
[RecSys] 대용량 광고 추천 at Criteo
Criteo에서 매일 수십억건의 온라인 광고 추천을 수행하는 방식에 대해서 살펴봅니다.
원제: Recommendations at Scale at Criteo - Diane Gasselin
본 포스트는 Criteo의 Diane Gasselin가 발표한 영상을 토대로 작성한 노트입니다. 영상은 여기에서 보실 수 있습니다.
Contents
1. Criteo의 ecosystem과 challenges
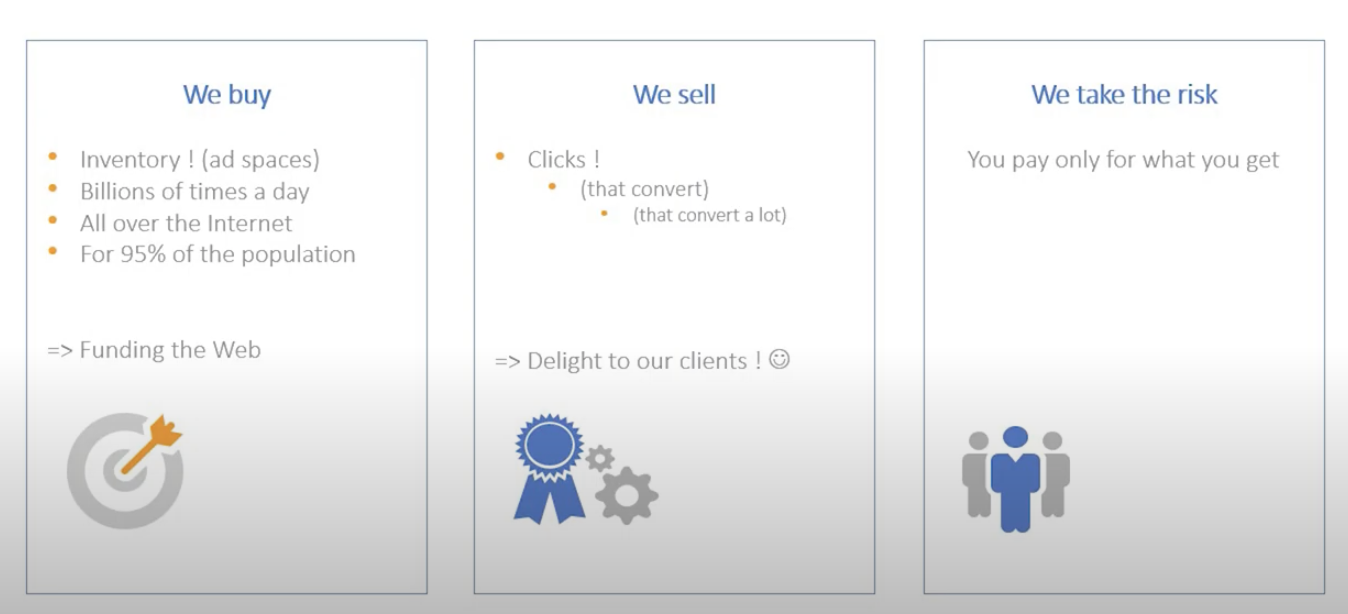
1-1. Criteo가 하는 일
- 인벤토리 구입(광고 공간)
- 전 세계에 걸쳐 하루에 수십억 건 처리
- 전체 인구의 약 95% 대상
- 전환되는 클릭을 판매함(clicks that convert)
