
[Recsys] 그래프 & 자연어처리 기법으로 추천 시스템 개발하기 - pytorch
NLP와 Graph에서 사용되는 방법론을 적용해 높은 성능의 baseline 추천 시스템을 만들어 봅니다.
해당 포스트는 “Beating the baseline recommender using Graph and NLP techniques in PyTorch” 포스트를 저자의 동의를 얻고 번역한 글입니다!
들어가며
안녕하세요, 배우는 기계 러닝머신입니다! ![]()
오늘은 NLP와 그래프에서 사용되는 word2vec, random walk 등의 방법론을 활용해 추천시스템을 구현하고, 흥미로운 실험을 진행한 포스트를 소개하고자 합니다. 실험에 사용한 코드는 여기에서 확인하실 수 있습니다.
포스트의 핵심 아이디어는 다음과 같습니다.
1. w2v으로 상품 임베딩을 만드는 방법은 추천시스템에서 매우 잘 먹힌다
2. 주변 정보(side info)를 활용한 방법은 생각보다 성능이 잘 나오지 않았는데, 이는 meta data의 sparsity 때문으로 추측된다
3. 시퀀스 형태로 학습 데이터를 만드는 방법이 아주 잘 작동한다. 여기서는 Graph에서 사용되는 random walk를 사용해서 만들었다
Contents
- NLP and Graph
- Creating a Graph
- Generating sequences
- 구현 3: Node2Vec
- 구현 4: gensim.word2vec
- 구현 5: PyTorch word2vec
- 구현 6: PyTorch word2vec with side info
- 구현 7: Sequences + Matrix Factorization
- 결론
자연어처리와 그래프 NLP and Graph
자연어처리 분야에서 임베딩 방법론으로 널리 알려진 word2vec (이하 w2v)은 비지도적 방식으로 의미론적이고 통사론적인 단어의 vector representation을 학습할 수 있음을 잘 보여 주었습니다.
간단히 말해, w2v은 시퀀스 내의 단어(혹은 객체)를 라벨없이 수치적 표현으로 변환할 수 있다는 것을 보여 주었습니다. 머신러닝에서 가장 큰 bottleneck이었던 라벨 데이터가 필요하지 않다는 점에서 아주 커다란 발견이었지요.
한편, DeepWalk는 소셜 네트워크 그래프의 representation을 학습하는 알고리즘으로 소개되었습니다. random walk sequence를 생성함으로써, 그래프 내의 노드(가령 프로필, 혹은 컨텐츠 등)의 vector representation을 학습할 수 있음을 논문에서 보였습니다.
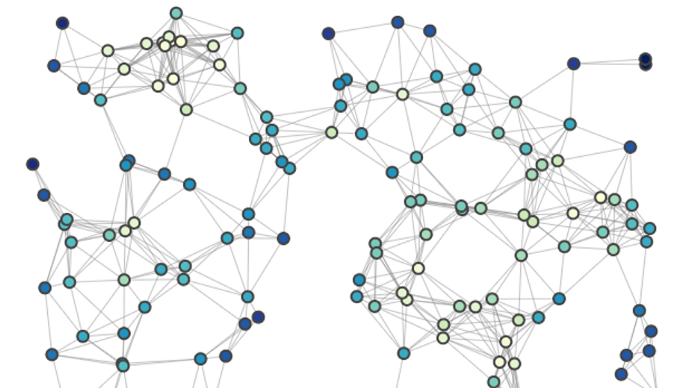
알았어요. 그런데 이것들이 추천에서 왜 중요하죠?
간단히 살펴보면, 요점은 다음과 같습니다.
- 상품 pair와 연관관계를 사용해 그래프 생성
- 그래프 내에서 sequence를 생성 (random walk 사용)
- sequence로부터 상품 임베딩을 학습 (word2vec 사용)
- 임베딩 유사도를 사용해 상품 추천 (e.g. 코사인 유사도, 내적 등)
준비 되셨나요? 시작해 보겠습니다.
그래프 만들기 Creating a graph
데이터 셋에 상품 pair가 있고, 각각 연관 점수(associated score)가 있습니다. 이 연관 점수를 (그래프의) 엣지 가중치로 간주할 수 있겠지요. 이 가중치를 사용해, weighted graph를 생성할 수 있습니다. (즉, 각 엣지가 수치적인 가중치를 지니고 있으며, 동일한 가중치를 공유하는 형태의 그래프) 이 작업은 networkx를 사용 쉽게 구현될 수 있습니다.
자! 이제 상품 네트워크 그래프가 만들어 졌네요.
시퀀스 만들기 Generating sequences
앞서 만든 상품 그래프를 통해, random walk로 시퀀스를 만들 수 있습니다.
직접적인 접근법 중 하나는 networkx 그래프를 순회하는 것입니다. 예를 들어, 각 시작점에서의 10개의 길이 10짜리 시퀀스를 만들고자 한다면, 시작점(vertex)마다 그래프를 100번 순회할 필요가 있겠지요.
electronics graph 데이터는 42만개의 노드를, books graph는 2백만개의 노드를 가지고 있습니다. 이를 100으로 곱하는 것은 매우 느릴테고, 많은 메모리를 소모하겠지요(진짜루요).
