메타데이터 관리도구 Apache Amundsen 소개
시스템 내 방대한 양의 데이터를 쉽게 찾고 관리하기 위한 Metadata Management Tool인 Apache Amundsen에 대해 알아봅니다.
1. Amundsen은 비효율적인 Data Discovery 작업을 편리하게 도와주는 Metadata 검색 관리 툴
2. Metadata를 활용해 Data Discovery 과정을 효율화함으로써, 데이터 과학자의 생산성을 늘릴 수 있고 구성원들 사이의 정보격차를 줄일 수 있음
3. 다른 Apache Project와 쉽게 결합해 활용할 수 있음
Contents
이번 시간에는 MLOps 두번째 포스트로, Apache Amundsen에 대해 알아보겠습니다. 모든 툴이 그렇듯이, Amundsen 역시 무언가 불편한 점을 해결하기 위한 수단으로 고안되었습니다. 왜 이 툴이 필요했는지를 이해하면 이 툴을 어떻게 사용하면 좋을지에 대해 알아보기 좋을 것 같습니다. 따라서 왜 Amundsen(이하 아문센)이 필요한지 배경을 알아보고, 아문센이 무엇인지 살펴본 뒤, 비슷한 일을 해주는 다른 툴은 무엇이 있는지 알아보겠습니다. 마지막으로 직접 아문센 웹앱을 도커로 띄워 로컬 환경에서 구축하는 데모를 함께 진행해 보려고 합니다. 시작할게요!
귀찮고 번거로운 Data Discovery
MLflow에 대해 설명하기 전에, ML 모델을 개발/배포함에 있어 ML 엔지니어 혹은 데이터 과학자가 관리하는, 모델의 lifecycle에 대해서 살펴봅시다.
ML 모델의 lifecycle
머신러닝 모델의 개발 단계는 다음 그림처럼 크게 4가지의 파트로 구성되어 있습니다.
- 원시 데이터(raw data)
- 데이터 준비
- 모델 학습
- 모델 배포(deployment)
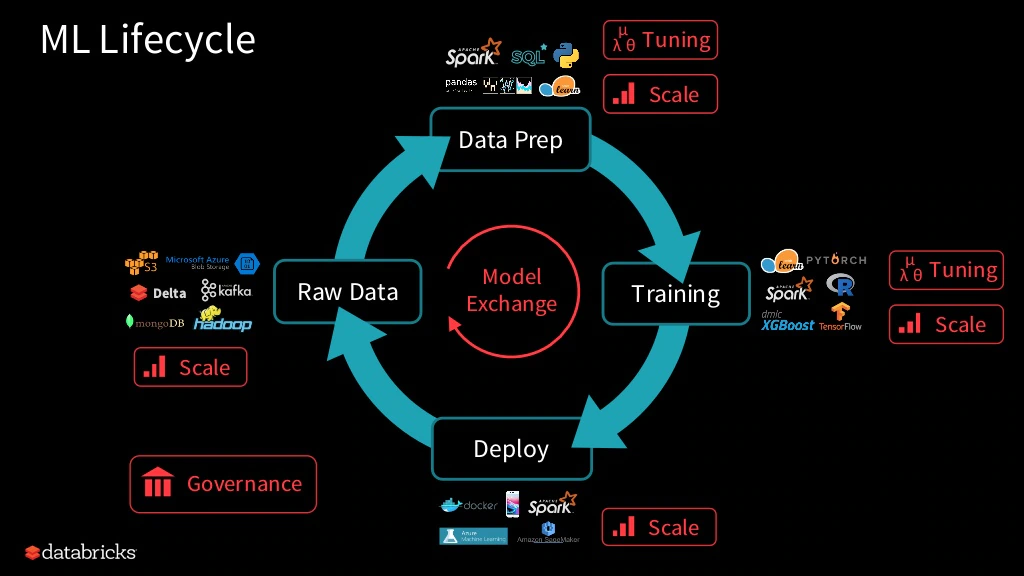
이 네 단계는 순차적으로, 그리고 반복적으로 이루어 집니다. 배포가 된 이후에도 끊임없이 데이터는 정제되고, 재학습되고, 재배포되는 식으로 말입니다.
그런데 이 과정의 하나 하나가 점점 커짐에 따라, 파이프라인의 각 단계가 실패할 가능성이 커질 것입니다. 이 전체 라이프 사이클을 관리해주는 툴이 있다면 매우 편리하겠죠.