- 위험은 크리테오가 부담
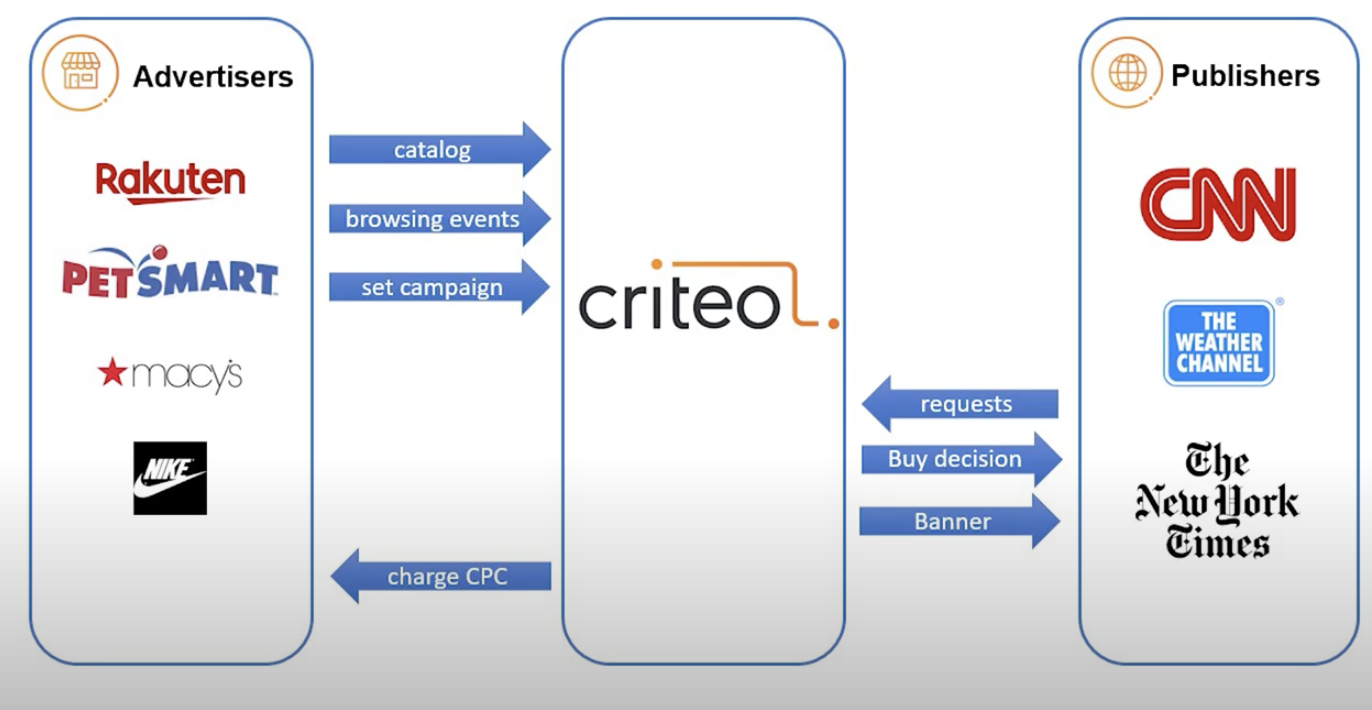
1-2. 광고 메커니즘
- 광고주(제조업, 이커머스 업체 등)은 크리테오에 카탈로그, 브라우징 이벤트(자사 플랫폼 내 고객의 기록), 캠페인 셋팅(리타겟팅,획득(acquisition) 등)을 전달함
- 퍼블리셔는 크리테오에 request를 보내는데, 이는 자신들이 가진 인벤토리의 경매에 참여할 것인지를 결정하도록 함. 만약 크리테오가 구매를 결정한다면, 그들에게 배너를 보냄
- 여기서 발생하는 전환을 토대로 CPC(cost per click)를 계산해 고객에게 청구함
1-3. 크리테오의 데이터
- 카탈로그 데이터: 16,000 고객, 고객당 평균 100만의 상품군