다행히도, networkx API를 사용하면 그래프를 순회할 필요 없습니다.
전이 행렬 사용하기 Using the transition matrix
그래프는 꼭지점(vertex)과 엣지(edge)로 이루어져 있습니다. 엣지는 각 노드간의 관계의 강도를 나타내지요.
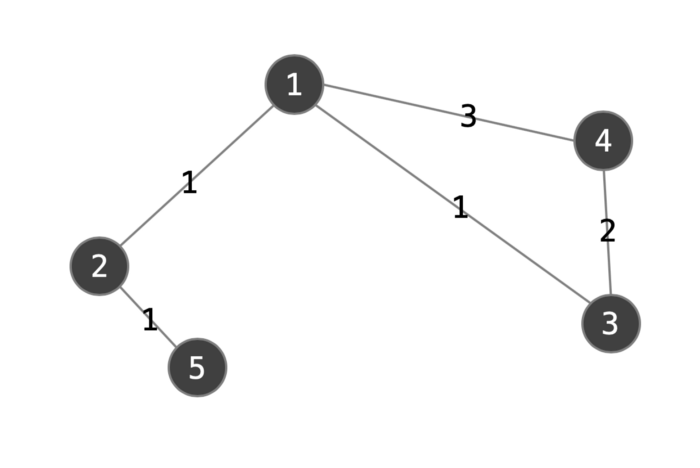
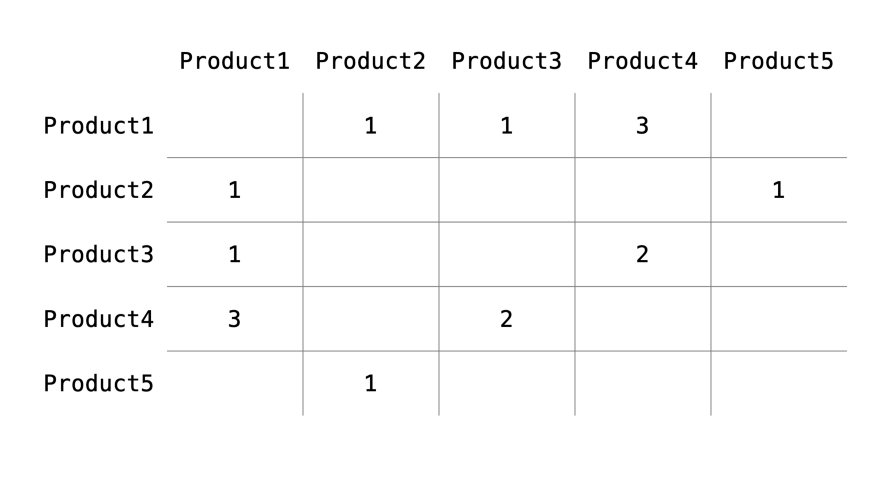
이는 인접행렬(adjacency matrix)으로 분해될 수 있습니다. 그래프가 V개의 노드를 가질 경우, 인접행렬은 V*V 차원이 됩니다. 일반적인 인접행렬은 0 혹은 1로 이루어져 있습니다. 엣지가 있으면 1, 없으면 0이 들어가겠죠. 그래프 엣지에 weight가 있으므로, 인접행렬의 값이 엣지의 가중치가 됩니다.
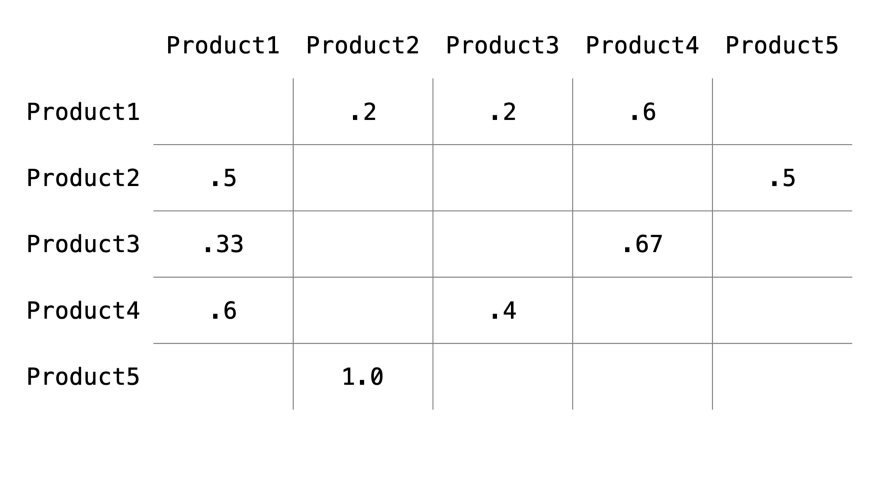
이 인접행렬을 row의 합이 1이 되도록 표준화하여 전이행렬(transition matrix)로 변환해야 합니다. 간단히 말해, 각 꼭지점이 다른 꼭지점으로 전이하는 확률을 나타내게 됩니다. (그렇기 때문에 합이 1인 것이죠)
제가 첫번째 시도한 구현 방법은 numpy 어레이를 사용하는 것이었습니다. 그러나 메모리 문제로 잘 작동하지 않았지요.
