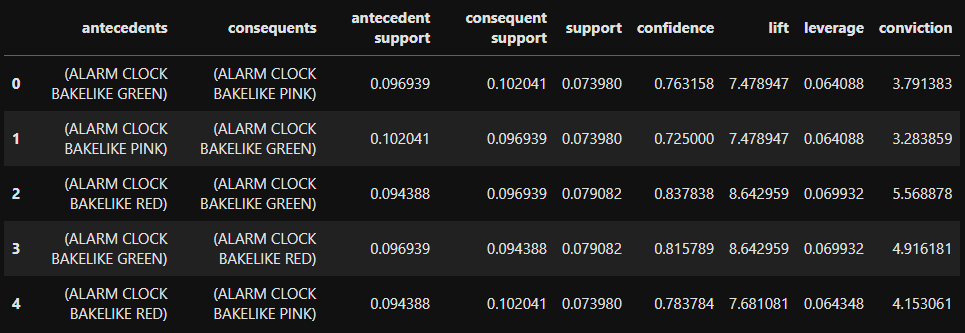
각각의 행은 규칙을 나타내고, 조건절(antecedents)과 결과절(consequents), 그리고 각각에 쓰인 상품의 지지도(antecedent support, consequent support)와 두 상품 공통의 지지도(support)를 순서대로 확인할 수 있습니다. 이어서, 신뢰도(confidence)와 향상도(lift), 레버리지(leverage)와 확신도(conviction)를 볼 수 있습니다.
향상도와 신뢰도를 기준으로 필터를 걸어, 유용한 규칙만을 살펴볼 수도 있습니다.
rules[ (rules['lift'] >= 6) &
(rules['confidence'] >= 0.8) ]
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요. 내용에 대한 지적, 혹은 질문을 환영합니다.
출처
https://www.youtube.com/watch?v=AUfYCH9KsoE (고려대 강필성 교수님의 연관규칙분석 강의) https://www.sciencedirect.com/science/article/pii/S2314728816300460#:~:text=Conviction%20measures%20the%20implication%20strength,not%20appear%20in%20a%20transaction. (확신도 관련) https://askinglot.com/what-is-leverage-in-association-rules (레버리지 관련) https://pbpython.com/market-basket-analysis.html#:~:text=Association%20rules%20are%20normally%20written,%7BBeer%7D%20is%20the%20consequent. (파이썬 코드)
Leave a comment