- 유저 행동 데이터: 매일 600억 건의 데이터
- 광고 노출 데이터: 80억건 이상의 요청 데이터
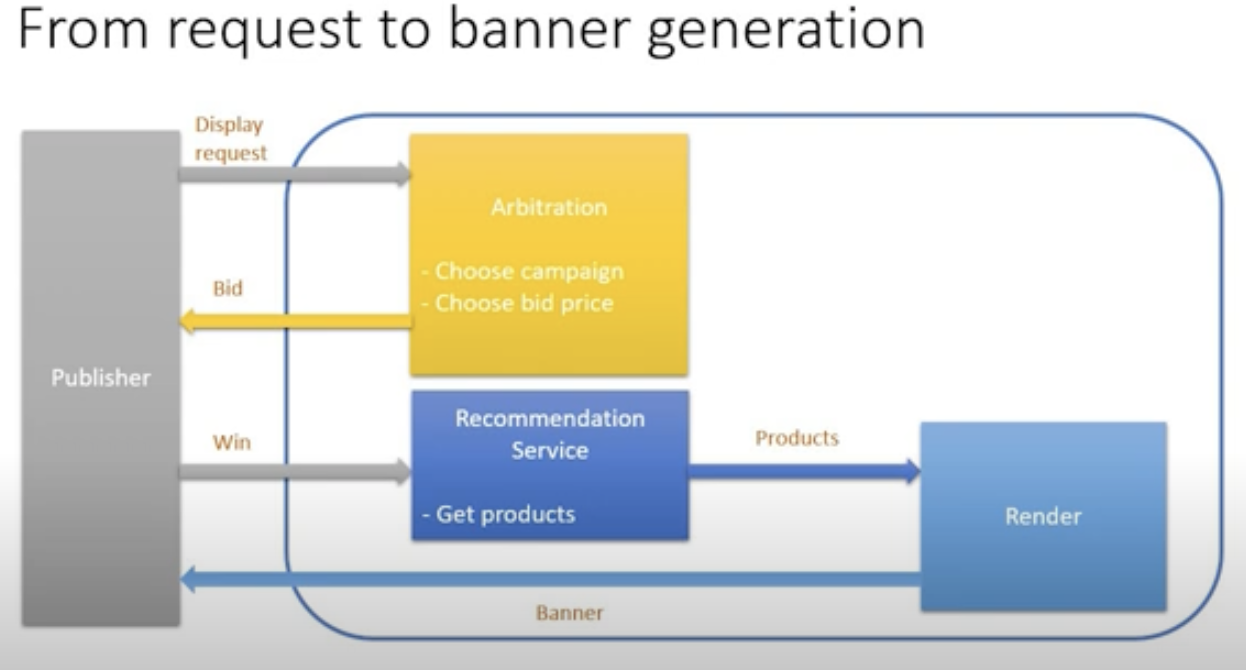
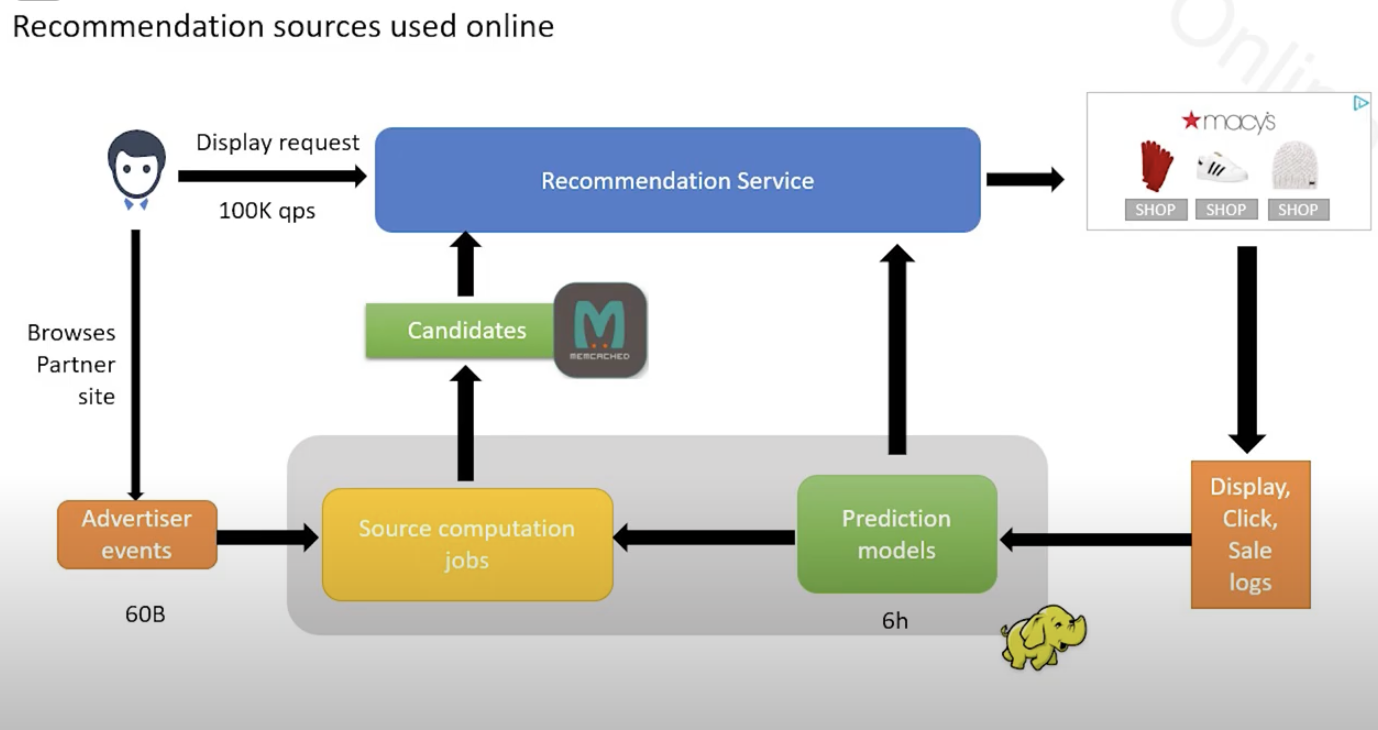
1-4. request에서 배너 생성까지
- 퍼블리셔가 입찰 요청을 보냄
- arbitration: 가격과 캠페인 선택
- 입찰시 추천 서비스에서 상품을 얻어옴
- 선택한 상품을 렌더러(renderer)에 보냄
- 렌더러는 퍼블리셔에 보여줄 상품을 내보냄
2. 유저에게 추천 제공하기
2-1. 유저에게 상품 추천하기
- 유저, 파트너, 캠페인 정보를 입력으로 받아 상품을 출력함
- 상품의 개수는 노출 대상인 인벤토리의 슬롯 개수에 따라 달라짐