어떻게 메모리 효율성을 높일까요?
데이터셋이 99.99% sparsity를 가진다는 것을 떠올려봅시다. 42만 개의 electronics 데이터셋의 노드에는, 오직 4백 만개의 엣지만 존재합니다. 이는 42만의 제곱에서 4백만을 뺀 갯수만큼 0이라는 의미지요.
numpy로 처리하면, 이 없는 값들을 0으로 간주함으로써 불필요한 메모리를 소모하게 됩니다.
다음으로 시도한 방법은 sparse matrix를 사용하는 것이었습니다. 여기에 자세한 내용이 있습니다. 얼른 말해, sparse matrix는 이런 불필요한 0을 채워넣지 않아 메모리를 절약할 수 있습니다. 그러나 지원되는 행렬연산이 그렇게 포괄적이지 않았지요.
결과적으로 이 방식은 유효했습니다. 더 자세한 내용을 차차 정리하려 합니다.
전이 행렬을 사용하고, 이를 dictionary 형태로 변환하여 O(1) 탐색 복잡도를 갖도록 유도했습니다. 각 key는 노드가 되고, value는 인접 노드와 그 연관 확률의 다른 dictionary가 되는 셈이지요. 이로써, random walk 생성이 더 쉬워지고 효율적이게 됐습니다. 인접 노드는 전이 weight에 의해 random.choice를 적용함으로써 정해집니다.
이 방법은 networkx 그래프를 순회하는 것보다 수 자릿수배는 빠릅니다. 주목할 점은, 이 방법은 여전히 graph를 순회하기는 한다는 것이지요.
구현 3: Node2Vec / Implementation 3: Node2Vec
(구현 3이라구요? 1이랑 2는 어딨죠?! - 여길 보세요.)
고통스럽게 그래프와 시퀀스를 직접 구현하고 나서야, 깃헙에서 Node2Vec(“n2v”)이라는 레포지터리를 찾았습니다. (스스로에 대한 메모: 뭘 하기 전에 구글링부터 해볼것.)
n2v는 아주 매력적었죠. 우리가 원하는 바로 그 형태였습니다. 단순히 egde만 제공하면, 그래프와 시퀀스를 생성해주고, 노드 임베딩을 학습합니다. 그 안을 들여다보면, networkx와 gensim을 사용하죠.
불행히도 이 구현체는 메모리 소모가 크고 느렸으며, 64Gb짜리 인스턴스에서도 끝까지 작동하지 못했습니다.
더 깊이 파보니, 그래프를 순회함으로써 시퀀스를 생성함을 알게 되었습니다. networkx를 다중 스레드를 사용하도록 하면, 여러 프로세스를 생성해 시퀀스를 만들 것이고, 이들을 메모리 내에 일시적으로 캐시해 놓게 됩니다. 짧게 말해, 메모리를 아주 많이 잡아먹는 방식이었죠. 전반적으로, 제 데이터셋에 맞지 않은 방식이었습니다.
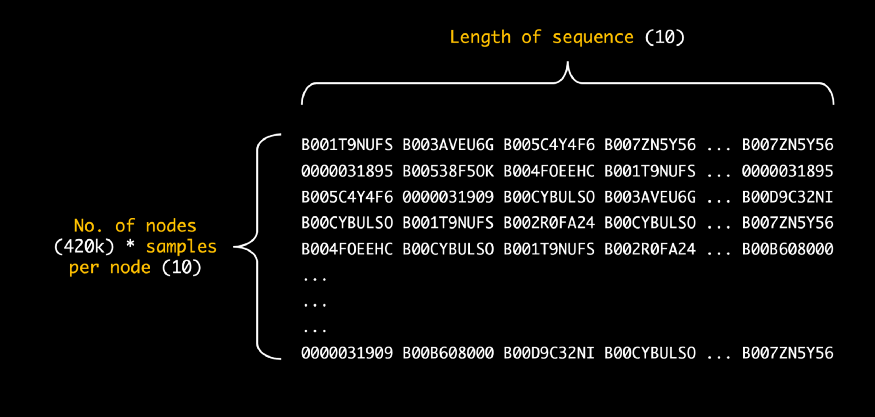
포스트의 남은 부분동안, 생성된 시퀀스에 기반한 상품 임베딩의 학습에 대해 배워볼 것입니다. 이 시퀀스들은 넘파이 배열 객체 형태입니다. (즉, 상품 ID) 차원은 N*M이며, N은 개별 상품의 수 * 10, Y(? 아마 M을 오기한 것으로 보입니다 - 옮긴이)는 시퀀스별 노드의 수를 의미합니다.