Why MLflow?
왜 MLflow를 사용해야할까요? ML application에서 경험하는 여러가지 이슈에 대해 생각해 볼 수 있습니다.
1) 하이퍼 파라미터 튜닝 효율화
하이퍼 파라미터 튜닝(HPO, Hyper Parameter Tuning) 과정은 모델 성능에 중요한 역할을 합니다. 이 반복적이고 실험적인 과정을 효율적으로 수행할 수 있다면 더 좋을 것 같습니다.
2) 확장 가능성
모델의 서빙 단계에서는, 확장 가능성이 중요한 문제가 됩니다. ML 실무자가 늘어감에 따라 이를 관리하는 일은 쉽지 않을 것입니다.
3) 모델 교환과 가버넌스
마지막으로 모델 교환과 가버넌스 역시 매우 중요합니다. 모델을 교체했을 때, 기존에 사용했던 하이퍼파라미터, 소스코드, 개발 담당자, 성능, 교체 시점 등을 추적하는 작업은 꼭 필요합니다. 특히 모델 활용이 신중하게 이루어져야하는, 가령 금융과 같은 분야에서 이러한 기록은 매우 중요하겠죠.
다른 ML platform은 없나요?
ML 모델의 파이프라인 솔루션을 제공하는 플랫폼에는, Facebook의 FBLearner, Uber의 Michelangelo, Google의 Google TFX 등이 있습니다. 그러나 각각은 일부 알고리즘 혹은 프레임워크, 혹은 한 기업의 인프라에 국한되어 있다는 한계가 있습니다. 완벽한 오픈소스가 아니라는 말이죠.
MLflow란?
Mlflow의 공식 문서에서, MLflow는 end-to-end machine learning lifecycle을 관리하는 오픈소스 플랫폼이라고 소개하고 있습니다.
MLflow는 라이브러리나 언어에 구애받지 않고, 클라우드를 비롯한 어떤 환경에서든 동일하게 작동합니다. 확장가능성 역시 훌륭한데, 사용 조직의 규모가 1명이든 1,000명 이상이든 유용하게 사용할 수 있도록 고안되었습니다.
Mlflow는 크게 4가지의 컴포넌트로 나눌 수 있습니다.
1) MLflow Tracking: 실험 기록을 추적하며, 파라미터와 그 결과를 비교합니다.
2) MLflow Projects: ML code를 재사용, 재구현 가능한 형태로 패키징하여 다른 데이터 과학자들과 공유하거나 프로덕션으로 변환합니다.
3) MLflow Models: 다양한 ML 라이브러리로 만들어진 모델을 관리하고 다양한 모델 서빙과 추론 플랫폼으로 배포합니다.
4) MLflow Registry: 중앙 모델 스토어를 제공함으로써, 한 MLflow 모델의 전체 라이프 사이클을 협동적으로 관리합니다. 이러한 관리 작업에는 모델 버전 관리(versioning), 모델 스테이지 관리(stage transitions), 주석 처리등을 포함합니다.
이제, 각각의 컴포넌트가 어떤 역할을 하는지에 대해 살펴보겠습니다.
MLflow Components
1. MLflow Tracking
MLflow Tracking은 조직 내 ML 모델 학습 세션에 대한 메타데이터를 관리하는 중앙화된 레포지터리를 제공하는 기능입니다. 달리 말하면, 우리 팀에서 ML 모델을 여러개 학습시키고 관리하는데, 여기서 발생하는 메타데이터(log, 하이퍼파라미터 정보, loss 변화, 모델 성능 등)를 관리해주는 저장소 역할을 해준다는 의미입니다.
MLflow Tracking에는 두 가지 backend store가 있는데, 다음과 같은 특징을 갖습니다.
1) Entity(metadata) store 학습과 관련된 가벼운 메타데이터를 수집하고 통합합니다. 메트릭, 파라미터, 소스 및 버전 정보를 포함합니다. Entity store는 아래와 같은 store system을 사용할 수 있습니다.
- file store(로컬 파일 시스템): 유닉스 및 윈도우 파일 시스템과 모두 호환됨
- SQL store: SQLAlchemy를 사용하여 대부분의 DB와 연동할 수 있습니다.
- REST store: 자체적인 인프라를 구축하고 싶은 조직에게, 메타데이터 스토어는 restful한 추상화를 제공합니다. 이로써 기존의 시스템과 효과적으로 결합할 수 있습니다.