- 초당 10만건 쿼리를 받고, 15ms 이내로 요청을 처리해야하며, 이를 처리하기 위해 전세계의 데이터센터에 1,000대의 서버가 있음
- 30억개의 유니크한 uid가 존재, 20개의 디바이스에 걸친 아이디
- 16,000개의 활성 파트너(고객사)
2-2. 추천 모델 입력변수
- 브라우징 이벤트: 각 고객사에 대해 유저의 최근 10개 조회 상품, 5개의 최근 장바구니, 5개의 최근 구매, 최근 리스팅..
- 장기 피처: 전역적 피처, 고객사별 피처, 선호 색상, 예산 종류, 오프라인예측 결과 등. 오프라인 추천에서 사용되고, 온라인으로 계산되기에는 너무 많은 연산이 필요한 피처들
2-3. 추천 상의 문제
- 가장 큰 파트너는 상품만 2억가지를 가지고 있음(평균 100만). 전체 아이템-아이템 매트릭스를 온라인으로 계산할수는 없음
- 해결책: 오프라인으로 상품 소스(원천)를 만듦.
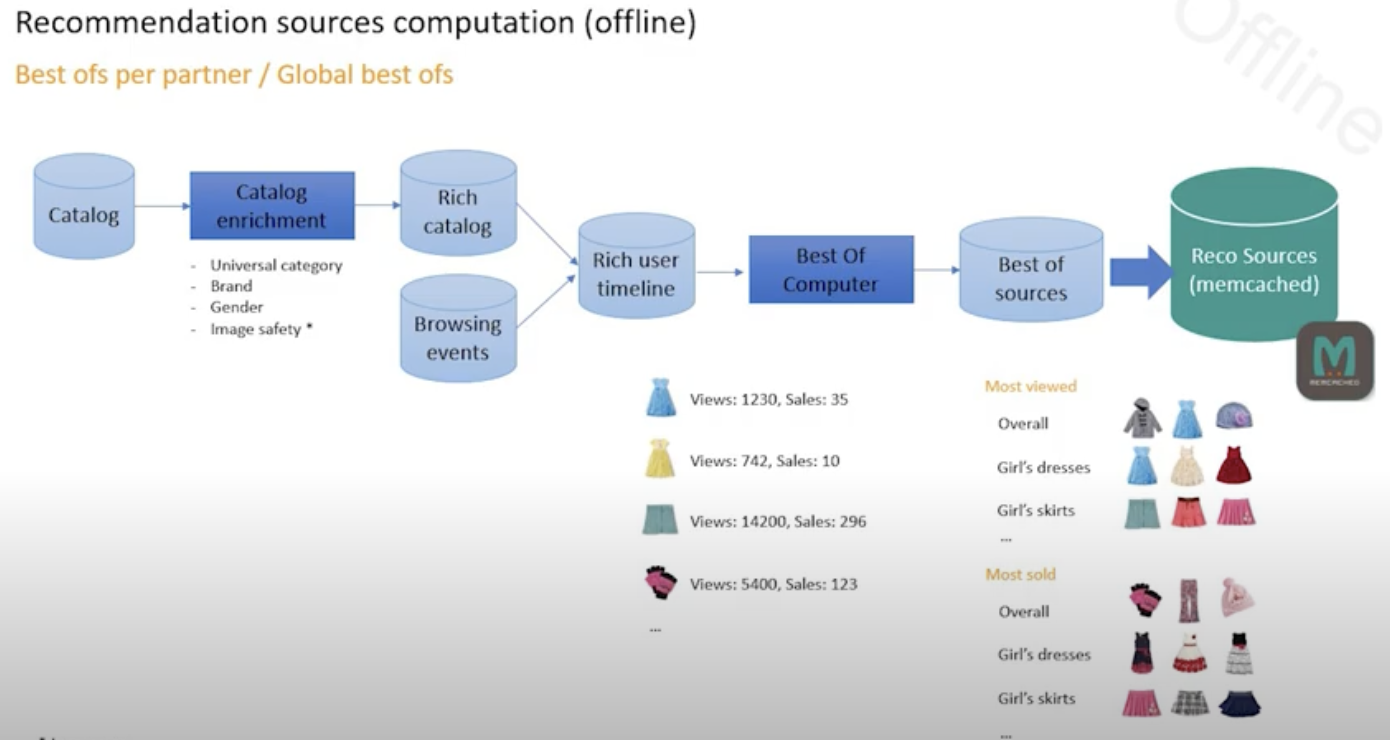
3. 오프라인 추천 소스 만들기
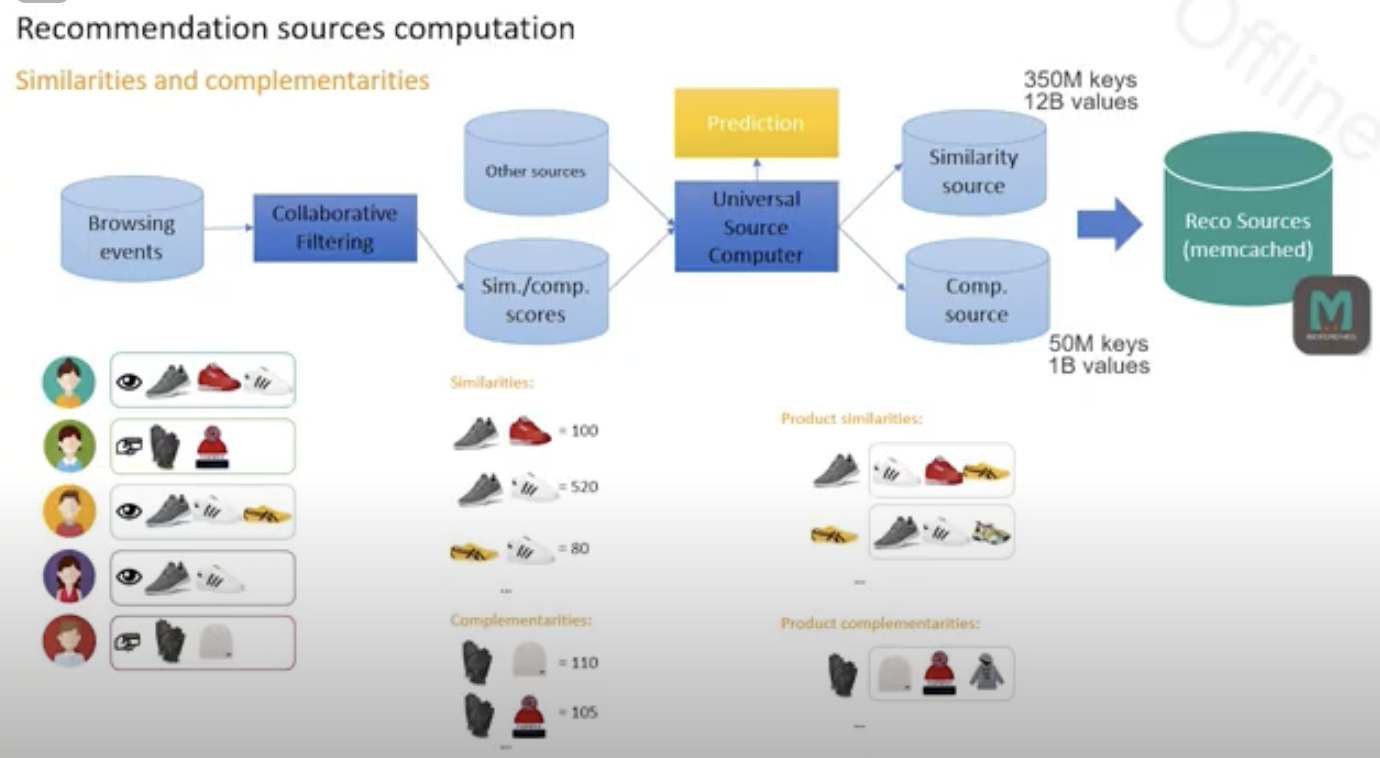
3-1. 추천 상품 소스(원천) 만들기
- 브라우징 이벤트-> CF 모델 -> 유사/대체재 스코어링 -> universal source computer -> prediction
- 먼저 탐색 이벤트가 발생하면 CF 모델을 거쳐 유사도와 대체재 점수가 계산되어 나옴. 여기에 부가적인 정보를 덧붙임
- 이 정보를 기반으로 linear regression 같은 예측 모델을 학습함. 확장성이 좋기 때문임.