아래는 생성한 시퀀스를 보여줍니다.
구현 4: gensim.word2vec / Implementation 4: gensim.word2vec
Gensim은 시퀀스의 리스트를 받아들이는 w2v 구현을 제공합니다. 또한, 멀티 쓰레드를 지원하지요. 사용하기도 매우 간편했고, 5 에폭 학습을 마치는 데 가장 빨랐습니다.
이는 matrix factorization보다 훨씬 성능이 좋았습니다. AUC-ROC 0.9082 달성했죠.
그러나, precision recall 곡선을 보면, 0.73에서 급격한 하락이 있음을 볼 수 있었습니다. 왜 그럴까요?
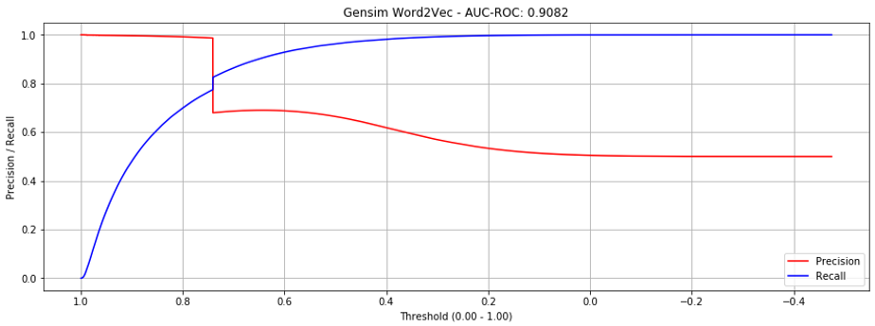
이유는, 임베딩이 없는 validation set에서의 “unseen” 상품 때문입니다. (즉, 학습 셋에 등장하지 않은 상품)
Gensim.w2v 은 학습셋 내부에 존재하지 않는 단어에 대해 임베딩을 생성하거나 초기화할 수 없습니다. 이를 보정하기 위해, train set에도 존재하지 않는 validation set의 상품 pair에 대해 예측 점수를 중위 유사도 점수(median similarity score)로 놓았습니다. 바로 이 unseen 상품들이 성능 절벽을 만들었네요.
트레인 셋에 등장하는 상품 pair로 validation set을 구성하면, 성능이 유의미하게 개선되었습니다. AUC-ROC 0.9735였고, 성능 절벽이 없었죠.
학습에 얼마나 걸렸게요? 12개 쓰레드를 사용해 2.58분이 걸렸습니다. 이는 새로운 베이스라인이죠. 3분 내로 멋진 성능을 얻었습니다. 프로젝트 완료! 맞나요?
음, 끝이 아닙니다. 이 예제의 의도는 새로운 접근을 시도해 보는 것이죠. 저는 뭔가 w2v에 대해 완전히 이해한 것 같지 않은 느낌이었습니다. 게다가, gensim으로는, 배치와 에폭마다의 학습 curve를 그릴 수 없었습니다.
또, 제겐 추천시스템에 w2v을 확장하는 것에 대한 몇몇 아이디어가 있었고, 기본적인 gensim 구현은 이런 확장을 지원하지 않았습니다.
그래서, pytorch로 밑단부터 구현해 보기로 했죠.
구현 5: PyTorch word2vec / Implementation 5: PyTorch word2vec
파이토치 모델을 학습하는 데에는 두개의 핵심 컴포넌트가 있습니다. 바로 dataloader와 model이죠. 저는 좀 더 지루한, 데이터로더로부터 시작하려 합니다.
데이터로더는 이전의 구현체와 크게 비슷합니다. (matrix factorization에서 사용한 것 말이죠) 그러나 몇가지 핵심적인 차이가 있습니다. 첫째로, product pair를 사용하는 것이 아니라, 시퀀스를 받는다는 점이죠.
나아가, 두가지 새로운 피처가 있습니다. (즉, 빈출 단어의 서브샘플링(subsampling)과 네거티브 샘플링(negative sampling)) 이 둘은 2번째 w2v 논문에서 제안되었죠.
빈출 단어의 서브샘플링 subsampling of frequent words
이 논문에서, 빈출 단어의 서브샘플링 (즉, 상대적으로 빈번히 등장하는 단어를 제거하는 것)은 학습을 가속하고 희귀한 단어의 벡터를 학습하는 작업을 크게 개선하기 위해 제안되었습니다. 이는 굉장히 직관적인 방법이죠. (아주 훌륭한 설명이 여기에 있습니다.)
네거티브 샘플링 negative sampling
네거티브 샘플링은 더 까다롭습니다. 잘 따라와 주세요.
본래의 skip-gram은 (hierarchical) softmax 층을 마지막에 가지고 있습니다. 중심 단어의 이웃에 있는 모든 어휘 단어의 확률을 예측하죠.