2) Artifact Store 메타데이터와 달리 상대적으로 무거운 데이터를 저장합니다. 이는 학습데이터, 모델파일 등을 포함합니다. 다양한 기존 인프라에 결합할 수 있습니다.
- Amazon S3 backend store
- Azure Blob Storage
- Google Cloud Storage
- DBFS(DataBricks FileSystem)
- FTP, SFTP
2. MLflow Projects
MLflow Projects는 모델의 재생산성, 재사용성을 확보하기 위한 기능을 제공합니다. 기껏 개발한 모델이 나의 로컬 PC에서만 작동해서는 안되겠지요.

MLflow는 BART의 꼴이 나지 않도록, 모델을 재현할 수 있는 환경을 손쉽게 확보할 수 있도록 아래의 다양한 기능을 제공합니다.
1) 재생산가능한 ML 실행을 위한 패키징 포맷
- 어떤 코드 폴더든, 깃헙 repository든 지원합니다.
- Project config를 포함한 optional ML project file을 관리할 수 있습니다.
2) 재생산성을 위해 dependency 정의
- Conda/R/docker dependency에 대한 정보를 ML 프로젝트에 명시적으로 기록할 수 있습니다.
- 거의 모든 환경에서 재생산 가능할 수 있도록 지원합니다.
3) 프로젝트 구동을 위한 실행 API
- CLI/Python/R/Java
- 로컬 및 원격 실행을 지원합니다.
3. MLflow Models
모델을 학습하고 재현하는 과정 이후에는, 모델이 정해진 양식에 따른 입력을 받았을 때 추론 결과를 뱉어낼 수 있도록 배포할 수 있어야겠지요. 이를 위해 MLflow는 다양한 환경에서 (Docker, Spark, Kubenetes…) 다양한 툴(Tensorflow, Scikiy-Learn..)로 모델 배포를 할 수 있도록 중간 스탠다드 역할을 수행해 줍니다.
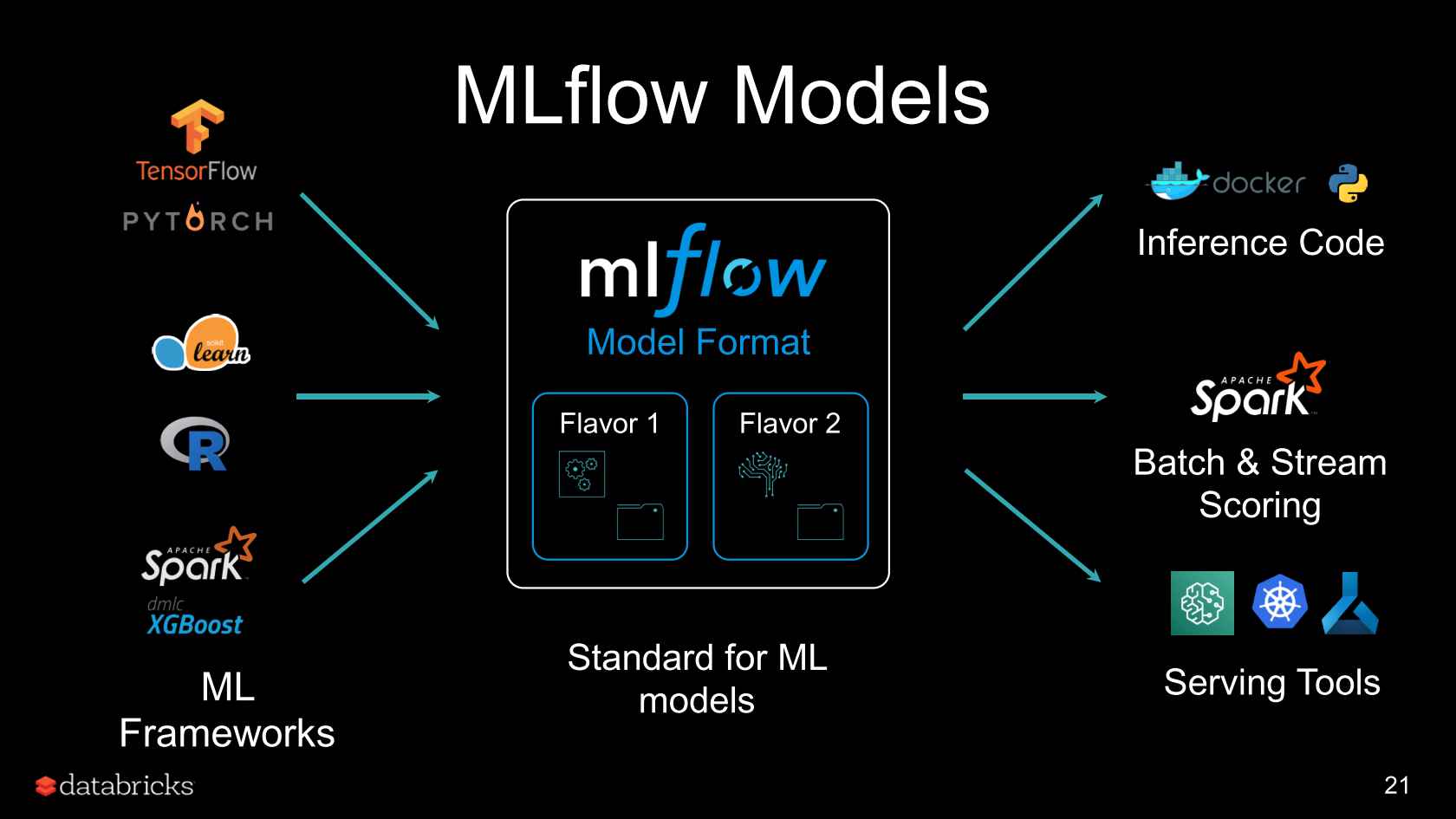
- ML 모델을 위한 패키징 포맷 제공: ML 모델 파일이 있는 어떤 디렉터리든 사용 가능합니다.