- 라벨은 최근 90일간 같이 조회되거나, 구매되거나, 가장 자주 조회되거나 하는지 여부가 됨. (병렬적으로 이벤트마다 구성)
- 모델을 클릭/판매 데이터 등 이벤트마다 구성, 학습
- 유사도/대체재 점수를 메모리 캐시에 올려 온라인으로 처리, 리트리벌이 매우 빠르고 효율적임
- 그 외에도, 글로벌 단위의 토큰이나 카테고리 별로 베스트 상품을 계산함.
- 카탈로그 정보(유니버설 카테고리, 브랜드, 성별, 이미지 안전도(?) 등)를 사용해 브라우징 이벤트와 결합하여 풍부한 유저 타임라인을 만든 뒤, “Best of”를 계산하여 카테고리 등 기준별 베스트 상품을 구한 뒤 메모리 캐시에 올림.
4. 온라인 추천 워크플로우
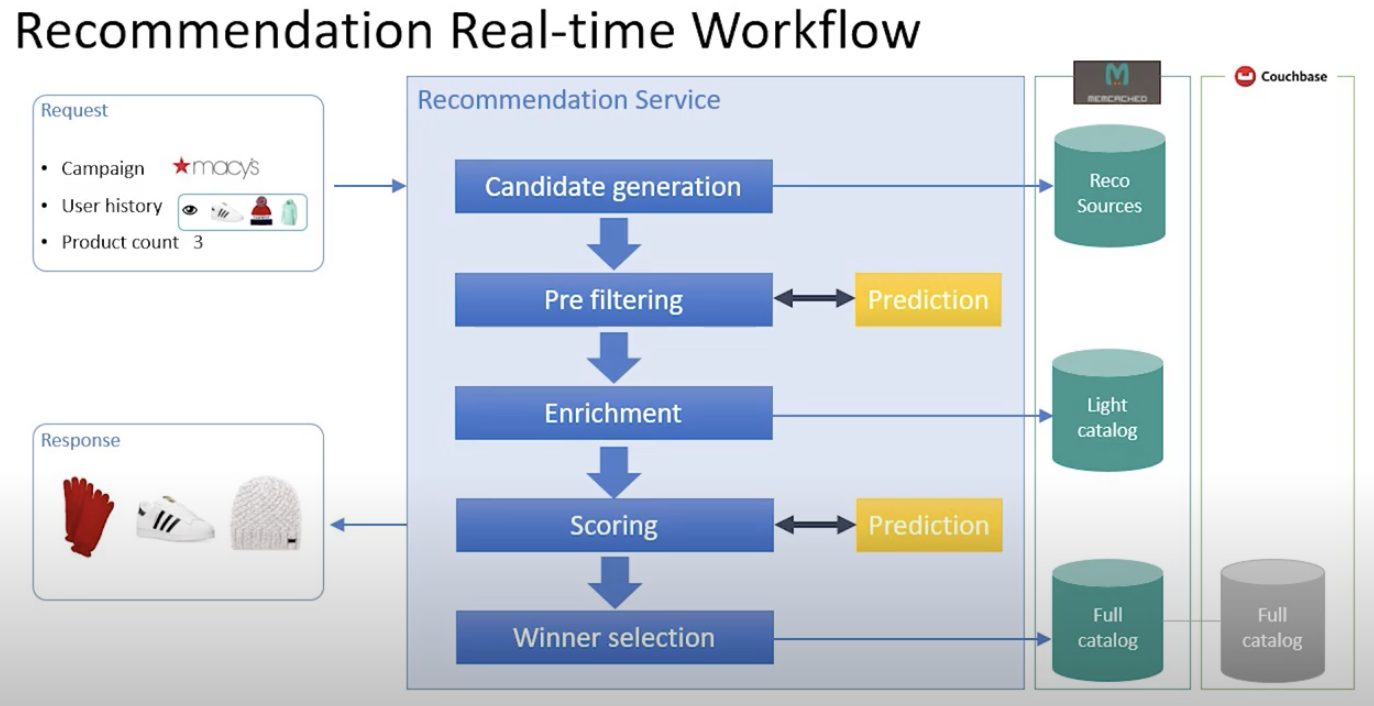
4-1. 실시간 추천 워크플로우
1) 캠페인 요청: 캠페인 주체, 유저 기록, 노출 상품 등을 입력으로 받음 2) 후보군 생성: 15-25개의 유사도/대체재 후보군을 뽑아냄. 온라인으로 평가할 수 있도록 차원을 줄이는 작업이 필요함. 결과물은 reco sources에 저장됨 3) 사전 필터링: 단순 피처를 사용해 나이브하게 결과 출력, 여기서 예측을 수행하기도 함 4) 피처 보강: 더 많은 정보를 카탈로그에서 가져와 피처를 보강함. 이 정보들을 reco source에 저장하면 중복 데이터가 발생하므로 추가적으로 부르는 절차를 진행. 유저 정보, 퍼블리셔 정보, 시간과 같은 맥락 정보 등이 추가됨. 이를 통해 더 나은 스코어링이 가능해짐. 5) 스코어링: 앞에서 확보한 데이터를 토대로 스코어링을 수행하고, 랭킹을 매김. 6) 우수 상품 선택: 최종적으로 재고가 있는지 등 가용성을 체크한 뒤 배너로 쏘아 줌.