가령 1만 개의 단어(혹은 상품)가 있다면, 1만 개의 유닛을 가진 소프트맥스 레이어가 됩니다. 128차원의 임베딩 벡터를 사용하면, 128만개의 가중치를 업데이트 해야합. 상당한 연산이죠. 추천시스템에서는 더 문제가 두드러지는데요, 상품의 “단어집”은 수백만이 될 수 있기 때문이죠.
네거티브 샘플링은 일부분의 가중치만을 수정합니다. 특히, positive한 상품 pair와 작은 표본의 negative 상품 pair를 사용합니다. 논문에 의하면, 5개의 negative 상품 pair 정도도 충분하다고 하네요.
만일 5개의 nagative 상품 pair를 사용하면, 오직 6개의 output 뉴런만 사용해도 된다는 것이죠(즉 1개의 positive, 5개의 negative 상품 pair). 이는 100만개의 상품이 있을 때 0.0006% 수준으로 줄어든다는 말입니다. 아주 효율적이네요!
(Note: 네거티브 샘플링이 이전 포스트의 MF 접근에서도 사용되었음을 눈치 채셨을 것 같네요. 학습시 매 상품 pair마다 5개의 네거티브 상품 pair가 생성되었었죠.)
어떻게 이 negative sample이 결정될까요?
논문에 따르면, 더 빈번한 단어들이 negative sample로 선택될 가능성이 높은, unigram 분포를 사용해 선택됩니다. 한가지 특이한 트릭은 단어의 count를 3/4 제곱을 취해주는 것인데, 연구진 주장에 따르면 가장 성능이 좋다고 하네요. 이 구현에서도 똑같이 적용하려 합니다.
스킵그램 모델 skipgram model
모델에는, pytorch w2v은 아주 직관적으로 20줄 이하의 코드로 짜여 있으니, 디테일하게 설명하지 않으려 합니다. 그럼에도 불구하고, skipgram 모델 클래스의 단순화된 코드를 아래 소개합니다.
class SkipGram(nn.Module):
def __init__(self, emb_size, emb_dim):
self.center_embeddings = nn.Embedding(emb_size, emb_dim, sparse=True)
self.context_embeddings = nn.Embedding(emb_size, emb_dim, sparse=True)
def forward(self, center, context, neg_context):
emb_center, emb_context, emb_neg_context = self.get_embeddings()
# Get score for positive pairs
score = torch.sum(emb_center * emb_context, dim=1)
score = -F.logsigmoid(score)
# Get score for negative pairs
neg_score = torch.bmm(emb_neg_context, emb_center.unsqueeze(2)).squeeze()
neg_score = -torch.sum(F.logsigmoid(-neg_score), dim=1)
# Return combined score
return torch.mean(score + neg_score)
자, MF와 비교해서 성능이 어떨까요?
이 방식은 전체 상품 대비 AUC-ROC 0.9554 수준으로 상당히 높은 점수를 보입니다.(그림.4, gensim보다 훨씬 낫네요.) 오직 ‘seen’ 상품에 대해서만 고려한다면, 0.9855를 기록하지요. (그림.5, gensim보다 약간 낫네요.)
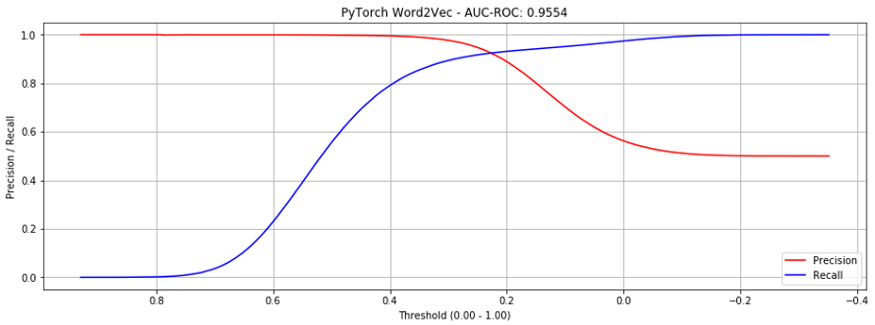
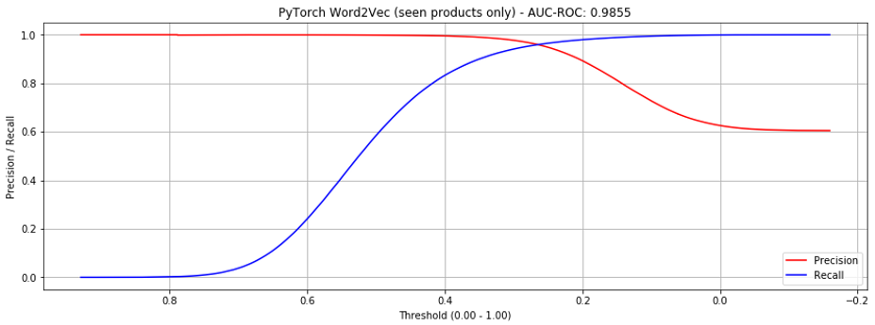
이 결과는 비슷한 접근을 취한 알리바바 논문에 비해서도 높으며, 아마존 electronics 데이터셋에서도 그렇습니다. 논문에서는 0.9327의 AUC-ROC를 보이고 있습니다.