- 재생산성을 위해 dependency 정의: ML 모델의 config에 콘다 환경등의 dependency에 대한 정보를 제공할 수 있습니다.
- 모델 생성 유틸리티: 어떤 프레임워크에서 나온 모델이든 MLflow 포맷으로 저장해 줍니다.
- 배포(Deployment) API: CLI/python/R/Java 등의 배포 API를 제공합니다.
4. MLflow Registry
ML 모델을 개발하다보면, 하이퍼 파라미터든, 모델의 구조든 다양한 변화를 가한 버전이 생겨나기 마련입니다. 이러한 다양한 버전, 그리고 스테이지를 충돌 없이 쉽게 관리할 수 있는 기능을 제공합니다.
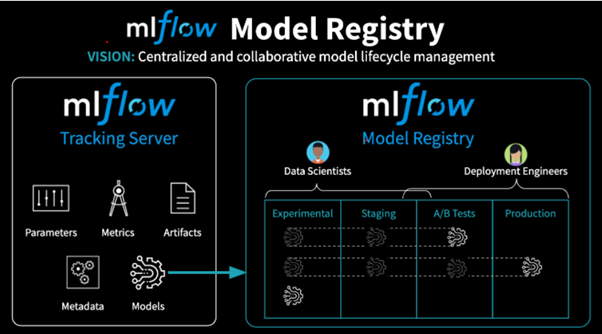
-
중앙화된 레포지터리: 이 레포지터리는 모든 등록된 모델들과 그에 상응하는 메타데이터를 포함하고 있습니다. 등록된 모델들의 모든 기존 버전들은 여기에 저장되고 여기에서 접근이 가능합니다.
-
모델 Staging : 등록된 모델들은 미리 정의된 혹은 커스텀 스테이지에 할당되어 ML lifecycle 내에서 어떤 phase에 있는지를 나타낼 수 있습니다. 이는 개발자들이 프로덕션의 모델에 영향을 미치지 않은채 한 모델의 새로운 버전을 개발 스테이지로 배포할 수 있게 해줍니다.
-
변화 관리와 모니터링: 사용자들은 모델 레지스트리에 변경사항이 발생했을 때 핵심 정보를 로그로 남길 수 있도록 이벤트를 설계할 수 있습니다. 사용자들은 배포 과정에 다양한 수준의 통제를 실행할 수 있는데, 가령 레지스트리에 가해진 변화를 제출하기 전에 요청을 보내고, 검토한 뒤, 승인되도록 셋팅함으로써 배포 과정을 통제할 수 있습니다.
예제 (Factorization Machine)
0. MLflow 설치
설치는 매우 간단합니다. pip이 설치된 환경에서 아래의 커맨드를 실행합니다.
pip install mlflow
1. MLflow Tracking
닫으며
지금까지 간단한 확률과 분포에 대해 알아보았습니다.
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요. 내용에 대한 지적, 혹은 질문을 환영합니다.