5. 평가
5-1. 온라인 AB testing
- 전체 그룹을 절반으로 나누어서 AB testing을 진행하는 방법은 너무 부담이 큼
- 만약 결과가 좋지 않을 경우, 수많은 돈을 빠르게 잃게 됨
- 기간이 너무 긺(충분한 신뢰구간을 얻기까지 2주까지의 시간이 소요됨)
- 코드가 프로덕션 수준으로 준비가 되어야함. 버그도 없고, 성능도 좋아야 함. 하루 종일 돌아가야하기 때문
- 인프라에 큰 부담을 줄 수도 있음.
- 뿐만아니라 장기적인 효과를 고려하지도 않음
5-2. 예측을 위한 테스트 프레임워크
- 프로덕션 로그를 재실행(replay)하는 오프라인 프레임워크
- 연간 30,000번 실행, 100배 빠른 리플레이(?)
- 로그 안에 있는, display 되었던 아이템에 대해서만 데이터가 존재하는 한계가 있음. 온라인으로 데이터를 셔플링해 다양성을 확보하는 식으로 exploration할 수 있을 것. exploration을 하는 것은 비용이 많이 듦.
- 따라서 우리가 완전히 잘못한 것은 아니라는 것을 확인할 수 밖에 없음.
- 더 나은 오프라인 메트릭을 얻을 수 있는데, 그 중 하나는 파트너의 장기적인 의도를 예측하는 것임. 특정 파트너의 같은 클릭수 대비 구매 수가 줄어들 것이라고 예상된다면 이를 기준으로 CPC를 조절하는 식으로 대응.
6. 머신러닝 모델 학습
6-1. ML 실험
- 로지스틱의 효율성을 능가할 모델이 없기에 이를 대체하는 것은 쉽지 않음
- 그럼에도 몇가지 실험을 진행했는데, 그 중 하나는 Prod2Vec임. 이는 Word2Vec과 비슷한 접근을 취하는데, Word2Vec에서는 단어와 문장에 상응하는 것이 Prod2Vec에서는 상품과 세션임.