학습 곡선을 살펴보면, 단지 1 에폭이면 충분해 보입니다. 눈에 띄는 현상은 매 에폭마다 매번 학습률이 새로 갱신된다는 것입니다. AUC-ROC는 MF에서 그랬던 것과는 달리 급격히 떨어지지는 않네요.
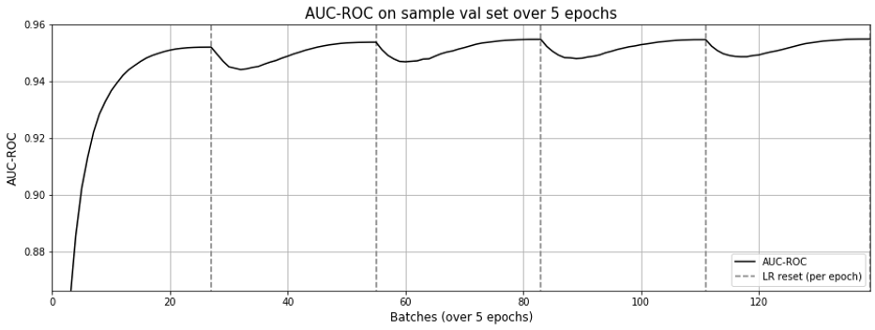
전반적으로 훌륭한 결과입니다. gensim.word2vec을 복제해 낼 수 있으며, 심지어 성능이 더 좋네요.
나아가, 모든 제품에 대해 임베딩을 초기화할 수 있습니다. 트레인 셋에 없는 상품에 대해서도요. 이 임베딩이 학습되지 않았을지라도, 새로운 데이터와 함께 업데이트 될 것입니다.(처음부터 다시 학습할 필요 없이요)
한가지 단점은 gensim 구현체와는 달리 훨씬 느리다는 것입니다. (23.63분이 걸렸습니다.) 아마 제가 최적화하지 못한 까닭이겠죠 ㅠㅠ (어떻게 개선할지 제안해 주세요!)
구현 6: 주변 정보를 활용한 PyTorch word2vec / Implementation 6: PyTorch word2vec with side info
w2v를 밑단부터 구현한 이유는 주변 정보를 추가하여 확장 하기 위함이었습니다. 시퀀스 내의 각 상품에 대해, 브랜드/카테고리/가격 등의 중요한 주변 정보를 가지고 있습니다. 이들을 임베딩 학습에 추가하여 학습해 봅시다.
B001T9NUFS -> B003AVEU6G -> B007ZN5Y56 ... -> B007ZN5Y56
Television Sound bar Lamp Standing Fan
Sony Sony Phillips Dyson
500 – 600 200 – 300 50 – 75 300 - 400
구현 관점에서 보면, 한 상품마다 하나의 임베딩이 아니라, 상품ID, 브랜드,카테고리 등의 다양한 임베딩을 가지게 되었습니다. 이 임베딩을 하나의 임베딩으로 통합할 수 있습니다.
이는 잠재적으로 cold-start 문제를 해결할 수 있습니다. 이는 알리바바의 논문에서도 제안되었는데, 연구진은 브랜드/카테고리 레벨1/카테고리 레벨2에 대한 주변정보를 사용하였습니다. 비슷한 형태의 electronics 데이터셋에 대해, AUC-ROC상의 개선(주변 정보로 인한)을 이루어 냈다고 합니다. 0.9327에서 0.9575로 올랐다고 하네요.
저는 2개의 버전을 구현했습니다. 첫번째로는 임베딩의 균일 가중치 평균화(equal-weighted averaging)였고, 두번째로는 각 임베딩에 대한 가중치 할당을 학습하여 가중 평균을 적용해 단일 임베딩으로 통합하는 것이었습니다.
둘 다 잘 안됐습니다. 학습중의 AUC-ROC는 0.4~0.5 언저리까지 떨어졌습니다. (그림 7을 보세요.)
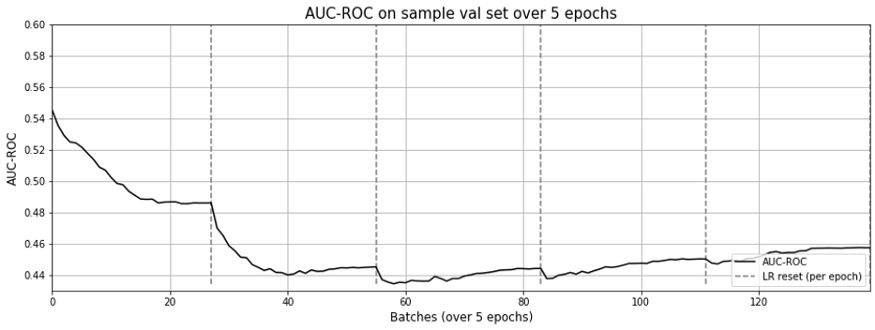
제 구현이 옳았다는 것을 확실히 하기 위해 상당한 시간을 들인 뒤, 포기했습니다. 주변 정보 없이 해본 결과, 구현 5와 동일한 성적 을 얻었습니다. 그런데도 더 느렸습니다.
결과가 잘 안나오는 가능한 이유 중 하나는, 메타정보의 sparsity 때문입니다. 418,749개 전자제품 중, 162,023(39%)개만이 메타데이터를 가지고 있었습니다. 그 중에서도 브랜드의 51%는 비어 있었죠.
그럼에도 불구하고, 제 가정은 임베딩의 가중치 할당이, 특히, (덜 유용한) 메타 임베딩의 경우 학습될 수 있다는 것이었습니다. 그러므로, 통합된 결과에서의 그들의 가중치는 감소될 것이고(혹은 최소화되거나) 메타데이터를 추가하는 것이 모델 성능을 손상시키지 않았어야 한다는 것입니다. 그런데 이번에는 말이 안되네요.
대체로, w2v를 주변 정보와 적용하는 것이 잘 작동하지 않았습니다. ¯(ツ)/¯
구현 7: 시퀀스 + MF / Implementation 7: Sequences + Matrix Factorization
왜 w2v 접근이 MF보다 훨씬 나았을까요? skipgram 모델 때문일까요, 혹은 학습 데이터 형식(시퀀스) 때문이었을까요?
이를 더 잘 이해하기 위해, 이전의 bias implementation MF (AUC-ROC = 0.7951)를 새로운 시퀀스와 데이터로더로 시도해보았습니다.
와, 놀랍게도 0.9320까지 올라갔습니다!(그림 8)
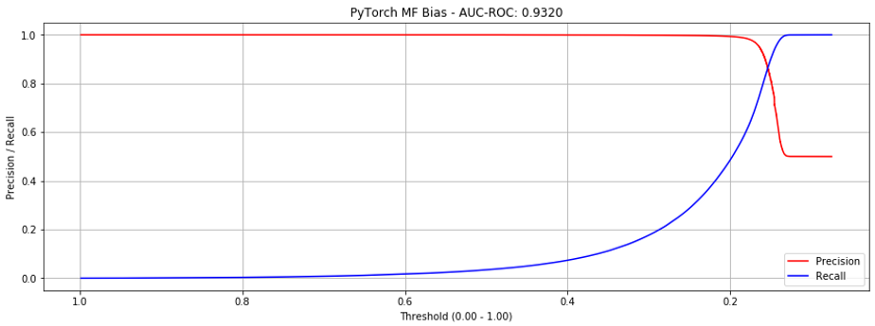
이 결과는, “graph-random-walk-sequence” 접근이 잘 작동한다는 것을 보여줍니다.
또 다른 이유가 될 수 있는 것 중 하나는 원래의 MF에서는, 상품 pair에 기반한 임베딩만을 배웠다는 것입니다. 시퀀스를 사용하면, 5의 window 사이즈를 사용했는데, 따라서 학습할 데이터가 5배 더 많아진 셈입니다. 시퀀스 내의 멀리 떨어진 상품은 덜 강하게 연관되어 있을 것입니다.
헌데 이상하게도, MF 접근법은 각 에폭마다 (그림 9) 학습률이 갱신됨에 따라 “망각” 효과를 여전히 보여주고 있었습니다.
저는 center와 맥락 둘 모두에 대해 같은 임베딩을 사용했기 떄문이 아닐까 하고 생각했습니다.
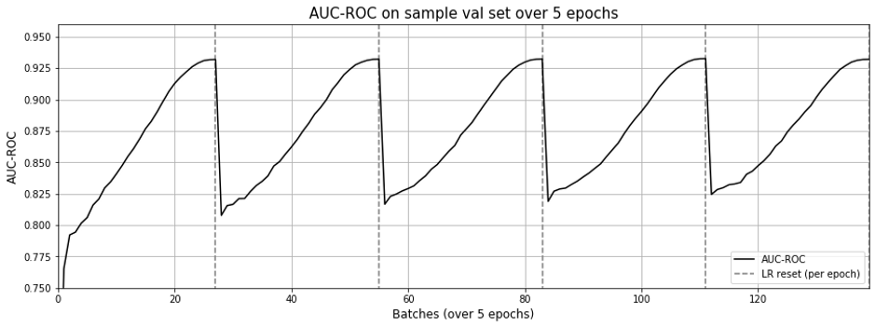
또다른 단점은 약 3배에 달하는 시간이 소요된다는 점이었는데, 23.63분이 걸렸던 w2v 구현에서 70.39분이 걸릴 정도로 지연되었습니다 (MF 구현).