- 즉 쇼핑 세션이 주어졌을 때 다음에 보게될 아이템이 무엇인지를 맞추는 작업을 수행.
- 상품을 추천함에 있어서 기존에는 추천 상품이 독립적으로 취급되었는데, 이는 부적절한 것으로 보임. 온라인 광고의 경우에는 각각의 연속된 상품이 독립적이지는 않음을 이해할 수 있음.
- 여기서 1개의 은닉층을 가진 FCL 뉴럴넷을 사용하여 학습, KNN으로 유사도를 구함.
- 이는 확장성의 문제 때문에 주요 파트너에게만 제공되고 있음.
6-2. ML 실험 2
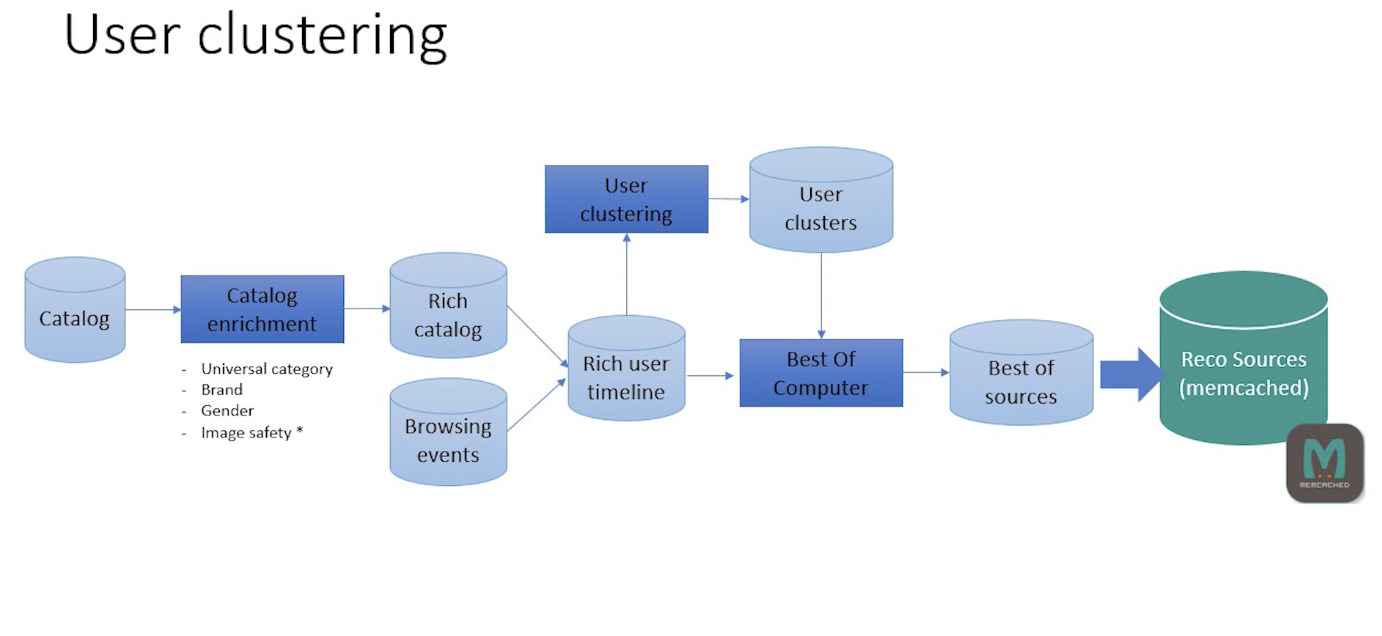
- 또다른 실험으로는 유저 클러스터링임. 앞서서 살펴본 reco source DB 파이프라인에서, rich user timeline(유저 브라우징 데이터) 데이터를 기반으로 유저 클러스터링을 수행, 생성된 클러스터별로 best of를 계산
- 유저는 cross-partner metadata를 사용해 임베딩됨.(universal category, brand, token, gender..)
- K-means로 클러스터링 진행.
- IDFTF(TF-IDF 방식을 의미하는 듯)가 적합한지는 테스트 중. 잘 작동하지 않는 것으로 보임.
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요. 내용에 대한 지적, 혹은 질문을 환영합니다.
출처
https://www.youtube.com/watch?v=7Bp2kgkry1s
Leave a comment