더 큰 데이터셋에 대한 결과 (books) / Additional results on a bigger dataset (books)
같은 방식으로, books 데이터셋을 준비했습니다. 이는 2백만의 개별적인 상품이 존재하고, 2650만의 상품 pair를 포함하고 있습니다. 이 데이터에 구현을 해봤습니다.
몇몇 주목할만한 결과는 다음과 같습니다.
Matrix Factorization:
- 전반적인 AUC-ROC: 0.4996 (학습이 왜 안되는지 모르겠음)
- 5 에폭 학습에 소요된 시간: 1353.12분
Gensim Word2vec:
- 전반적인 AUC-ROC: 0.9701
- ‘Seen’ 상품에 대한 AUC-ROC: 0.9892
- 5 에폭 학습에 소요된 시간: 16.24 분
PyTorch Word2vec:
- 전반적인 AUC-ROC: 0.9775
- 5 에폭 학습에 소요된 시간: 122.66 분
PyTorch Matrix Factorization with Sequences
- 전반적인 AUC-ROC: 0.7196
- 5 에폭 학습에 소요된 시간: 1393.08 분
유사하게, 시퀀스를 MF에 적용한 것이 매우 큰 도움이 되었으나, 일반적인 word2vec 수준의 최상급 결과는 얻지 못했네요.
Further Extensions
이 두 블로그 포스트에서, 7개의 item-to-item 추천 시스템을 구현해 보았습니다. 아직 유저 정보는 고려하지도 않았죠. (탐험할 영역이 아주 넓네요~!)
유저 정보를 가지고 있다면, 유저 임베딩을 (상품 임베딩과) 같은 벡터 공간 에서 만들 수 있겠죠. 이는 유저 임베딩을 (i) 유저가 클릭한 상품(positive), (ii) 노출되었지만 클릭하지 않은 상품(negative), 그리고 (iii) 구매한 상품 (아주 강한 positive) 에 기반하여 학습함으로써 이룰 수 있겠습니다.
이 접근법은 Airbnb에 의해 채택되었고, 아주 유망해 보입니다. 하지만, 유저와 상품 데이터의 sparsity로 인해 (즉, 대다수의 유저와 숙박시설이 아주 적은 예약 내역을 가지고 있음), 유저와 숙박시설을 유저/숙박시설 타입으로 통합했습니다. 이는 각 타입에 대해 충분한 샘플의 양을 보장했죠.
유저와 상품 임베딩에서 멈출 필요가 있나요? 이 예제에서, 적절한 학습 데이터를 사용하면 임베딩이 얼마나 강력해질 수 있는지 확인했습니다. StarSpace 논문에서, 페이스북은 이 방법을 극단으로 끌고갔고, 모든 것을 임베딩할 것을 제안했습니다.
최근, 우버 이츠는 유저와 메뉴 상품의 임베딩을 학습하기 위해 GNN을 적용한 방법에 대해 공유했습니다. 노드 임베딩이 이웃에 기반해 있죠. 더 보시려면 여기
가져가실 것들 / Key Takeaways
w2v을 사용해 상품 임베딩을 생성한 방법은 아주 강력한 baseline이며, 아주 가볍게 기본적인 MF 접근법을 이겼습니다.
만일 시퀀스를 준비했다면, 단순히 gensim 구현체를 사용할 수 있습니다. 만일 w2v을 확장해서 자신만의 구현체가 필요하다면, 개발하는 것은 그리 어렵지 않습니다.
PyTorch w2v 구현체가 gensim을 이겼다는 것은 아주 멋진 일입니다. 또, 알리바바의 논문 결과를 이겼죠. 슬프게도, 주변 정보를 사용한 개선을 재현할 수는 없었습니다. 아마 메타 데이터가 sparse하지 않은 데이터셋에 대해 다시 실험을 해 확인을 해 보아야겠습니다.
마지막으로, 시퀀스 형태로 들어간 학습 데이터는 레전드였습니다. 시퀀스를 사용한 MF는 기존의 상품 pair를 사용한 MF보다 훨씬 성능이 좋았죠. 시퀀스는 다양한 신박한 접근법으로 만들어낼 수 있습니다. 이 포스트에서는, 상품 그래프를 만들고 random walk를 수행해 이 sequence를 만들어 냈죠.
결론 Conclusion
시퀀스에 대한 저의 관심을 추천 시스템과 같은, 시퀀스가 덜 자주 사용되는 머신러닝 분야에 실제로 적용해 보는 것은 아주 흥미로운 일이었습니다.
여기서 공유된 학습과 코드가 추천 시스템 구현체를 개발하는 사람들에게 유익했으면 좋겠네요. 일에서든, 재미로 하든 말이죠.
개선을 위한 여러분의 피드백과 제안을 코멘트로 공유해 주세요.
원문 : https://towardsdatascience.com/recommender-systems-applying-graph-and-nlp-techniques-619dbedd9ecc
옮긴이의 마침말
아주 재밌네요! 제 데이터 셋에도 적용해 봐야겠습니다.
내용에 대한 질문/지적, 오역 등 제보 환영합니다!
Leave a comment